 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Text Knowledge Modeling for Unsupervised Multi-Scenario Person Re-Identification
Jan 16, 2026We propose unsupervised multi-scenario (UMS) person re-identification (ReID) as a new task that expands ReID across diverse scenarios (cross-resolution, clothing change, etc.) within a single coherent framework. To tackle UMS-ReID, we introduce image-text knowledge modeling (ITKM) -- a three-stage framework that effectively exploits the representational power of vision-language models. We start with a pre-trained CLIP model with an image encoder and a text encoder. In Stage I, we introduce a scenario embedding in the image encoder and fine-tune the encoder to adaptively leverage knowledge from multiple scenarios. In Stage II, we optimize a set of learned text embeddings to associate with pseudo-labels from Stage I and introduce a multi-scenario separation loss to increase the divergence between inter-scenario text representations. In Stage III, we first introduce cluster-level and instance-level heterogeneous matching modules to obtain reliable heterogeneous positive pairs (e.g., a visible image and an infrared image of the same person) within each scenario. Next, we propose a dynamic text representation update strategy to maintain consistency between text and image supervision signals. Experimental results across multiple scenarios demonstrate the superiority and generalizability of ITKM; it not only outperforms existing scenario-specific methods but also enhances overall performance by integrating knowledge from multiple scenarios.
Styleclone: Face Stylization with Diffusion Based Data Augmentation
Aug 23, 2025

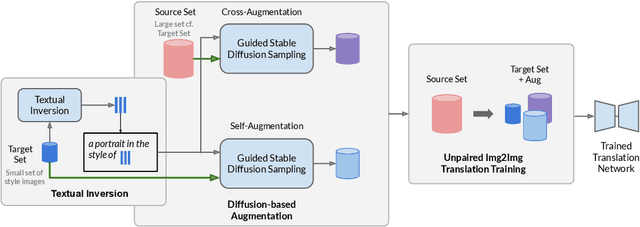

We present StyleClone, a method for training image-to-image translation networks to stylize faces in a specific style, even with limited style images. Our approach leverages textual inversion and diffusion-based guided image generation to augment small style datasets. By systematically generating diverse style samples guided by both the original style images and real face images, we significantly enhance the diversity of the style dataset. Using this augmented dataset, we train fast image-to-image translation networks that outperform diffusion-based methods in speed and quality. Experiments on multiple styles demonstrate that our method improves stylization quality, better preserves source image content, and significantly accelerates inference. Additionally, we provide a systematic evaluation of the augmentation techniques and their impact on stylization performance.
RephraseTTS: Dynamic Length Text based Speech Insertion with Speaker Style Transfer
Aug 23, 2025



We propose a method for the task of text-conditioned speech insertion, i.e. inserting a speech sample in an input speech sample, conditioned on the corresponding complete text transcript. An example use case of the task would be to update the speech audio when corrections are done on the corresponding text transcript. The proposed method follows a transformer-based non-autoregressive approach that allows speech insertions of variable lengths, which are dynamically determined during inference, based on the text transcript and tempo of the available partial input. It is capable of maintaining the speaker's voice characteristics, prosody and other spectral properties of the available speech input. Results from our experiments and user study on LibriTTS show that our method outperforms baselines based on an existing adaptive text to speech method. We also provide numerous qualitative results to appreciate the quality of the output from the proposed method.
Selective Feature Re-Encoded Quantum Convolutional Neural Network with Joint Optimization for Image Classification
Jul 02, 2025



Quantum Machine Learning (QML) has seen significant advancements, driven by recent improvements in Noisy Intermediate-Scale Quantum (NISQ) devices. Leveraging quantum principles such as entanglement and superposition, quantum convolutional neural networks (QCNNs) have demonstrated promising results in classifying both quantum and classical data. This study examines QCNNs in the context of image classification and proposes a novel strategy to enhance feature processing and a QCNN architecture for improved classification accuracy. First, a selective feature re-encoding strategy is proposed, which directs the quantum circuits to prioritize the most informative features, thereby effectively navigating the crucial regions of the Hilbert space to find the optimal solution space. Secondly, a novel parallel-mode QCNN architecture is designed to simultaneously incorporate features extracted by two classical methods, Principal Component Analysis (PCA) and Autoencoders, within a unified training scheme. The joint optimization involved in the training process allows the QCNN to benefit from complementary feature representations, enabling better mutual readjustment of model parameters. To assess these methodologies, comprehensive experiments have been performed using the widely used MNIST and Fashion MNIST datasets for binary classification tasks. Experimental findings reveal that the selective feature re-encoding method significantly improves the quantum circuit's feature processing capability and performance. Furthermore, the jointly optimized parallel QCNN architecture consistently outperforms the individual QCNN models and the traditional ensemble approach involving independent learning followed by decision fusion, confirming its superior accuracy and generalization capabilities.
Self-Supervised Multimodal NeRF for Autonomous Driving
Jun 24, 2025In this paper, we propose a Neural Radiance Fields (NeRF) based framework, referred to as Novel View Synthesis Framework (NVSF). It jointly learns the implicit neural representation of space and time-varying scene for both LiDAR and Camera. We test this on a real-world autonomous driving scenario containing both static and dynamic scenes. Compared to existing multimodal dynamic NeRFs, our framework is self-supervised, thus eliminating the need for 3D labels. For efficient training and faster convergence, we introduce heuristic-based image pixel sampling to focus on pixels with rich information. To preserve the local features of LiDAR points, a Double Gradient based mask is employed. Extensive experiments on the KITTI-360 dataset show that, compared to the baseline models, our framework has reported best performance on both LiDAR and Camera domain. Code of the model is available at https://github.com/gaurav00700/Selfsupervised-NVSF
Camera Model Identification with SPAIR-Swin and Entropy based Non-Homogeneous Patches
Mar 28, 2025



Source camera model identification (SCMI) plays a pivotal role in image forensics with applications including authenticity verification and copyright protection. For identifying the camera model used to capture a given image, we propose SPAIR-Swin, a novel model combining a modified spatial attention mechanism and inverted residual block (SPAIR) with a Swin Transformer. SPAIR-Swin effectively captures both global and local features, enabling robust identification of artifacts such as noise patterns that are particularly effective for SCMI. Additionally, unlike conventional methods focusing on homogeneous patches, we propose a patch selection strategy for SCMI that emphasizes high-entropy regions rich in patterns and textures. Extensive evaluations on four benchmark SCMI datasets demonstrate that SPAIR-Swin outperforms existing methods, achieving patch-level accuracies of 99.45%, 98.39%, 99.45%, and 97.46% and image-level accuracies of 99.87%, 99.32%, 100%, and 98.61% on the Dresden, Vision, Forchheim, and Socrates datasets, respectively. Our findings highlight that high-entropy patches, which contain high-frequency information such as edge sharpness, noise, and compression artifacts, are more favorable in improving SCMI accuracy. Code will be made available upon request.
SelfBC: Self Behavior Cloning for Offline Reinforcement Learning
Aug 04, 2024



Policy constraint methods in offline reinforcement learning employ additional regularization techniques to constrain the discrepancy between the learned policy and the offline dataset. However, these methods tend to result in overly conservative policies that resemble the behavior policy, thus limiting their performance. We investigate this limitation and attribute it to the static nature of traditional constraints. In this paper, we propose a novel dynamic policy constraint that restricts the learned policy on the samples generated by the exponential moving average of previously learned policies. By integrating this self-constraint mechanism into off-policy methods, our method facilitates the learning of non-conservative policies while avoiding policy collapse in the offline setting. Theoretical results show that our approach results in a nearly monotonically improved reference policy. Extensive experiments on the D4RL MuJoCo domain demonstrate that our proposed method achieves state-of-the-art performance among the policy constraint methods.
Effect of Fog Particle Size Distribution on 3D Object Detection Under Adverse Weather Conditions
Aug 02, 2024LiDAR-based sensors employing optical spectrum signals play a vital role in providing significant information about the target objects in autonomous driving vehicle systems. However, the presence of fog in the atmosphere severely degrades the overall system's performance. This manuscript analyzes the role of fog particle size distributions in 3D object detection under adverse weather conditions. We utilise Mie theory and meteorological optical range (MOR) to calculate the attenuation and backscattering coefficient values for point cloud generation and analyze the overall system's accuracy in Car, Cyclist, and Pedestrian case scenarios under easy, medium and hard detection difficulties. Gamma and Junge (Power-Law) distributions are employed to mathematically model the fog particle size distribution under strong and moderate advection fog environments. Subsequently, we modified the KITTI dataset based on the backscattering coefficient values and trained it on the PV-RCNN++ deep neural network model for Car, Cyclist, and Pedestrian cases under different detection difficulties. The result analysis shows a significant variation in the system's accuracy concerning the changes in target object dimensionality, the nature of the fog environment and increasing detection difficulties, with the Car exhibiting the highest accuracy of around 99% and the Pedestrian showing the lowest accuracy of around 73%.
OmniVec: Learning robust representations with cross modal sharing
Nov 07, 2023Majority of research in learning based methods has been towards designing and training networks for specific tasks. However, many of the learning based tasks, across modalities, share commonalities and could be potentially tackled in a joint framework. We present an approach in such direction, to learn multiple tasks, in multiple modalities, with a unified architecture. The proposed network is composed of task specific encoders, a common trunk in the middle, followed by task specific prediction heads. We first pre-train it by self-supervised masked training, followed by sequential training for the different tasks. We train the network on all major modalities, e.g.\ visual, audio, text and 3D, and report results on $22$ diverse and challenging public benchmarks. We demonstrate empirically that, using a joint network to train across modalities leads to meaningful information sharing and this allows us to achieve state-of-the-art results on most of the benchmarks. We also show generalization of the trained network on cross-modal tasks as well as unseen datasets and tasks.
Sentence Bag Graph Formulation for Biomedical Distant Supervision Relation Extraction
Oct 29, 2023



We introduce a novel graph-based framework for alleviating key challenges in distantly-supervised relation extraction and demonstrate its effectiveness in the challenging and important domain of biomedical data. Specifically, we propose a graph view of sentence bags referring to an entity pair, which enables message-passing based aggregation of information related to the entity pair over the sentence bag. The proposed framework alleviates the common problem of noisy labeling in distantly supervised relation extraction and also effectively incorporates inter-dependencies between sentences within a bag. Extensive experiments on two large-scale biomedical relation datasets and the widely utilized NYT dataset demonstrate that our proposed framework significantly outperforms the state-of-the-art methods for biomedical distant supervision relation extraction while also providing excellent performance for relation extraction in the general text mining domain.