 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniLayout: Room Layout Reconstruction from Indoor Spherical Panoramas
Apr 19, 2021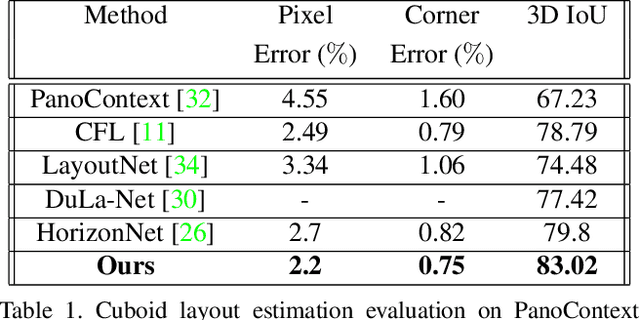
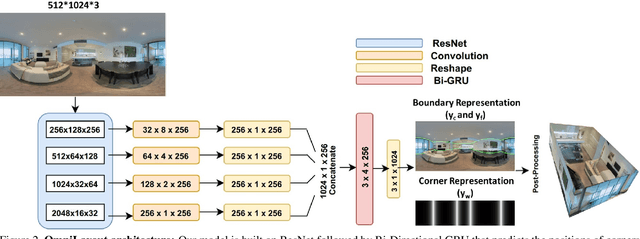
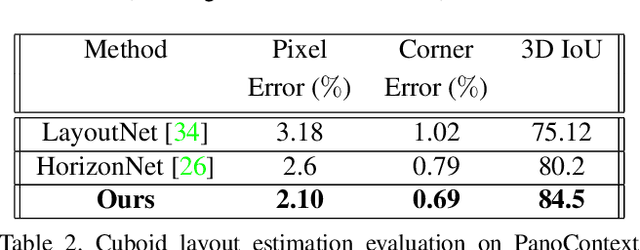

Given a single RGB panorama, the goal of 3D layout reconstruction is to estimate the room layout by predicting the corners, floor boundary, and ceiling boundary. A common approach has been to use standard convolutional networks to predict the corners and boundaries, followed by post-processing to generate the 3D layout. However, the space-varying distortions in panoramic images are not compatible with the translational equivariance property of standard convolutions, thus degrading performance. Instead, we propose to use spherical convolutions. The resulting network, which we call OmniLayout performs convolutions directly on the sphere surface, sampling according to inverse equirectangular projection and hence invariant to equirectangular distortions. Using a new evaluation metric, we show that our network reduces the error in the heavily distorted regions (near the poles) by approx 25 % when compared to standard convolutional networks. Experimental results show that OmniLayout outperforms the state-of-the-art by approx 4% on two different benchmark datasets (PanoContext and Stanford 2D-3D). Code is available at https://github.com/rshivansh/OmniLayout.
Noisy Student Training using Body Language Dataset Improves Facial Expression Recognition
Aug 06, 2020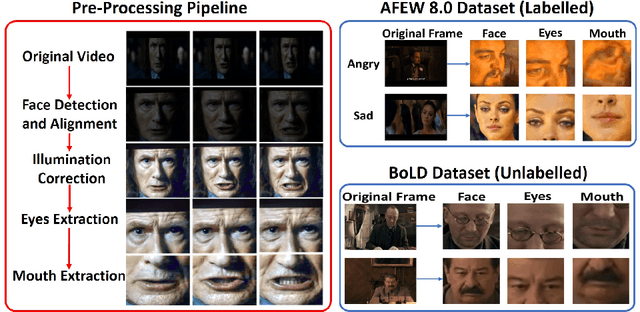



Facial expression recognition from videos in the wild is a challenging task due to the lack of abundant labelled training data. Large DNN (deep neural network) architectures and ensemble methods have resulted in better performance, but soon reach saturation at some point due to data inadequacy. In this paper, we use a self-training method that utilizes a combination of a labelled dataset and an unlabelled dataset (Body Language Dataset - BoLD). Experimental analysis shows that training a noisy student network iteratively helps in achieving significantly better results. Additionally, our model isolates different regions of the face and processes them independently using a multi-level attention mechanism which further boosts the performance. Our results show that the proposed method achieves state-of-the-art performance on benchmark datasets CK+ and AFEW 8.0 when compared to other single models.
Neural Machine Translation for Low-Resourced Indian Languages
Apr 19, 2020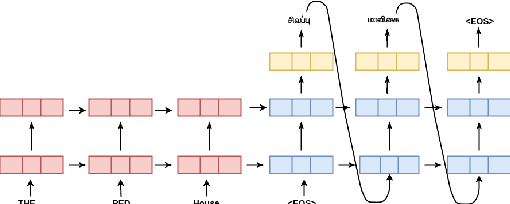
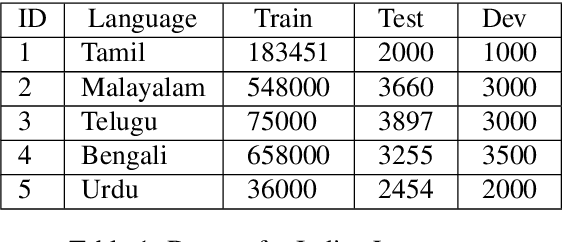

A large number of significant assets are available online in English, which is frequently translated into native languages to ease the information sharing among local people who are not much familiar with English. However, manual translation is a very tedious, costly, and time-taking process. To this end, machine translation is an effective approach to convert text to a different language without any human involvement. Neural machine translation (NMT) is one of the most proficient translation techniques amongst all existing machine translation systems. In this paper, we have applied NMT on two of the most morphological rich Indian languages, i.e. English-Tamil and English-Malayalam. We proposed a novel NMT model using Multihead self-attention along with pre-trained Byte-Pair-Encoded (BPE) and MultiBPE embeddings to develop an efficient translation system that overcomes the OOV (Out Of Vocabulary) problem for low resourced morphological rich Indian languages which do not have much translation available online. We also collected corpus from different sources, addressed the issues with these publicly available data and refined them for further uses. We used the BLEU score for evaluating our system performance. Experimental results and survey confirmed that our proposed translator (24.34 and 9.78 BLEU score) outperforms Google translator (9.40 and 5.94 BLEU score) respectively.
Video-based Person Re-identification Using Spatial-Temporal Attention Networks
Oct 26, 2018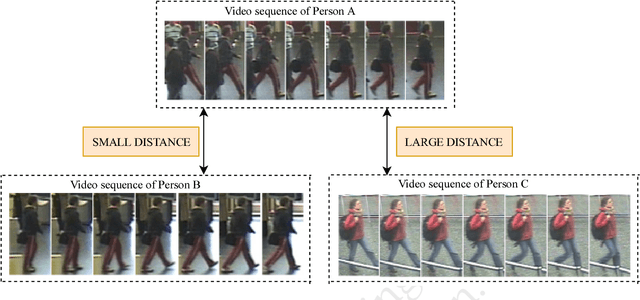

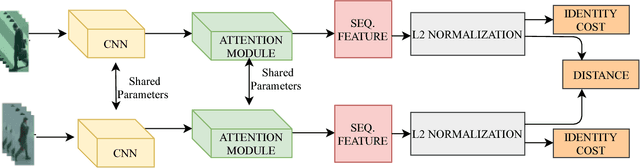

We consider the problem of video-based person re-identification. The goal is to identify a person from videos captured under different cameras. In this paper, we propose an efficient spatial-temporal attention based model for person re-identification from videos. Our method generates an attention score for each frame based on frame-level features. The attention scores of all frames in a video are used to produce a weighted feature vector for the input video. Unlike most existing deep learning methods that use global representation, our approach focuses on attention scores. Extensive experiments on two benchmark datasets demonstrate that our method achieves the state-of-the-art performance. This is a technical report.