 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDReX: An Explainable Deep Learning-based Multimodal Recommendation Framework
Feb 23, 2026Multimodal recommender systems leverage diverse data sources, such as user interactions, content features, and contextual information, to address challenges like cold-start and data sparsity. However, existing methods often suffer from one or more key limitations: processing different modalities in isolation, requiring complete multimodal data for each interaction during training, or independent learning of user and item representations. These factors contribute to increased complexity and potential misalignment between user and item embeddings. To address these challenges, we propose DReX, a unified multimodal recommendation framework that incrementally refines user and item representations by leveraging interaction-level features from multimodal feedback. Our model employs gated recurrent units to selectively integrate these fine-grained features into global representations. This incremental update mechanism provides three key advantages: (1) simultaneous modeling of both nuanced interaction details and broader preference patterns, (2) eliminates the need for separate user and item feature extraction processes, leading to enhanced alignment in their learned representation, and (3) inherent robustness to varying or missing modalities. We evaluate the performance of the proposed approach on three real-world datasets containing reviews and ratings as interaction modalities. By considering review text as a modality, our approach automatically generates interpretable keyword profiles for both users and items, which supplement the recommendation process with interpretable preference indicators. Experiment results demonstrate that our approach outperforms state-of-the-art methods across all evaluated datasets.
GrIT: Group Informed Transformer for Sequential Recommendation
Feb 23, 2026Sequential recommender systems aim to predict a user's future interests by extracting temporal patterns from their behavioral history. Existing approaches typically employ transformer-based architectures to process long sequences of user interactions, capturing preference shifts by modeling temporal relationships between items. However, these methods often overlook the influence of group-level features that capture the collective behavior of similar users. We hypothesize that explicitly modeling temporally evolving group features alongside individual user histories can significantly enhance next-item recommendation. Our approach introduces latent group representations, where each user's affiliation to these groups is modeled through learnable, time-varying membership weights. The membership weights at each timestep are computed by modeling shifts in user preferences through their interaction history, where we incorporate both short-term and long-term user preferences. We extract a set of statistical features that capture the dynamics of user behavior and further refine them through a series of transformations to produce the final drift-aware membership weights. A group-based representation is derived by weighting latent group embeddings with the learned membership scores. This representation is integrated with the user's sequential representation within the transformer block to jointly capture personal and group-level temporal dynamics, producing richer embeddings that lead to more accurate, context-aware recommendations. We validate the effectiveness of our approach through extensive experiments on five benchmark datasets, where it consistently outperforms state-of-the-art sequential recommendation methods.
What Matters in Data Curation for Multimodal Reasoning? Insights from the DCVLR Challenge
Jan 16, 2026We study data curation for multimodal reasoning through the NeurIPS 2025 Data Curation for Vision-Language Reasoning (DCVLR) challenge, which isolates dataset selection by fixing the model and training protocol. Using a compact curated dataset derived primarily from Walton Multimodal Cold Start, our submission placed first in the challenge. Through post-competition ablations, we show that difficulty-based example selection on an aligned base dataset is the dominant driver of performance gains. Increasing dataset size does not reliably improve mean accuracy under the fixed training recipe, but mainly reduces run-to-run variance, while commonly used diversity and synthetic augmentation heuristics provide no additional benefit and often degrade performance. These results characterize DCVLR as a saturation-regime evaluation and highlight the central role of alignment and difficulty in data-efficient multimodal reasoning.
AugAbEx : Way Forward for Extractive Case Summarization
Nov 15, 2025
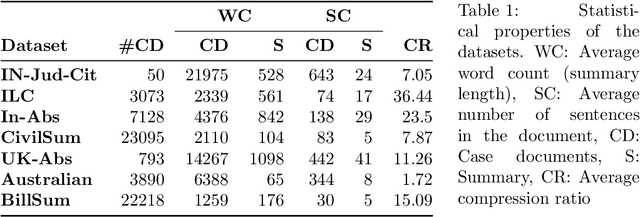
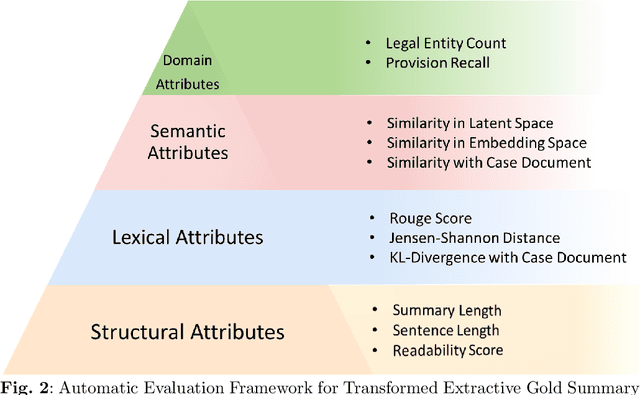
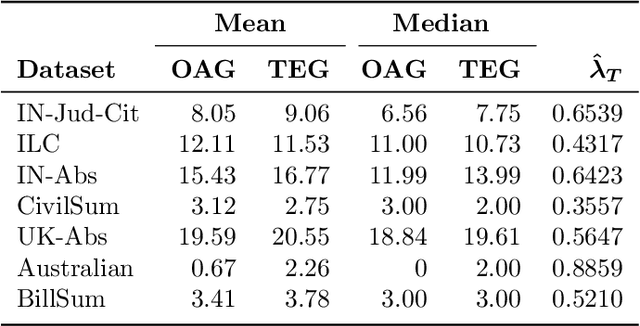
Summarization of legal judgments poses a heavy cognitive burden on law practitioners due to the complexity of the language, context-sensitive legal jargon, and the length of the document. Therefore, the automatic summarization of legal documents has attracted serious attention from natural language processing researchers. Since the abstractive summaries of legal documents generated by deep neural methods remain prone to the risk of misrepresenting nuanced legal jargon or overlooking key contextual details, we envisage a rising trend toward the use of extractive case summarizers. Given the high cost of human annotation for gold standard extractive summaries, we engineer a light and transparent pipeline that leverages existing abstractive gold standard summaries to create the corresponding extractive gold standard versions. The approach ensures that the experts` opinions ensconced in the original gold standard abstractive summaries are carried over to the transformed extractive summaries. We aim to augment seven existing case summarization datasets, which include abstractive summaries, by incorporating corresponding extractive summaries and create an enriched data resource for case summarization research community. To ensure the quality of the augmented extractive summaries, we perform an extensive comparative evaluation with the original abstractive gold standard summaries covering structural, lexical, and semantic dimensions. We also compare the domain-level information of the two summaries. We commit to release the augmented datasets in the public domain for use by the research community and believe that the resource will offer opportunities to advance the field of automatic summarization of legal documents.
Geometric Preference Elicitation for Minimax Regret Optimization in Uncertainty Matroids
Mar 25, 2025


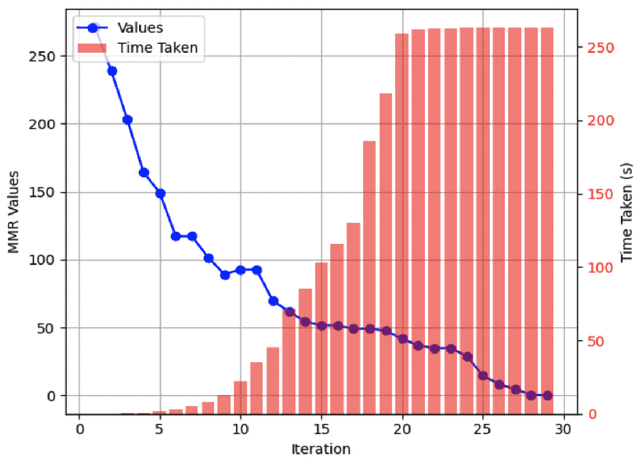
This paper presents an efficient preference elicitation framework for uncertain matroid optimization, where precise weight information is unavailable, but insights into possible weight values are accessible. The core innovation of our approach lies in its ability to systematically elicit user preferences, aligning the optimization process more closely with decision-makers' objectives. By incrementally querying preferences between pairs of elements, we iteratively refine the parametric uncertainty regions, leveraging the structural properties of matroids. Our method aims to achieve the exact optimum by reducing regret with a few elicitation rounds. Additionally, our approach avoids the computation of Minimax Regret and the use of Linear programming solvers at every iteration, unlike previous methods. Experimental results on four standard matroids demonstrate that our method reaches optimality more quickly and with fewer preference queries than existing techniques.
Multimodal Fusion Learning with Dual Attention for Medical Imaging
Dec 02, 2024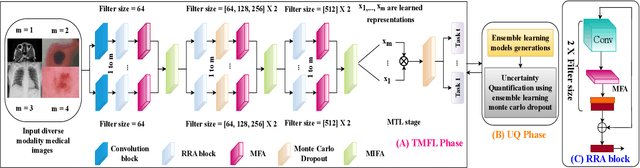

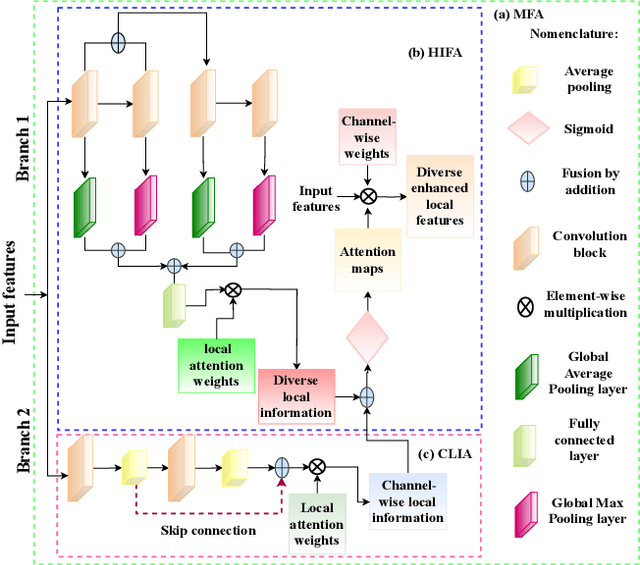

Multimodal fusion learning has shown significant promise in classifying various diseases such as skin cancer and brain tumors. However, existing methods face three key limitations. First, they often lack generalizability to other diagnosis tasks due to their focus on a particular disease. Second, they do not fully leverage multiple health records from diverse modalities to learn robust complementary information. And finally, they typically rely on a single attention mechanism, missing the benefits of multiple attention strategies within and across various modalities. To address these issues, this paper proposes a dual robust information fusion attention mechanism (DRIFA) that leverages two attention modules, i.e. multi-branch fusion attention module and the multimodal information fusion attention module. DRIFA can be integrated with any deep neural network, forming a multimodal fusion learning framework denoted as DRIFA-Net. We show that the multi-branch fusion attention of DRIFA learns enhanced representations for each modality, such as dermoscopy, pap smear, MRI, and CT-scan, whereas multimodal information fusion attention module learns more refined multimodal shared representations, improving the network's generalization across multiple tasks and enhancing overall performance. Additionally, to estimate the uncertainty of DRIFA-Net predictions, we have employed an ensemble Monte Carlo dropout strategy. Extensive experiments on five publicly available datasets with diverse modalities demonstrate that our approach consistently outperforms state-of-the-art methods. The code is available at https://github.com/misti1203/DRIFA-Net.
* 10 pages
Citation-Based Summarization of Landmark Judgments
Jun 16, 2024



Landmark judgments are of prime importance in the Common Law System because of their exceptional jurisprudence and frequent references in other judgments. In this work, we leverage contextual references available in citing judgments to create an extractive summary of the target judgment. We evaluate the proposed algorithm on two datasets curated from the judgments of Indian Courts and find the results promising.
Human Centered AI for Indian Legal Text Analytics
Mar 16, 2024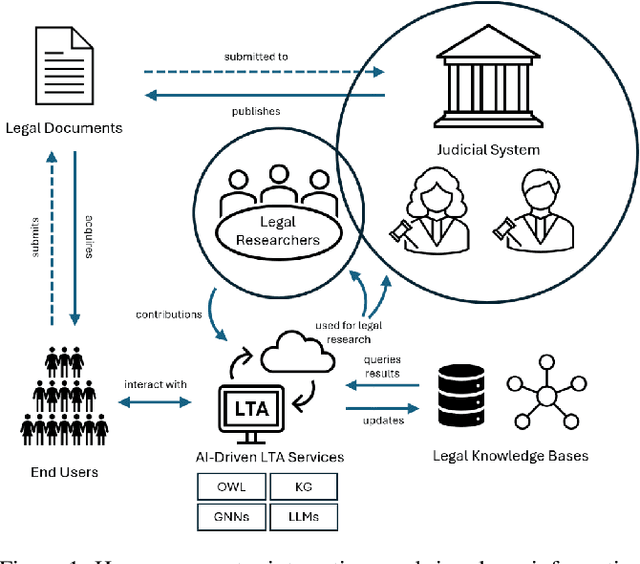
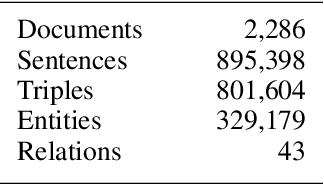


Legal research is a crucial task in the practice of law. It requires intense human effort and intellectual prudence to research a legal case and prepare arguments. Recent boom in generative AI has not translated to proportionate rise in impactful legal applications, because of low trustworthiness and and the scarcity of specialized datasets for training Large Language Models (LLMs). This position paper explores the potential of LLMs within Legal Text Analytics (LTA), highlighting specific areas where the integration of human expertise can significantly enhance their performance to match that of experts. We introduce a novel dataset and describe a human centered, compound AI system that principally incorporates human inputs for performing LTA tasks with LLMs.
Infusing Knowledge into Large Language Models with Contextual Prompts
Mar 03, 2024



Knowledge infusion is a promising method for enhancing Large Language Models for domain-specific NLP tasks rather than pre-training models over large data from scratch. These augmented LLMs typically depend on additional pre-training or knowledge prompts from an existing knowledge graph, which is impractical in many applications. In contrast, knowledge infusion directly from relevant documents is more generalisable and alleviates the need for structured knowledge graphs while also being useful for entities that are usually not found in any knowledge graph. With this motivation, we propose a simple yet generalisable approach for knowledge infusion by generating prompts from the context in the input text. Our experiments show the effectiveness of our approach which we evaluate by probing the fine-tuned LLMs.
Deep dive into language traits of AI-generated Abstracts
Dec 17, 2023



Generative language models, such as ChatGPT, have garnered attention for their ability to generate human-like writing in various fields, including academic research. The rapid proliferation of generated texts has bolstered the need for automatic identification to uphold transparency and trust in the information. However, these generated texts closely resemble human writing and often have subtle differences in the grammatical structure, tones, and patterns, which makes systematic scrutinization challenging. In this work, we attempt to detect the Abstracts generated by ChatGPT, which are much shorter in length and bounded. We extract the texts semantic and lexical properties and observe that traditional machine learning models can confidently detect these Abstracts.