 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision, Stability, and Generalization: A Comprehensive Assessment of RNNs learnability capability for Classifying Counter and Dyck Languages
Oct 04, 2024



This study investigates the learnability of Recurrent Neural Networks (RNNs) in classifying structured formal languages, focusing on counter and Dyck languages. Traditionally, both first-order (LSTM) and second-order (O2RNN) RNNs have been considered effective for such tasks, primarily based on their theoretical expressiveness within the Chomsky hierarchy. However, our research challenges this notion by demonstrating that RNNs primarily operate as state machines, where their linguistic capabilities are heavily influenced by the precision of their embeddings and the strategies used for sampling negative examples. Our experiments revealed that performance declines significantly as the structural similarity between positive and negative examples increases. Remarkably, even a basic single-layer classifier using RNN embeddings performed better than chance. To evaluate generalization, we trained models on strings up to a length of 40 and tested them on strings from lengths 41 to 500, using 10 unique seeds to ensure statistical robustness. Stability comparisons between LSTM and O2RNN models showed that O2RNNs generally offer greater stability across various scenarios. We further explore the impact of different initialization strategies revealing that our hypothesis is consistent with various RNNs. Overall, this research questions established beliefs about RNNs' computational capabilities, highlighting the importance of data structure and sampling techniques in assessing neural networks' potential for language classification tasks. It emphasizes that stronger constraints on expressivity are crucial for understanding true learnability, as mere expressivity does not capture the essence of learning.
On the Computational Complexity and Formal Hierarchy of Second Order Recurrent Neural Networks
Sep 26, 2023



Artificial neural networks (ANNs) with recurrence and self-attention have been shown to be Turing-complete (TC). However, existing work has shown that these ANNs require multiple turns or unbounded computation time, even with unbounded precision in weights, in order to recognize TC grammars. However, under constraints such as fixed or bounded precision neurons and time, ANNs without memory are shown to struggle to recognize even context-free languages. In this work, we extend the theoretical foundation for the $2^{nd}$-order recurrent network ($2^{nd}$ RNN) and prove there exists a class of a $2^{nd}$ RNN that is Turing-complete with bounded time. This model is capable of directly encoding a transition table into its recurrent weights, enabling bounded time computation and is interpretable by design. We also demonstrate that $2$nd order RNNs, without memory, under bounded weights and time constraints, outperform modern-day models such as vanilla RNNs and gated recurrent units in recognizing regular grammars. We provide an upper bound and a stability analysis on the maximum number of neurons required by $2$nd order RNNs to recognize any class of regular grammar. Extensive experiments on the Tomita grammars support our findings, demonstrating the importance of tensor connections in crafting computationally efficient RNNs. Finally, we show $2^{nd}$ order RNNs are also interpretable by extraction and can extract state machines with higher success rates as compared to first-order RNNs. Our results extend the theoretical foundations of RNNs and offer promising avenues for future explainable AI research.
Neural JPEG: End-to-End Image Compression Leveraging a Standard JPEG Encoder-Decoder
Jan 31, 2022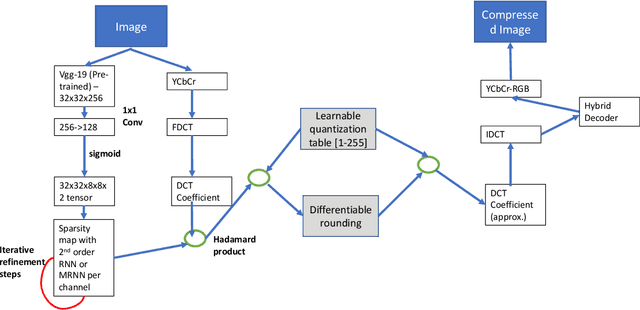
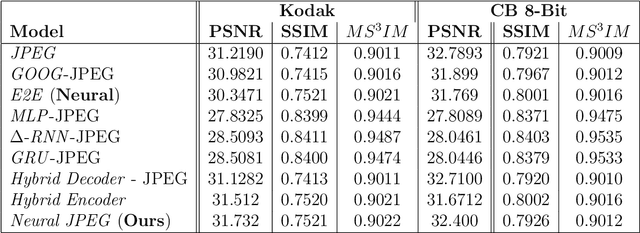

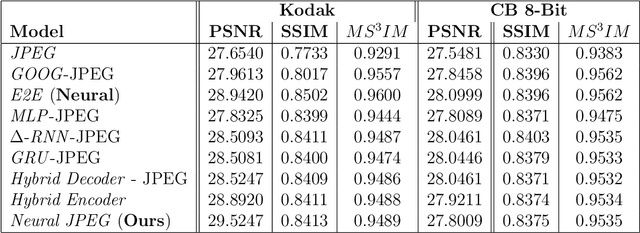
Recent advances in deep learning have led to superhuman performance across a variety of applications. Recently, these methods have been successfully employed to improve the rate-distortion performance in the task of image compression. However, current methods either use additional post-processing blocks on the decoder end to improve compression or propose an end-to-end compression scheme based on heuristics. For the majority of these, the trained deep neural networks (DNNs) are not compatible with standard encoders and would be difficult to deply on personal computers and cellphones. In light of this, we propose a system that learns to improve the encoding performance by enhancing its internal neural representations on both the encoder and decoder ends, an approach we call Neural JPEG. We propose frequency domain pre-editing and post-editing methods to optimize the distribution of the DCT coefficients at both encoder and decoder ends in order to improve the standard compression (JPEG) method. Moreover, we design and integrate a scheme for jointly learning quantization tables within this hybrid neural compression framework.Experiments demonstrate that our approach successfully improves the rate-distortion performance over JPEG across various quality metrics, such as PSNR and MS-SSIM, and generates visually appealing images with better color retention quality.
An Empirical Analysis of Recurrent Learning Algorithms In Neural Lossy Image Compression Systems
Jan 27, 2022Recent advances in deep learning have resulted in image compression algorithms that outperform JPEG and JPEG 2000 on the standard Kodak benchmark. However, they are slow to train (due to backprop-through-time) and, to the best of our knowledge, have not been systematically evaluated on a large variety of datasets. In this paper, we perform the first large-scale comparison of recent state-of-the-art hybrid neural compression algorithms, while exploring the effects of alternative training strategies (when applicable). The hybrid recurrent neural decoder is a former state-of-the-art model (recently overtaken by a Google model) that can be trained using backprop-through-time (BPTT) or with alternative algorithms like sparse attentive backtracking (SAB), unbiased online recurrent optimization (UORO), and real-time recurrent learning (RTRL). We compare these training alternatives along with the Google models (GOOG and E2E) on 6 benchmark datasets. Surprisingly, we found that the model trained with SAB performs better (outperforming even BPTT), resulting in faster convergence and a better peak signal-to-noise ratio.
Extractive Research Slide Generation Using Windowed Labeling Ranking
Jun 06, 2021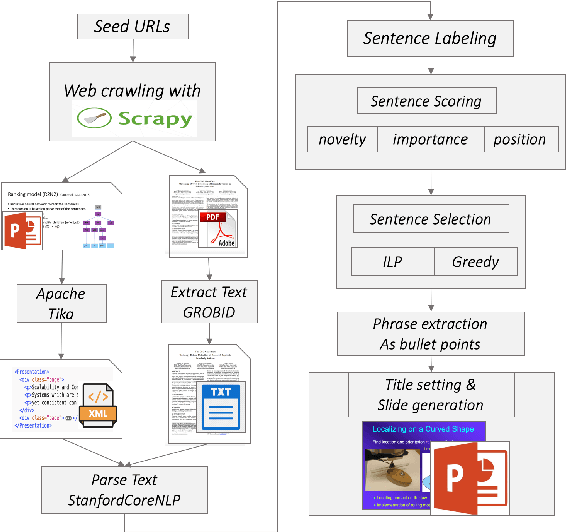
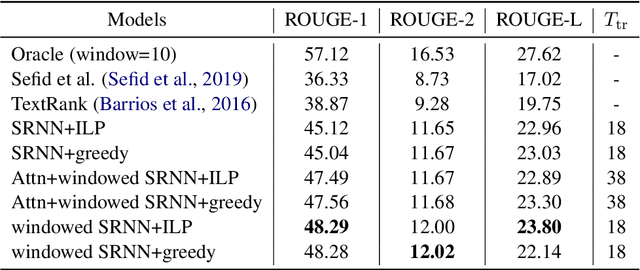
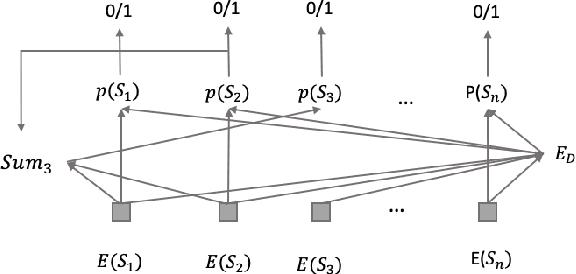
Presentation slides describing the content of scientific and technical papers are an efficient and effective way to present that work. However, manually generating presentation slides is labor intensive. We propose a method to automatically generate slides for scientific papers based on a corpus of 5000 paper-slide pairs compiled from conference proceedings websites. The sentence labeling module of our method is based on SummaRuNNer, a neural sequence model for extractive summarization. Instead of ranking sentences based on semantic similarities in the whole document, our algorithm measures importance and novelty of sentences by combining semantic and lexical features within a sentence window. Our method outperforms several baseline methods including SummaRuNNer by a significant margin in terms of ROUGE score.
OmniLayout: Room Layout Reconstruction from Indoor Spherical Panoramas
Apr 19, 2021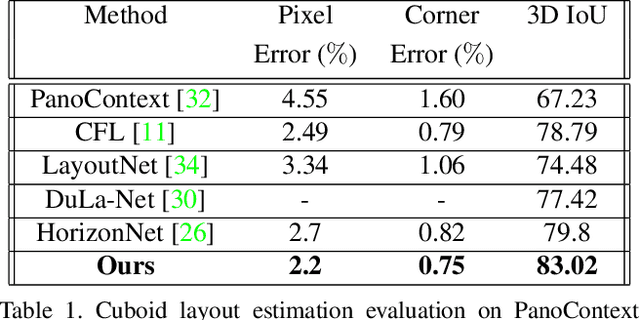
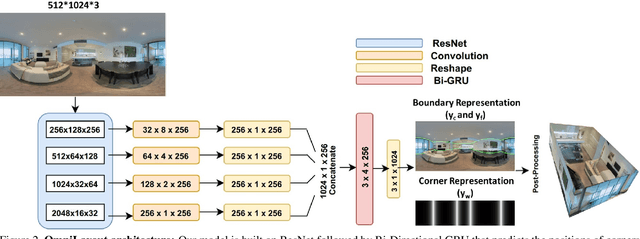
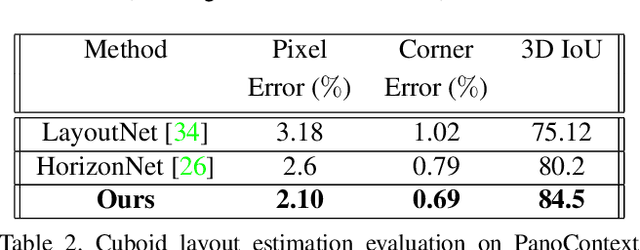

Given a single RGB panorama, the goal of 3D layout reconstruction is to estimate the room layout by predicting the corners, floor boundary, and ceiling boundary. A common approach has been to use standard convolutional networks to predict the corners and boundaries, followed by post-processing to generate the 3D layout. However, the space-varying distortions in panoramic images are not compatible with the translational equivariance property of standard convolutions, thus degrading performance. Instead, we propose to use spherical convolutions. The resulting network, which we call OmniLayout performs convolutions directly on the sphere surface, sampling according to inverse equirectangular projection and hence invariant to equirectangular distortions. Using a new evaluation metric, we show that our network reduces the error in the heavily distorted regions (near the poles) by approx 25 % when compared to standard convolutional networks. Experimental results show that OmniLayout outperforms the state-of-the-art by approx 4% on two different benchmark datasets (PanoContext and Stanford 2D-3D). Code is available at https://github.com/rshivansh/OmniLayout.