 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Adaptive Covariance Estimation via Gaussian Graphical Models
May 22, 2026We propose PACE-GGM, a data-adaptive differentially private method for covariance estimation that concentrates its privacy budget on the most informative entries of the empirical covariance matrix, rather than perturbing all entries. This applies in the natural setting where the modeler supplies separate bounds for each variable, so that individual entries can be measured with less noise than the full matrix. In each round, our method selects a poorly approximated entry, measures it using the Gaussian mechanism, and then reconstructs a full covariance matrix using a maximum-entropy reconstruction objective, leading to a Gaussian graphical model structure. Experiments on diverse real-world datasets demonstrate consistent improvements in estimation error with respect to the Gaussian mechanism and other baselines, particularly in high-dimensional and low-to-moderate privacy regimes.
Active Measurement of Two-Point Correlations
Apr 06, 2026Two-point correlation functions (2PCF) are widely used to characterize how points cluster in space. In this work, we study the problem of measuring the 2PCF over a large set of points, restricted to a subset satisfying a property of interest. An example comes from astronomy, where scientists measure the 2PCF of star clusters, which make up only a tiny subset of possible sources within a galaxy. This task typically requires careful labeling of sources to construct catalogs, which is time-consuming. We present a human-in-the-loop framework for efficient estimation of 2PCF of target sources. By leveraging a pre-trained classifier to guide sampling, our approach adaptively selects the most informative points for human annotation. After each annotation, it produces unbiased estimates of pair counts across multiple distance bins simultaneously. Compared to simple Monte Carlo approaches, our method achieves substantially lower variance while significantly reducing annotation effort. We introduce a novel unbiased estimator, sampling strategy, and confidence interval construction that together enable scalable and statistically grounded measurement of two-point correlations in astronomy datasets.
Consensus-Driven Active Model Selection
Jul 31, 2025The widespread availability of off-the-shelf machine learning models poses a challenge: which model, of the many available candidates, should be chosen for a given data analysis task? This question of model selection is traditionally answered by collecting and annotating a validation dataset -- a costly and time-intensive process. We propose a method for active model selection, using predictions from candidate models to prioritize the labeling of test data points that efficiently differentiate the best candidate. Our method, CODA, performs consensus-driven active model selection by modeling relationships between classifiers, categories, and data points within a probabilistic framework. The framework uses the consensus and disagreement between models in the candidate pool to guide the label acquisition process, and Bayesian inference to update beliefs about which model is best as more information is collected. We validate our approach by curating a collection of 26 benchmark tasks capturing a range of model selection scenarios. CODA outperforms existing methods for active model selection significantly, reducing the annotation effort required to discover the best model by upwards of 70% compared to the previous state-of-the-art. Code and data are available at https://github.com/justinkay/coda.
Active Measurement: Efficient Estimation at Scale
Jul 02, 2025AI has the potential to transform scientific discovery by analyzing vast datasets with little human effort. However, current workflows often do not provide the accuracy or statistical guarantees that are needed. We introduce active measurement, a human-in-the-loop AI framework for scientific measurement. An AI model is used to predict measurements for individual units, which are then sampled for human labeling using importance sampling. With each new set of human labels, the AI model is improved and an unbiased Monte Carlo estimate of the total measurement is refined. Active measurement can provide precise estimates even with an imperfect AI model, and requires little human effort when the AI model is very accurate. We derive novel estimators, weighting schemes, and confidence intervals, and show that active measurement reduces estimation error compared to alternatives in several measurement tasks.
Hamiltonian Monte Carlo Inference of Marginalized Linear Mixed-Effects Models
Oct 31, 2024
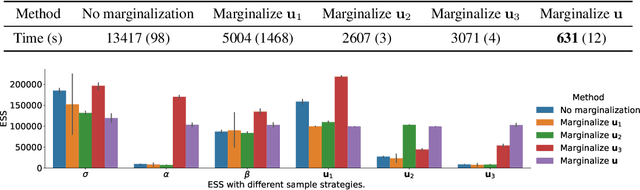
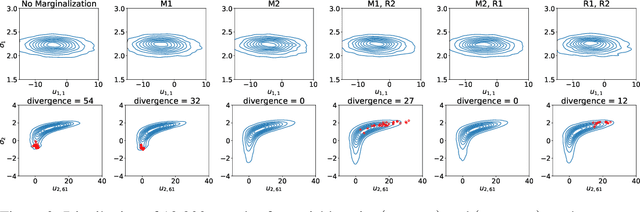

Bayesian reasoning in linear mixed-effects models (LMMs) is challenging and often requires advanced sampling techniques like Markov chain Monte Carlo (MCMC). A common approach is to write the model in a probabilistic programming language and then sample via Hamiltonian Monte Carlo (HMC). However, there are many ways a user can transform a model that make inference more or less efficient. In particular, marginalizing some variables can greatly improve inference but is difficult for users to do manually. We develop an algorithm to easily marginalize random effects in LMMs. A naive approach introduces cubic time operations within an inference algorithm like HMC, but we reduce the running time to linear using fast linear algebra techniques. We show that marginalization is always beneficial when applicable and highlight improvements in various models, especially ones from cognitive sciences.
Efficient and Private Marginal Reconstruction with Local Non-Negativity
Oct 01, 2024
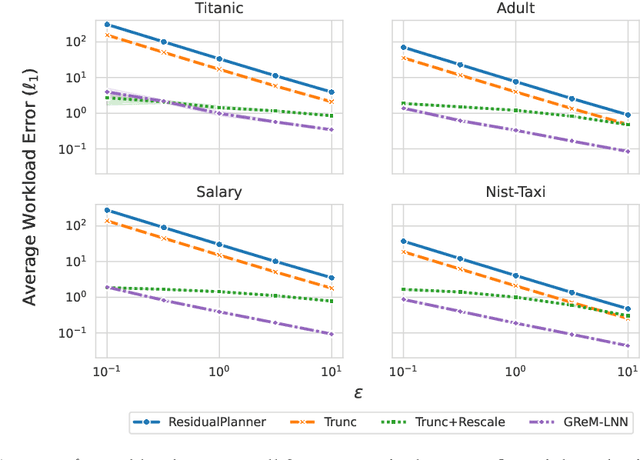
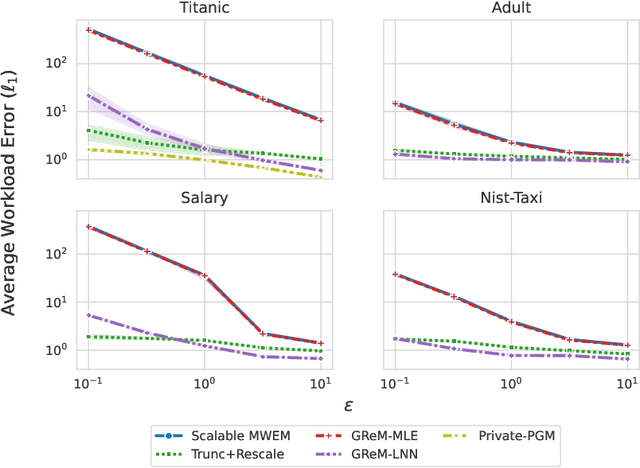
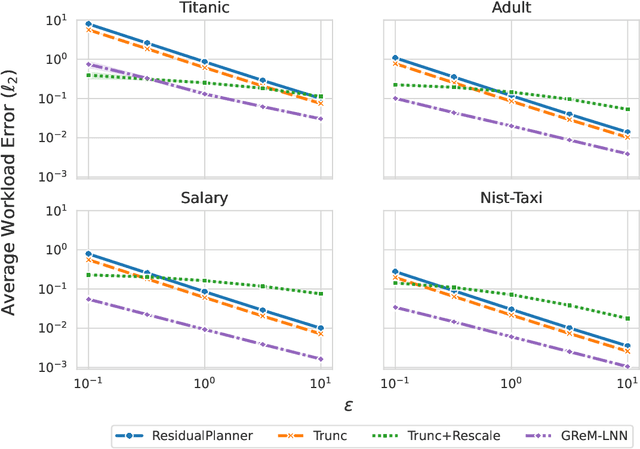
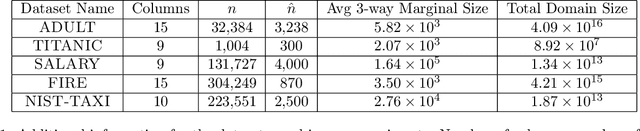
Differential privacy is the dominant standard for formal and quantifiable privacy and has been used in major deployments that impact millions of people. Many differentially private algorithms for query release and synthetic data contain steps that reconstruct answers to queries from answers to other queries measured by the mechanism. Reconstruction is an important subproblem for such mechanisms to economize the privacy budget, minimize error on reconstructed answers, and allow for scalability to high-dimensional datasets. In this paper, we introduce a principled and efficient postprocessing method ReM (Residuals-to-Marginals) for reconstructing answers to marginal queries. Our method builds on recent work on efficient mechanisms for marginal query release, based on making measurements using a residual query basis that admits efficient pseudoinversion, which is an important primitive used in reconstruction. An extension GReM-LNN (Gaussian Residuals-to-Marginals with Local Non-negativity) reconstructs marginals under Gaussian noise satisfying consistency and non-negativity, which often reduces error on reconstructed answers. We demonstrate the utility of ReM and GReM-LNN by applying them to improve existing private query answering mechanisms: ResidualPlanner and MWEM.
Private Regression via Data-Dependent Sufficient Statistic Perturbation
May 23, 2024



Sufficient statistic perturbation (SSP) is a widely used method for differentially private linear regression. SSP adopts a data-independent approach where privacy noise from a simple distribution is added to sufficient statistics. However, sufficient statistics can often be expressed as linear queries and better approximated by data-dependent mechanisms. In this paper we introduce data-dependent SSP for linear regression based on post-processing privately released marginals, and find that it outperforms state-of-the-art data-independent SSP. We extend this result to logistic regression by developing an approximate objective that can be expressed in terms of sufficient statistics, resulting in a novel and highly competitive SSP approach for logistic regression. We also make a connection to synthetic data for machine learning: for models with sufficient statistics, training on synthetic data corresponds to data-dependent SSP, with the overall utility determined by how well the mechanism answers these linear queries.
Joint Selection: Adaptively Incorporating Public Information for Private Synthetic Data
Mar 12, 2024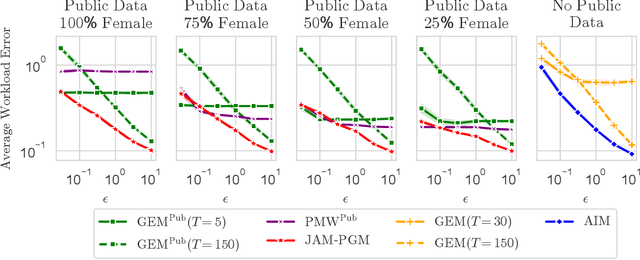
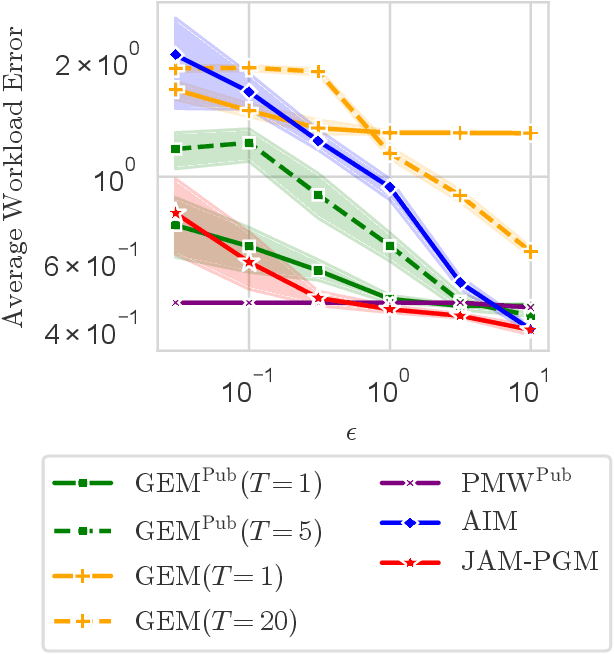
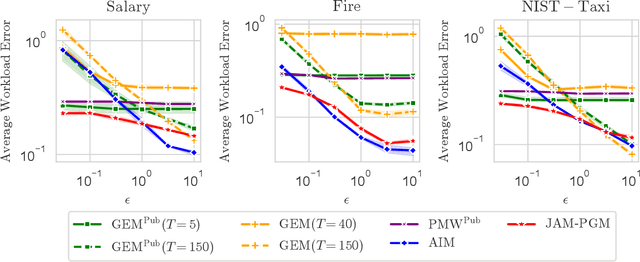
Mechanisms for generating differentially private synthetic data based on marginals and graphical models have been successful in a wide range of settings. However, one limitation of these methods is their inability to incorporate public data. Initializing a data generating model by pre-training on public data has shown to improve the quality of synthetic data, but this technique is not applicable when model structure is not determined a priori. We develop the mechanism jam-pgm, which expands the adaptive measurements framework to jointly select between measuring public data and private data. This technique allows for public data to be included in a graphical-model-based mechanism. We show that jam-pgm is able to outperform both publicly assisted and non publicly assisted synthetic data generation mechanisms even when the public data distribution is biased.
Human in-the-Loop Estimation of Cluster Count in Datasets via Similarity-Driven Nested Importance Sampling
Dec 08, 2023Identifying the number of clusters serves as a preliminary goal for many data analysis tasks. A common approach to this problem is to vary the number of clusters in a clustering algorithm (e.g., 'k' in $k$-means) and pick the value that best explains the data. However, the count estimates can be unreliable especially when the image similarity is poor. Human feedback on the pairwise similarity can be used to improve the clustering, but existing approaches do not guarantee accurate count estimates. We propose an approach to produce estimates of the cluster counts in a large dataset given an approximate pairwise similarity. Our framework samples edges guided by the pairwise similarity, and we collect human feedback to construct a statistical estimate of the cluster count. On the technical front we have developed a nested importance sampling approach that yields (asymptotically) unbiased estimates of the cluster count with confidence intervals which can guide human effort. Compared to naive sampling, our similarity-driven sampling produces more accurate estimates of counts and tighter confidence intervals. We evaluate our method on a benchmark of six fine-grained image classification datasets achieving low error rates on the estimated number of clusters with significantly less human labeling effort compared to baselines and alternative active clustering approaches.
DISCount: Counting in Large Image Collections with Detector-Based Importance Sampling
Jun 05, 2023



Many modern applications use computer vision to detect and count objects in massive image collections. However, when the detection task is very difficult or in the presence of domain shifts, the counts may be inaccurate even with significant investments in training data and model development. We propose DISCount -- a detector-based importance sampling framework for counting in large image collections that integrates an imperfect detector with human-in-the-loop screening to produce unbiased estimates of counts. We propose techniques for solving counting problems over multiple spatial or temporal regions using a small number of screened samples and estimate confidence intervals. This enables end-users to stop screening when estimates are sufficiently accurate, which is often the goal in a scientific study. On the technical side we develop variance reduction techniques based on control variates and prove the (conditional) unbiasedness of the estimators. DISCount leads to a 9-12x reduction in the labeling costs over naive screening for tasks we consider, such as counting birds in radar imagery or estimating damaged buildings in satellite imagery, and also surpasses alternative covariate-based screening approaches in efficiency.