 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Feature Re-Encoded Quantum Convolutional Neural Network with Joint Optimization for Image Classification
Jul 02, 2025



Quantum Machine Learning (QML) has seen significant advancements, driven by recent improvements in Noisy Intermediate-Scale Quantum (NISQ) devices. Leveraging quantum principles such as entanglement and superposition, quantum convolutional neural networks (QCNNs) have demonstrated promising results in classifying both quantum and classical data. This study examines QCNNs in the context of image classification and proposes a novel strategy to enhance feature processing and a QCNN architecture for improved classification accuracy. First, a selective feature re-encoding strategy is proposed, which directs the quantum circuits to prioritize the most informative features, thereby effectively navigating the crucial regions of the Hilbert space to find the optimal solution space. Secondly, a novel parallel-mode QCNN architecture is designed to simultaneously incorporate features extracted by two classical methods, Principal Component Analysis (PCA) and Autoencoders, within a unified training scheme. The joint optimization involved in the training process allows the QCNN to benefit from complementary feature representations, enabling better mutual readjustment of model parameters. To assess these methodologies, comprehensive experiments have been performed using the widely used MNIST and Fashion MNIST datasets for binary classification tasks. Experimental findings reveal that the selective feature re-encoding method significantly improves the quantum circuit's feature processing capability and performance. Furthermore, the jointly optimized parallel QCNN architecture consistently outperforms the individual QCNN models and the traditional ensemble approach involving independent learning followed by decision fusion, confirming its superior accuracy and generalization capabilities.
An Optimized YOLOv5 Based Approach For Real-time Vehicle Detection At Road Intersections Using Fisheye Cameras
Feb 06, 2025



Real time vehicle detection is a challenging task for urban traffic surveillance. Increase in urbanization leads to increase in accidents and traffic congestion in junction areas resulting in delayed travel time. In order to solve these problems, an intelligent system utilizing automatic detection and tracking system is significant. But this becomes a challenging task at road intersection areas which require a wide range of field view. For this reason, fish eye cameras are widely used in real time vehicle detection purpose to provide large area coverage and 360 degree view at junctions. However, it introduces challenges such as light glare from vehicles and street lights, shadow, non-linear distortion, scaling issues of vehicles and proper localization of small vehicles. To overcome each of these challenges, a modified YOLOv5 object detection scheme is proposed. YOLOv5 is a deep learning oriented convolutional neural network (CNN) based object detection method. The proposed scheme for detecting vehicles in fish-eye images consists of a light-weight day-night CNN classifier so that two different solutions can be implemented to address the day-night detection issues. Furthurmore, challenging instances are upsampled in the dataset for proper localization of vehicles and later on the detection model is ensembled and trained in different combination of vehicle datasets for better generalization, detection and accuracy. For testing, a real world fisheye dataset provided by the Video and Image Processing (VIP) Cup organizer ISSD has been used which includes images from video clips of different fisheye cameras at junction of different cities during day and night time. Experimental results show that our proposed model has outperformed the YOLOv5 model on the dataset by 13.7% mAP @ 0.5.
SONICS: Synthetic Or Not -- Identifying Counterfeit Songs
Aug 27, 2024The recent surge in AI-generated songs presents exciting possibilities and challenges. While these tools democratize music creation, they also necessitate the ability to distinguish between human-composed and AI-generated songs for safeguarding artistic integrity and content curation. Existing research and datasets in fake song detection only focus on singing voice deepfake detection (SVDD), where the vocals are AI-generated but the instrumental music is sourced from real songs. However, this approach is inadequate for contemporary end-to-end AI-generated songs where all components (vocals, lyrics, music, and style) could be AI-generated. Additionally, existing datasets lack lyrics-music diversity, long-duration songs, and open fake songs. To address these gaps, we introduce SONICS, a novel dataset for end-to-end Synthetic Song Detection (SSD), comprising over 97k songs with over 49k synthetic songs from popular platforms like Suno and Udio. Furthermore, we highlight the importance of modeling long-range temporal dependencies in songs for effective authenticity detection, an aspect overlooked in existing methods. To capture these patterns, we propose a novel model, SpecTTTra, that is up to 3 times faster and 6 times more memory efficient compared to popular CNN and Transformer-based models while maintaining competitive performance. Finally, we offer both AI-based and Human evaluation benchmarks, addressing another deficiency in current research.
Npix2Cpix: A GAN-based Image-to-Image Translation Network with Retrieval-Classification Integration for Watermark Retrieval from Historical Document Images
Jun 05, 2024


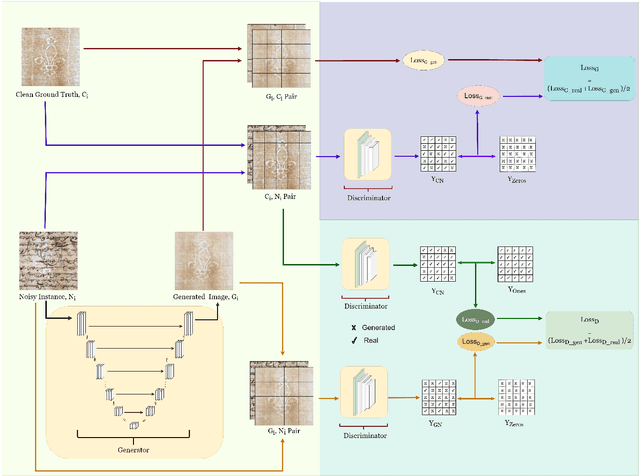
The identification and restoration of ancient watermarks have long been a major topic in codicology and history. Classifying historical documents based on watermarks can be difficult due to the diversity of watermarks, crowded and noisy samples, multiple modes of representation, and minor distinctions between classes and intra-class changes. This paper proposes a U-net-based conditional generative adversarial network (GAN) to translate noisy raw historical watermarked images into clean, handwriting-free images with just watermarks. Considering its ability to perform image translation from degraded (noisy) pixels to clean pixels, the proposed network is termed as Npix2Cpix. Instead of employing directly degraded watermarked images, the proposed network uses image-to-image translation using adversarial learning to create clutter and handwriting-free images for restoring and categorizing the watermarks for the first time. In order to learn the mapping from input noisy image to output clean image, the generator and discriminator of the proposed U-net-based GAN are trained using two separate loss functions, each of which is based on the distance between images. After using the proposed GAN to pre-process noisy watermarked images, Siamese-based one-shot learning is used to classify watermarks. According to experimental results on a large-scale historical watermark dataset, extracting watermarks from tainted images can result in high one-shot classification accuracy. The qualitative and quantitative evaluation of the retrieved watermarks illustrates the effectiveness of the proposed approach.
Decoding Human Activities: Analyzing Wearable Accelerometer and Gyroscope Data for Activity Recognition
Oct 03, 2023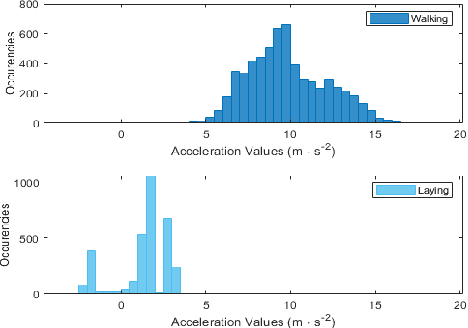
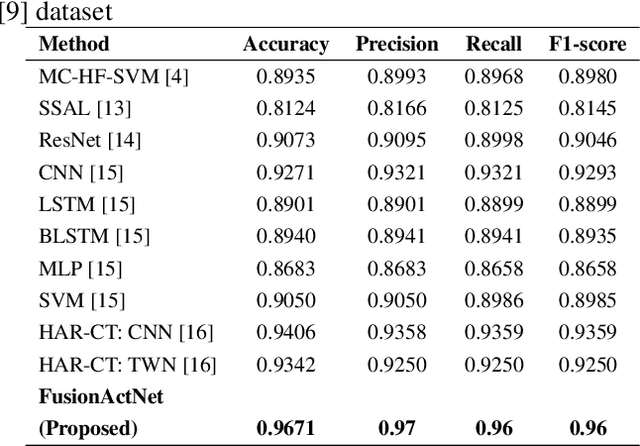
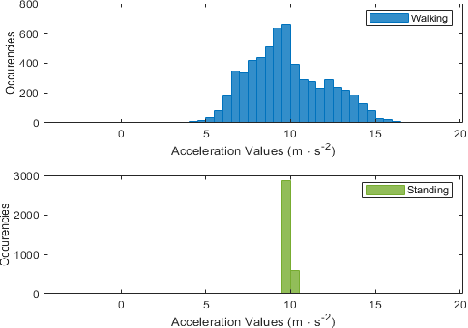
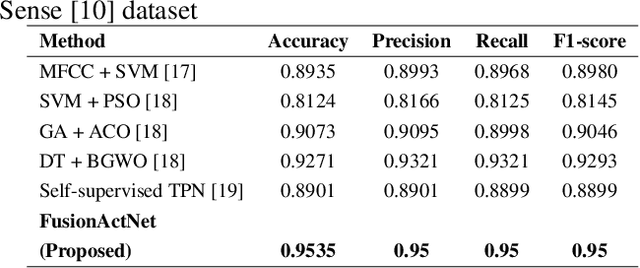
A person's movement or relative positioning effectively generates raw electrical signals that can be read by computing machines to apply various manipulative techniques for the classification of different human activities. In this paper, a stratified multi-structural approach based on a Residual network ensembled with Residual MobileNet is proposed, termed as FusionActNet. The proposed method involves using carefully designed Residual blocks for classifying the static and dynamic activities separately because they have clear and distinct characteristics that set them apart. These networks are trained independently, resulting in two specialized and highly accurate models. These models excel at recognizing activities within a specific superclass by taking advantage of the unique algorithmic benefits of architectural adjustments. Afterward, these two ResNets are passed through a weighted ensemble-based Residual MobileNet. Subsequently, this ensemble proficiently discriminates between a specific static and a specific dynamic activity, which were previously identified based on their distinct feature characteristics in the earlier stage. The proposed model is evaluated using two publicly accessible datasets; namely, UCI HAR and Motion-Sense. Therein, it successfully handled the highly confusing cases of data overlap. Therefore, the proposed approach achieves a state-of-the-art accuracy of 96.71% and 95.35% in the UCI HAR and Motion-Sense datasets respectively.
Syn-Att: Synthetic Speech Attribution via Semi-Supervised Unknown Multi-Class Ensemble of CNNs
Sep 15, 2023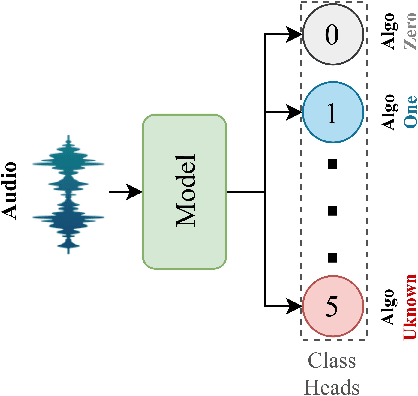
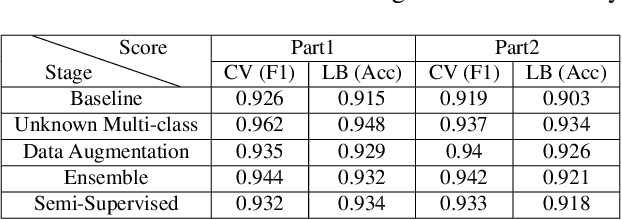
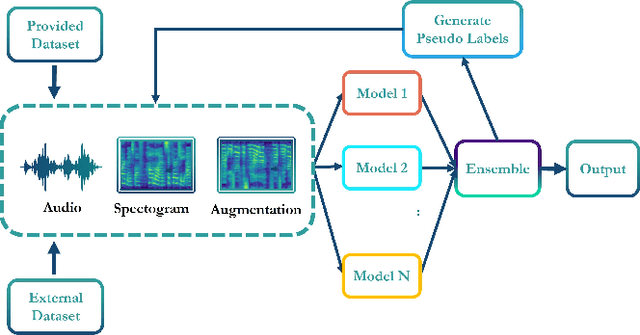
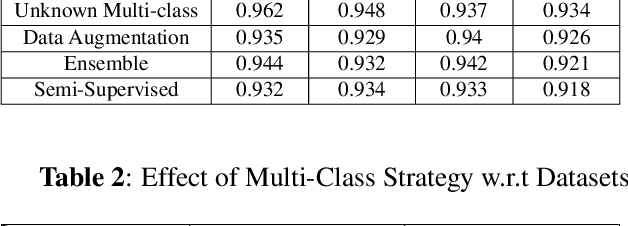
With the huge technological advances introduced by deep learning in audio & speech processing, many novel synthetic speech techniques achieved incredible realistic results. As these methods generate realistic fake human voices, they can be used in malicious acts such as people imitation, fake news, spreading, spoofing, media manipulations, etc. Hence, the ability to detect synthetic or natural speech has become an urgent necessity. Moreover, being able to tell which algorithm has been used to generate a synthetic speech track can be of preeminent importance to track down the culprit. In this paper, a novel strategy is proposed to attribute a synthetic speech track to the generator that is used to synthesize it. The proposed detector transforms the audio into log-mel spectrogram, extracts features using CNN, and classifies it between five known and unknown algorithms, utilizing semi-supervision and ensemble to improve its robustness and generalizability significantly. The proposed detector is validated on two evaluation datasets consisting of a total of 18,000 weakly perturbed (Eval 1) & 10,000 strongly perturbed (Eval 2) synthetic speeches. The proposed method outperforms other top teams in accuracy by 12-13% on Eval 2 and 1-2% on Eval 1, in the IEEE SP Cup challenge at ICASSP 2022.
Semi-Supervised Semantic Depth Estimation using Symbiotic Transformer and NearFarMix Augmentation
Aug 28, 2023In computer vision, depth estimation is crucial for domains like robotics, autonomous vehicles, augmented reality, and virtual reality. Integrating semantics with depth enhances scene understanding through reciprocal information sharing. However, the scarcity of semantic information in datasets poses challenges. Existing convolutional approaches with limited local receptive fields hinder the full utilization of the symbiotic potential between depth and semantics. This paper introduces a dataset-invariant semi-supervised strategy to address the scarcity of semantic information. It proposes the Depth Semantics Symbiosis module, leveraging the Symbiotic Transformer for achieving comprehensive mutual awareness by information exchange within both local and global contexts. Additionally, a novel augmentation, NearFarMix is introduced to combat overfitting and compensate both depth-semantic tasks by strategically merging regions from two images, generating diverse and structurally consistent samples with enhanced control. Extensive experiments on NYU-Depth-V2 and KITTI datasets demonstrate the superiority of our proposed techniques in indoor and outdoor environments.
Quantum Convolutional Neural Networks with Interaction Layers for Classification of Classical Data
Jul 20, 2023Quantum Machine Learning (QML) has come into the limelight due to the exceptional computational abilities of quantum computers. With the promises of near error-free quantum computers in the not-so-distant future, it is important that the effect of multi-qubit interactions on quantum neural networks is studied extensively. This paper introduces a Quantum Convolutional Network with novel Interaction layers exploiting three-qubit interactions increasing the network's expressibility and entangling capability, for classifying both image and one-dimensional data. The proposed approach is tested on three publicly available datasets namely MNIST, Fashion MNIST, and Iris datasets, to perform binary and multiclass classifications and is found to supersede the performance of the existing state-of-the-art methods.
CIFF-Net: Contextual Image Feature Fusion for Melanoma Diagnosis
Mar 07, 2023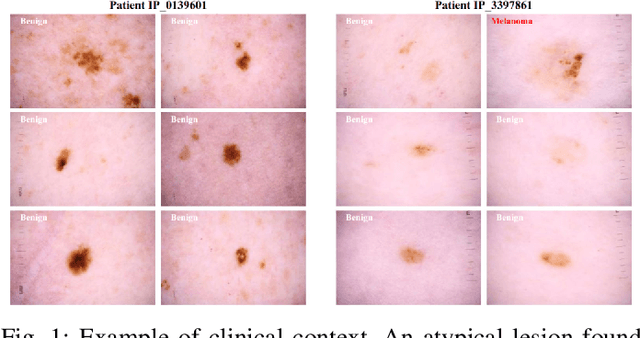
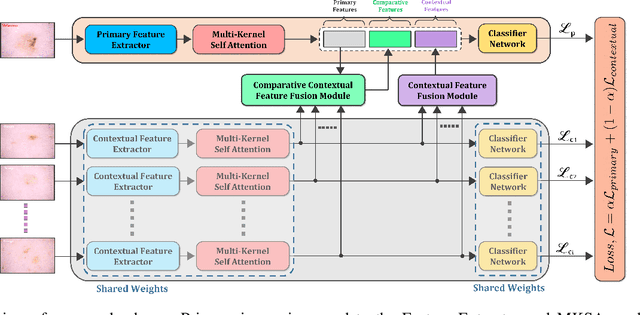
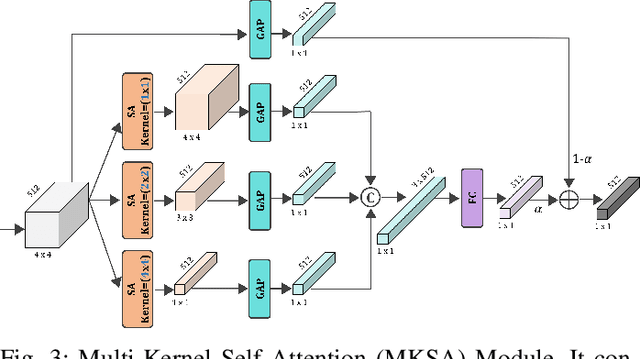
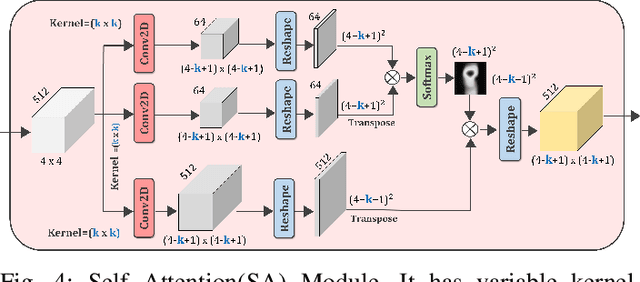
Melanoma is considered to be the deadliest variant of skin cancer causing around 75\% of total skin cancer deaths. To diagnose Melanoma, clinicians assess and compare multiple skin lesions of the same patient concurrently to gather contextual information regarding the patterns, and abnormality of the skin. So far this concurrent multi-image comparative method has not been explored by existing deep learning-based schemes. In this paper, based on contextual image feature fusion (CIFF), a deep neural network (CIFF-Net) is proposed, which integrates patient-level contextual information into the traditional approaches for improved Melanoma diagnosis by concurrent multi-image comparative method. The proposed multi-kernel self attention (MKSA) module offers better generalization of the extracted features by introducing multi-kernel operations in the self attention mechanisms. To utilize both self attention and contextual feature-wise attention, an attention guided module named contextual feature fusion (CFF) is proposed that integrates extracted features from different contextual images into a single feature vector. Finally, in comparative contextual feature fusion (CCFF) module, primary and contextual features are compared concurrently to generate comparative features. Significant improvement in performance has been achieved on the ISIC-2020 dataset over the traditional approaches that validate the effectiveness of the proposed contextual learning scheme.
DwinFormer: Dual Window Transformers for End-to-End Monocular Depth Estimation
Mar 07, 2023



Depth estimation from a single image is of paramount importance in the realm of computer vision, with a multitude of applications. Conventional methods suffer from the trade-off between consistency and fine-grained details due to the local-receptive field limiting their practicality. This lack of long-range dependency inherently comes from the convolutional neural network part of the architecture. In this paper, a dual window transformer-based network, namely DwinFormer, is proposed, which utilizes both local and global features for end-to-end monocular depth estimation. The DwinFormer consists of dual window self-attention and cross-attention transformers, Dwin-SAT and Dwin-CAT, respectively. The Dwin-SAT seamlessly extracts intricate, locally aware features while concurrently capturing global context. It harnesses the power of local and global window attention to adeptly capture both short-range and long-range dependencies, obviating the need for complex and computationally expensive operations, such as attention masking or window shifting. Moreover, Dwin-SAT introduces inductive biases which provide desirable properties, such as translational equvariance and less dependence on large-scale data. Furthermore, conventional decoding methods often rely on skip connections which may result in semantic discrepancies and a lack of global context when fusing encoder and decoder features. In contrast, the Dwin-CAT employs both local and global window cross-attention to seamlessly fuse encoder and decoder features with both fine-grained local and contextually aware global information, effectively amending semantic gap. Empirical evidence obtained through extensive experimentation on the NYU-Depth-V2 and KITTI datasets demonstrates the superiority of the proposed method, consistently outperforming existing approaches across both indoor and outdoor environments.