 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Adaptive Covariance Estimation via Gaussian Graphical Models
May 22, 2026We propose PACE-GGM, a data-adaptive differentially private method for covariance estimation that concentrates its privacy budget on the most informative entries of the empirical covariance matrix, rather than perturbing all entries. This applies in the natural setting where the modeler supplies separate bounds for each variable, so that individual entries can be measured with less noise than the full matrix. In each round, our method selects a poorly approximated entry, measures it using the Gaussian mechanism, and then reconstructs a full covariance matrix using a maximum-entropy reconstruction objective, leading to a Gaussian graphical model structure. Experiments on diverse real-world datasets demonstrate consistent improvements in estimation error with respect to the Gaussian mechanism and other baselines, particularly in high-dimensional and low-to-moderate privacy regimes.
Efficient and Private Marginal Reconstruction with Local Non-Negativity
Oct 01, 2024
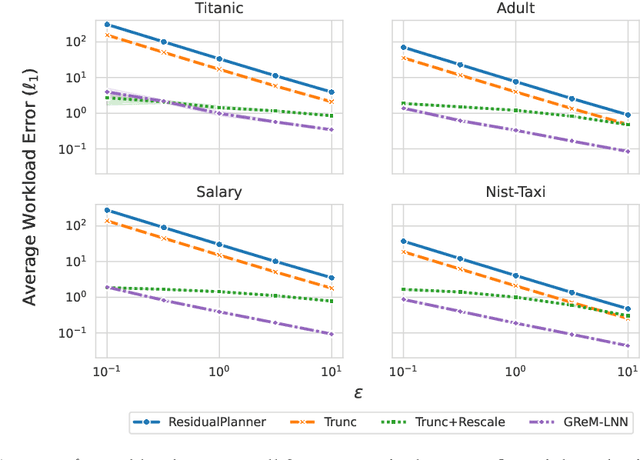
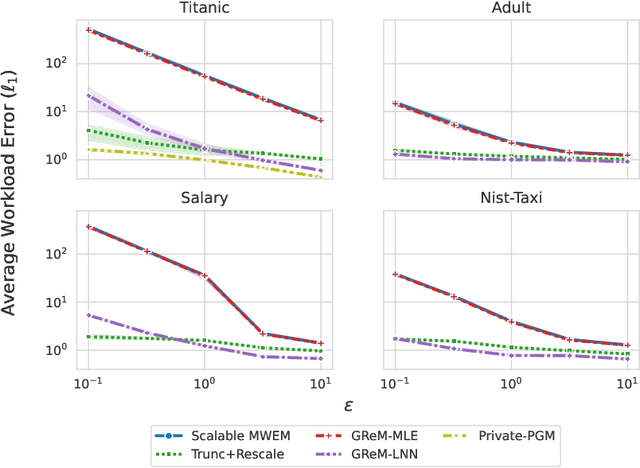
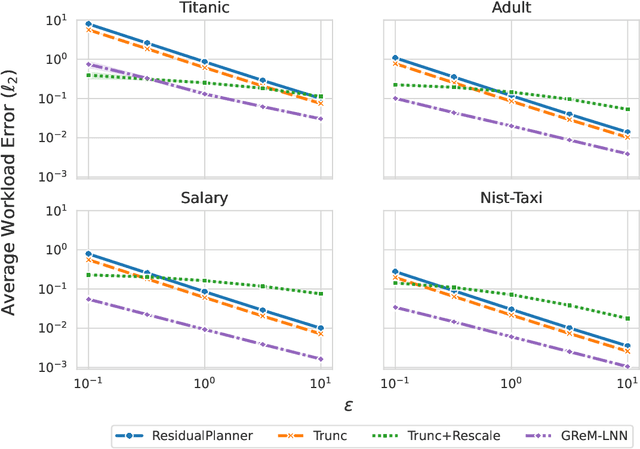
Differential privacy is the dominant standard for formal and quantifiable privacy and has been used in major deployments that impact millions of people. Many differentially private algorithms for query release and synthetic data contain steps that reconstruct answers to queries from answers to other queries measured by the mechanism. Reconstruction is an important subproblem for such mechanisms to economize the privacy budget, minimize error on reconstructed answers, and allow for scalability to high-dimensional datasets. In this paper, we introduce a principled and efficient postprocessing method ReM (Residuals-to-Marginals) for reconstructing answers to marginal queries. Our method builds on recent work on efficient mechanisms for marginal query release, based on making measurements using a residual query basis that admits efficient pseudoinversion, which is an important primitive used in reconstruction. An extension GReM-LNN (Gaussian Residuals-to-Marginals with Local Non-negativity) reconstructs marginals under Gaussian noise satisfying consistency and non-negativity, which often reduces error on reconstructed answers. We demonstrate the utility of ReM and GReM-LNN by applying them to improve existing private query answering mechanisms: ResidualPlanner and MWEM.
Joint Selection: Adaptively Incorporating Public Information for Private Synthetic Data
Mar 12, 2024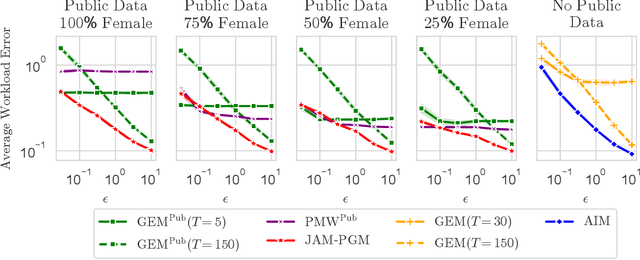
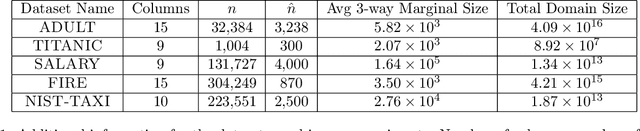
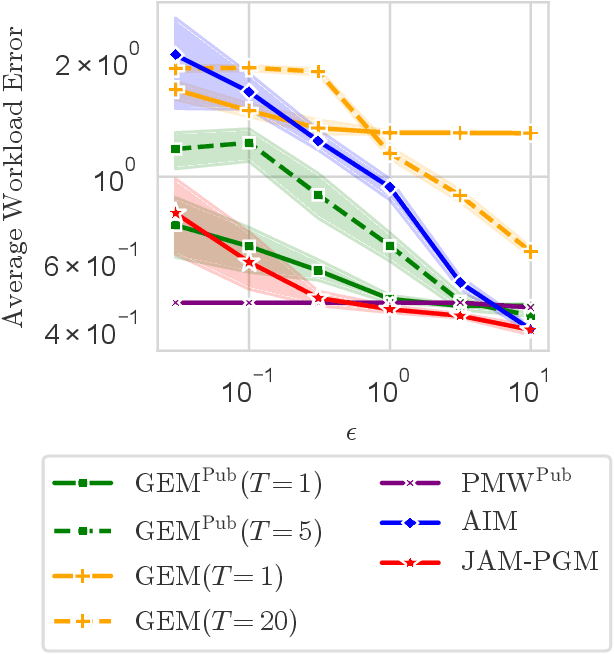
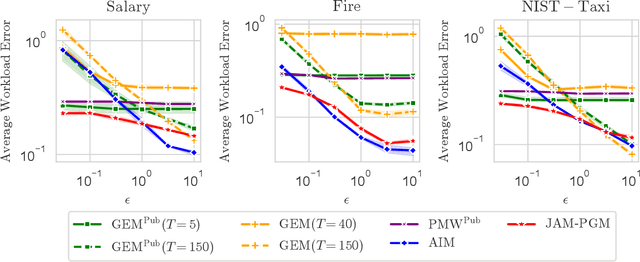
Mechanisms for generating differentially private synthetic data based on marginals and graphical models have been successful in a wide range of settings. However, one limitation of these methods is their inability to incorporate public data. Initializing a data generating model by pre-training on public data has shown to improve the quality of synthetic data, but this technique is not applicable when model structure is not determined a priori. We develop the mechanism jam-pgm, which expands the adaptive measurements framework to jointly select between measuring public data and private data. This technique allows for public data to be included in a graphical-model-based mechanism. We show that jam-pgm is able to outperform both publicly assisted and non publicly assisted synthetic data generation mechanisms even when the public data distribution is biased.
The Shape of Explanations: A Topological Account of Rule-Based Explanations in Machine Learning
Jan 22, 2023Rule-based explanations provide simple reasons explaining the behavior of machine learning classifiers at given points in the feature space. Several recent methods (Anchors, LORE, etc.) purport to generate rule-based explanations for arbitrary or black-box classifiers. But what makes these methods work in general? We introduce a topological framework for rule-based explanation methods and provide a characterization of explainability in terms of the definability of a classifier relative to an explanation scheme. We employ this framework to consider various explanation schemes and argue that the preferred scheme depends on how much the user knows about the domain and the probability measure over the feature space.
Identifying the Most Explainable Classifier
Oct 22, 2019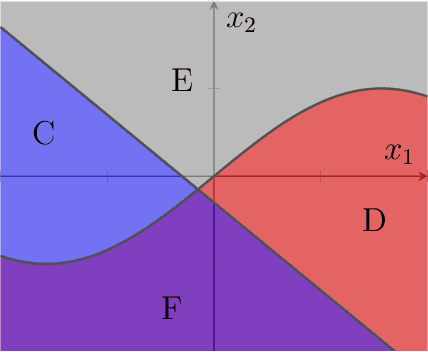
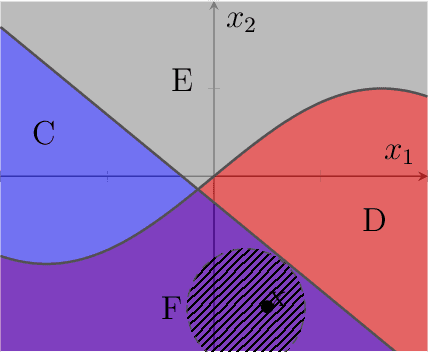
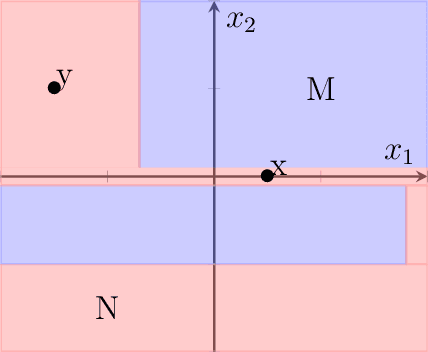
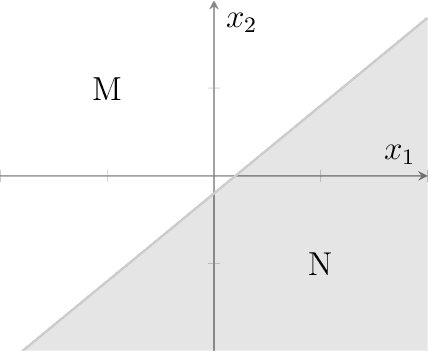
We introduce the notion of pointwise coverage to measure the explainability properties of machine learning classifiers. An explanation for a prediction is a definably simple region of the feature space sharing the same label as the prediction, and the coverage of an explanation measures its size or generalizability. With this notion of explanation, we investigate whether or not there is a natural characterization of the most explainable classifier. According with our intuitions, we prove that the binary linear classifier is uniquely the most explainable classifier up to negligible sets.