 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Scalable Matrix Mechanisms via Divide and Conquer
Apr 01, 2026Matrix mechanisms are often used to provide unbiased differentially private query answers when publishing statistics or creating synthetic data. Recent work has developed matrix mechanisms, such as ResidualPlanner and Weighted Fourier Factorizations, that scale to high dimensional datasets while providing optimality guarantees for workloads such as marginals and circular product queries. They operate by adding noise to a linearly independent set of queries that can compactly represent the desired workloads. In this paper, we present QuerySmasher, an alternative scalable approach based on a divide-and-conquer strategy. Given a workload that can be answered from various data marginals, QuerySmasher splits each query into sub-queries and re-assembles the pieces into mutually orthogonal sub-workloads. These sub-workloads represent small, low-dimensional problems that can be independently and optimally answered by existing low-dimensional matrix mechanisms. QuerySmasher then stitches these solutions together to answer queries in the original workload. We show that QuerySmasher subsumes prior work, like ResidualPlanner (RP), ResidualPlanner+ (RP+), and Weighted Fourier Factorizations (WFF). We prove that it can dominate those approaches, under sum squared error, for all workloads. We also experimentally demonstrate the scalability and accuracy of QuerySmasher.
Towards Better Optimization For Listwise Preference in Diffusion Models
Oct 02, 2025



Reinforcement learning from human feedback (RLHF) has proven effectiveness for aligning text-to-image (T2I) diffusion models with human preferences. Although Direct Preference Optimization (DPO) is widely adopted for its computational efficiency and avoidance of explicit reward modeling, its applications to diffusion models have primarily relied on pairwise preferences. The precise optimization of listwise preferences remains largely unaddressed. In practice, human feedback on image preferences often contains implicit ranked information, which conveys more precise human preferences than pairwise comparisons. In this work, we propose Diffusion-LPO, a simple and effective framework for Listwise Preference Optimization in diffusion models with listwise data. Given a caption, we aggregate user feedback into a ranked list of images and derive a listwise extension of the DPO objective under the Plackett-Luce model. Diffusion-LPO enforces consistency across the entire ranking by encouraging each sample to be preferred over all of its lower-ranked alternatives. We empirically demonstrate the effectiveness of Diffusion-LPO across various tasks, including text-to-image generation, image editing, and personalized preference alignment. Diffusion-LPO consistently outperforms pairwise DPO baselines on visual quality and preference alignment.
Sensitivity-Constrained Fourier Neural Operators for Forward and Inverse Problems in Parametric Differential Equations
May 14, 2025



Parametric differential equations of the form du/dt = f(u, x, t, p) are fundamental in science and engineering. While deep learning frameworks such as the Fourier Neural Operator (FNO) can efficiently approximate solutions, they struggle with inverse problems, sensitivity estimation (du/dp), and concept drift. We address these limitations by introducing a sensitivity-based regularization strategy, called Sensitivity-Constrained Fourier Neural Operators (SC-FNO). SC-FNO achieves high accuracy in predicting solution paths and consistently outperforms standard FNO and FNO with physics-informed regularization. It improves performance in parameter inversion tasks, scales to high-dimensional parameter spaces (tested with up to 82 parameters), and reduces both data and training requirements. These gains are achieved with a modest increase in training time (30% to 130% per epoch) and generalize across various types of differential equations and neural operators. Code and selected experiments are available at: https://github.com/AMBehroozi/SC_Neural_Operators
SAMIC: Segment Anything with In-Context Spatial Prompt Engineering
Dec 16, 2024Few-shot segmentation is the problem of learning to identify specific types of objects (e.g., airplanes) in images from a small set of labeled reference images. The current state of the art is driven by resource-intensive construction of models for every new domain-specific application. Such models must be trained on enormous labeled datasets of unrelated objects (e.g., cars, trains, animals) so that their ``knowledge'' can be transferred to new types of objects. In this paper, we show how to leverage existing vision foundation models (VFMs) to reduce the incremental cost of creating few-shot segmentation models for new domains. Specifically, we introduce SAMIC, a small network that learns how to prompt VFMs in order to segment new types of objects in domain-specific applications. SAMIC enables any task to be approached as a few-shot learning problem. At 2.6 million parameters, it is 94% smaller than the leading models (e.g., having ResNet 101 backbone with 45+ million parameters). Even using 1/5th of the training data provided by one-shot benchmarks, SAMIC is competitive with, or sets the state of the art, on a variety of few-shot and semantic segmentation datasets including COCO-$20^i$, Pascal-$5^i$, PerSeg, FSS-1000, and NWPU VHR-10.
Precision, Stability, and Generalization: A Comprehensive Assessment of RNNs learnability capability for Classifying Counter and Dyck Languages
Oct 04, 2024



This study investigates the learnability of Recurrent Neural Networks (RNNs) in classifying structured formal languages, focusing on counter and Dyck languages. Traditionally, both first-order (LSTM) and second-order (O2RNN) RNNs have been considered effective for such tasks, primarily based on their theoretical expressiveness within the Chomsky hierarchy. However, our research challenges this notion by demonstrating that RNNs primarily operate as state machines, where their linguistic capabilities are heavily influenced by the precision of their embeddings and the strategies used for sampling negative examples. Our experiments revealed that performance declines significantly as the structural similarity between positive and negative examples increases. Remarkably, even a basic single-layer classifier using RNN embeddings performed better than chance. To evaluate generalization, we trained models on strings up to a length of 40 and tested them on strings from lengths 41 to 500, using 10 unique seeds to ensure statistical robustness. Stability comparisons between LSTM and O2RNN models showed that O2RNNs generally offer greater stability across various scenarios. We further explore the impact of different initialization strategies revealing that our hypothesis is consistent with various RNNs. Overall, this research questions established beliefs about RNNs' computational capabilities, highlighting the importance of data structure and sampling techniques in assessing neural networks' potential for language classification tasks. It emphasizes that stronger constraints on expressivity are crucial for understanding true learnability, as mere expressivity does not capture the essence of learning.
Efficient and Private Marginal Reconstruction with Local Non-Negativity
Oct 01, 2024
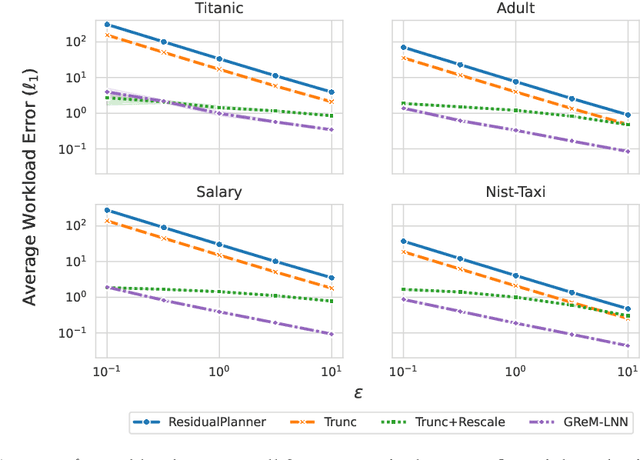
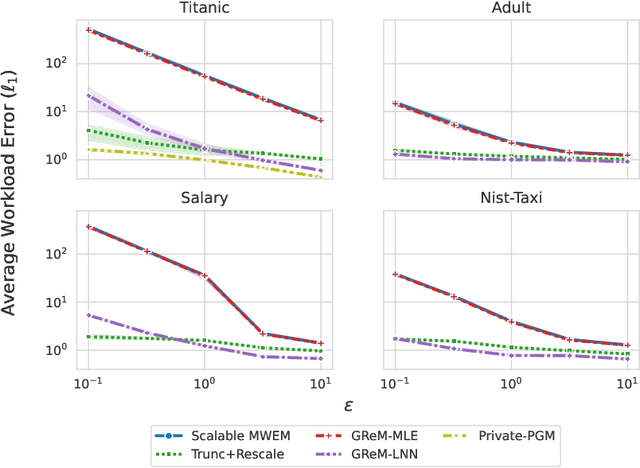
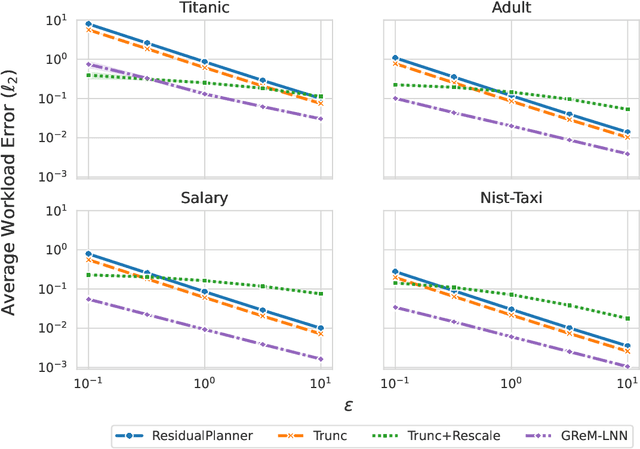
Differential privacy is the dominant standard for formal and quantifiable privacy and has been used in major deployments that impact millions of people. Many differentially private algorithms for query release and synthetic data contain steps that reconstruct answers to queries from answers to other queries measured by the mechanism. Reconstruction is an important subproblem for such mechanisms to economize the privacy budget, minimize error on reconstructed answers, and allow for scalability to high-dimensional datasets. In this paper, we introduce a principled and efficient postprocessing method ReM (Residuals-to-Marginals) for reconstructing answers to marginal queries. Our method builds on recent work on efficient mechanisms for marginal query release, based on making measurements using a residual query basis that admits efficient pseudoinversion, which is an important primitive used in reconstruction. An extension GReM-LNN (Gaussian Residuals-to-Marginals with Local Non-negativity) reconstructs marginals under Gaussian noise satisfying consistency and non-negativity, which often reduces error on reconstructed answers. We demonstrate the utility of ReM and GReM-LNN by applying them to improve existing private query answering mechanisms: ResidualPlanner and MWEM.
Investigating Symbolic Capabilities of Large Language Models
May 21, 2024Prompting techniques have significantly enhanced the capabilities of Large Language Models (LLMs) across various complex tasks, including reasoning, planning, and solving math word problems. However, most research has predominantly focused on language-based reasoning and word problems, often overlooking the potential of LLMs in handling symbol-based calculations and reasoning. This study aims to bridge this gap by rigorously evaluating LLMs on a series of symbolic tasks, such as addition, multiplication, modulus arithmetic, numerical precision, and symbolic counting. Our analysis encompasses eight LLMs, including four enterprise-grade and four open-source models, of which three have been pre-trained on mathematical tasks. The assessment framework is anchored in Chomsky's Hierarchy, providing a robust measure of the computational abilities of these models. The evaluation employs minimally explained prompts alongside the zero-shot Chain of Thoughts technique, allowing models to navigate the solution process autonomously. The findings reveal a significant decline in LLMs' performance on context-free and context-sensitive symbolic tasks as the complexity, represented by the number of symbols, increases. Notably, even the fine-tuned GPT3.5 exhibits only marginal improvements, mirroring the performance trends observed in other models. Across the board, all models demonstrated a limited generalization ability on these symbol-intensive tasks. This research underscores LLMs' challenges with increasing symbolic complexity and highlights the need for specialized training, memory and architectural adjustments to enhance their proficiency in symbol-based reasoning tasks.
Stability Analysis of Various Symbolic Rule Extraction Methods from Recurrent Neural Network
Feb 04, 2024This paper analyzes two competing rule extraction methodologies: quantization and equivalence query. We trained $3600$ RNN models, extracting $18000$ DFA with a quantization approach (k-means and SOM) and $3600$ DFA by equivalence query($L^{*}$) methods across $10$ initialization seeds. We sampled the datasets from $7$ Tomita and $4$ Dyck grammars and trained them on $4$ RNN cells: LSTM, GRU, O2RNN, and MIRNN. The observations from our experiments establish the superior performance of O2RNN and quantization-based rule extraction over others. $L^{*}$, primarily proposed for regular grammars, performs similarly to quantization methods for Tomita languages when neural networks are perfectly trained. However, for partially trained RNNs, $L^{*}$ shows instability in the number of states in DFA, e.g., for Tomita 5 and Tomita 6 languages, $L^{*}$ produced more than $100$ states. In contrast, quantization methods result in rules with number of states very close to ground truth DFA. Among RNN cells, O2RNN produces stable DFA consistently compared to other cells. For Dyck Languages, we observe that although GRU outperforms other RNNs in network performance, the DFA extracted by O2RNN has higher performance and better stability. The stability is computed as the standard deviation of accuracy on test sets on networks trained across $10$ seeds. On Dyck Languages, quantization methods outperformed $L^{*}$ with better stability in accuracy and the number of states. $L^{*}$ often showed instability in accuracy in the order of $16\% - 22\%$ for GRU and MIRNN while deviation for quantization methods varied in $5\% - 15\%$. In many instances with LSTM and GRU, DFA's extracted by $L^{*}$ even failed to beat chance accuracy ($50\%$), while those extracted by quantization method had standard deviation in the $7\%-17\%$ range. For O2RNN, both rule extraction methods had deviation in the $0.5\% - 3\%$ range.
Estimating Uncertainty in Landslide Segmentation Models
Nov 18, 2023Landslides are a recurring, widespread hazard. Preparation and mitigation efforts can be aided by a high-quality, large-scale dataset that covers global at-risk areas. Such a dataset currently does not exist and is impossible to construct manually. Recent automated efforts focus on deep learning models for landslide segmentation (pixel labeling) from satellite imagery. However, it is also important to characterize the uncertainty or confidence levels of such segmentations. Accurate and robust uncertainty estimates can enable low-cost (in terms of manual labor) oversight of auto-generated landslide databases to resolve errors, identify hard negative examples, and increase the size of labeled training data. In this paper, we evaluate several methods for assessing pixel-level uncertainty of the segmentation. Three methods that do not require architectural changes were compared, including Pre-Threshold activations, Monte-Carlo Dropout and Test-Time Augmentation -- a method that measures the robustness of predictions in the face of data augmentation. Experimentally, the quality of the latter method was consistently higher than the others across a variety of models and metrics in our dataset.
On the Computational Complexity and Formal Hierarchy of Second Order Recurrent Neural Networks
Sep 26, 2023



Artificial neural networks (ANNs) with recurrence and self-attention have been shown to be Turing-complete (TC). However, existing work has shown that these ANNs require multiple turns or unbounded computation time, even with unbounded precision in weights, in order to recognize TC grammars. However, under constraints such as fixed or bounded precision neurons and time, ANNs without memory are shown to struggle to recognize even context-free languages. In this work, we extend the theoretical foundation for the $2^{nd}$-order recurrent network ($2^{nd}$ RNN) and prove there exists a class of a $2^{nd}$ RNN that is Turing-complete with bounded time. This model is capable of directly encoding a transition table into its recurrent weights, enabling bounded time computation and is interpretable by design. We also demonstrate that $2$nd order RNNs, without memory, under bounded weights and time constraints, outperform modern-day models such as vanilla RNNs and gated recurrent units in recognizing regular grammars. We provide an upper bound and a stability analysis on the maximum number of neurons required by $2$nd order RNNs to recognize any class of regular grammar. Extensive experiments on the Tomita grammars support our findings, demonstrating the importance of tensor connections in crafting computationally efficient RNNs. Finally, we show $2^{nd}$ order RNNs are also interpretable by extraction and can extract state machines with higher success rates as compared to first-order RNNs. Our results extend the theoretical foundations of RNNs and offer promising avenues for future explainable AI research.