 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefineFormer3D: Efficient 3D Medical Image Segmentation via Adaptive Multi-Scale Transformer with Cross Attention Fusion
Feb 18, 2026Accurate and computationally efficient 3D medical image segmentation remains a critical challenge in clinical workflows. Transformer-based architectures often demonstrate superior global contextual modeling but at the expense of excessive parameter counts and memory demands, restricting their clinical deployment. We propose RefineFormer3D, a lightweight hierarchical transformer architecture that balances segmentation accuracy and computational efficiency for volumetric medical imaging. The architecture integrates three key components: (i) GhostConv3D-based patch embedding for efficient feature extraction with minimal redundancy, (ii) MixFFN3D module with low-rank projections and depthwise convolutions for parameter-efficient feature extraction, and (iii) a cross-attention fusion decoder enabling adaptive multi-scale skip connection integration. RefineFormer3D contains only 2.94M parameters, substantially fewer than contemporary transformer-based methods. Extensive experiments on ACDC and BraTS benchmarks demonstrate that RefineFormer3D achieves 93.44\% and 85.9\% average Dice scores respectively, outperforming or matching state-of-the-art methods while requiring significantly fewer parameters. Furthermore, the model achieves fast inference (8.35 ms per volume on GPU) with low memory requirements, supporting deployment in resource-constrained clinical environments. These results establish RefineFormer3D as an effective and scalable solution for practical 3D medical image segmentation.
Camera Model Identification with SPAIR-Swin and Entropy based Non-Homogeneous Patches
Mar 28, 2025



Source camera model identification (SCMI) plays a pivotal role in image forensics with applications including authenticity verification and copyright protection. For identifying the camera model used to capture a given image, we propose SPAIR-Swin, a novel model combining a modified spatial attention mechanism and inverted residual block (SPAIR) with a Swin Transformer. SPAIR-Swin effectively captures both global and local features, enabling robust identification of artifacts such as noise patterns that are particularly effective for SCMI. Additionally, unlike conventional methods focusing on homogeneous patches, we propose a patch selection strategy for SCMI that emphasizes high-entropy regions rich in patterns and textures. Extensive evaluations on four benchmark SCMI datasets demonstrate that SPAIR-Swin outperforms existing methods, achieving patch-level accuracies of 99.45%, 98.39%, 99.45%, and 97.46% and image-level accuracies of 99.87%, 99.32%, 100%, and 98.61% on the Dresden, Vision, Forchheim, and Socrates datasets, respectively. Our findings highlight that high-entropy patches, which contain high-frequency information such as edge sharpness, noise, and compression artifacts, are more favorable in improving SCMI accuracy. Code will be made available upon request.
Multimodal Fusion Learning with Dual Attention for Medical Imaging
Dec 02, 2024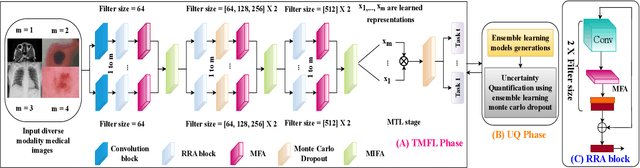

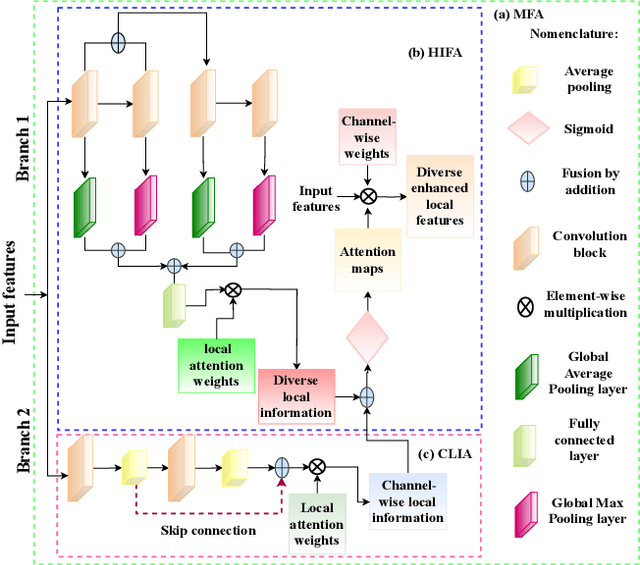

Multimodal fusion learning has shown significant promise in classifying various diseases such as skin cancer and brain tumors. However, existing methods face three key limitations. First, they often lack generalizability to other diagnosis tasks due to their focus on a particular disease. Second, they do not fully leverage multiple health records from diverse modalities to learn robust complementary information. And finally, they typically rely on a single attention mechanism, missing the benefits of multiple attention strategies within and across various modalities. To address these issues, this paper proposes a dual robust information fusion attention mechanism (DRIFA) that leverages two attention modules, i.e. multi-branch fusion attention module and the multimodal information fusion attention module. DRIFA can be integrated with any deep neural network, forming a multimodal fusion learning framework denoted as DRIFA-Net. We show that the multi-branch fusion attention of DRIFA learns enhanced representations for each modality, such as dermoscopy, pap smear, MRI, and CT-scan, whereas multimodal information fusion attention module learns more refined multimodal shared representations, improving the network's generalization across multiple tasks and enhancing overall performance. Additionally, to estimate the uncertainty of DRIFA-Net predictions, we have employed an ensemble Monte Carlo dropout strategy. Extensive experiments on five publicly available datasets with diverse modalities demonstrate that our approach consistently outperforms state-of-the-art methods. The code is available at https://github.com/misti1203/DRIFA-Net.
* 10 pages
Food Classification using Joint Representation of Visual and Textual Data
Aug 03, 2023Food classification is an important task in health care. In this work, we propose a multimodal classification framework that uses the modified version of EfficientNet with the Mish activation function for image classification, and the traditional BERT transformer-based network is used for text classification. The proposed network and the other state-of-the-art methods are evaluated on a large open-source dataset, UPMC Food-101. The experimental results show that the proposed network outperforms the other methods, a significant difference of 11.57% and 6.34% in accuracy is observed for image and text classification, respectively, when compared with the second-best performing method. We also compared the performance in terms of accuracy, precision, and recall for text classification using both machine learning and deep learning-based models. The comparative analysis from the prediction results of both images and text demonstrated the efficiency and robustness of the proposed approach.