 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Trajectory Image for Multi-Month Trajectory Anomaly Detection
Mar 26, 2026Trajectory anomaly detection underpins applications from fraud detection to urban mobility analysis. Dense GPS methods preserve fine-grained evidence such as abnormal speeds and short-duration events, but their quadratic cost makes multi-month analysis intractable; consequently, no existing approach detects anomalies over multi-month dense GPS trajectories. The field instead relies on scalable sparse stay-point methods that discard this evidence, forcing separate architectures for each regime and preventing knowledge transfer. We argue this bottleneck is unnecessary: human trajectories, dense or sparse, share a natural two-dimensional cyclic structure along within-day and across-day axes. We therefore propose TITAnD (Trajectory Image Transformer for Anomaly Detection), which reformulates trajectory anomaly detection as a vision problem by representing trajectories as a Hyperspectral Trajectory Image (HTI): a day x time-of-day grid whose channels encode spatial, semantic, temporal, and kinematic information from either modality, unifying both under a single representation. Under this formulation, agent-level detection reduces to image classification and temporal localization to semantic segmentation. To model this representation, we introduce the Cyclic Factorized Transformer (CFT), which factorizes attention along the two temporal axes, encoding the cyclic inductive bias of human routines, while reducing attention cost by orders of magnitude and enabling dense multi-month anomaly detection for the first time. Empirically, TITAnD achieves the best AUC-PR across sparse and dense benchmarks, surpassing vision models like UNet while being 11-75x faster than the Transformer with comparable memory, demonstrating that vision reformulation and structure-aware modeling are jointly essential. Code will be made public soon.
LikeBench: Evaluating Subjective Likability in LLMs for Personalization
Dec 15, 2025A personalized LLM should remember user facts, apply them correctly, and adapt over time to provide responses that the user prefers. Existing LLM personalization benchmarks are largely centered on two axes: accurately recalling user information and accurately applying remembered information in downstream tasks. We argue that a third axis, likability, is both subjective and central to user experience, yet under-measured by current benchmarks. To measure likability holistically, we introduce LikeBench, a multi-session, dynamic evaluation framework that measures likability across multiple dimensions by how much an LLM can adapt over time to a user's preferences to provide more likable responses. In LikeBench, the LLMs engage in conversation with a simulated user and learn preferences only from the ongoing dialogue. As the interaction unfolds, models try to adapt to responses, and after each turn, they are evaluated for likability across seven dimensions by the same simulated user. To the best of our knowledge, we are the first to decompose likability into multiple diagnostic metrics: emotional adaptation, formality matching, knowledge adaptation, reference understanding, conversation length fit, humor fit, and callback, which makes it easier to pinpoint where a model falls short. To make the simulated user more realistic and discriminative, LikeBench uses fine-grained, psychologically grounded descriptive personas rather than the coarse high/low trait rating based personas used in prior work. Our benchmark shows that strong memory performance does not guarantee high likability: DeepSeek R1, with lower memory accuracy (86%, 17 facts/profile), outperformed Qwen3 by 28% on likability score despite Qwen3's higher memory accuracy (93%, 43 facts/profile). Even SOTA models like GPT-5 adapt well in short exchanges but show only limited robustness in longer, noisier interactions.
An Optimized YOLOv5 Based Approach For Real-time Vehicle Detection At Road Intersections Using Fisheye Cameras
Feb 06, 2025



Real time vehicle detection is a challenging task for urban traffic surveillance. Increase in urbanization leads to increase in accidents and traffic congestion in junction areas resulting in delayed travel time. In order to solve these problems, an intelligent system utilizing automatic detection and tracking system is significant. But this becomes a challenging task at road intersection areas which require a wide range of field view. For this reason, fish eye cameras are widely used in real time vehicle detection purpose to provide large area coverage and 360 degree view at junctions. However, it introduces challenges such as light glare from vehicles and street lights, shadow, non-linear distortion, scaling issues of vehicles and proper localization of small vehicles. To overcome each of these challenges, a modified YOLOv5 object detection scheme is proposed. YOLOv5 is a deep learning oriented convolutional neural network (CNN) based object detection method. The proposed scheme for detecting vehicles in fish-eye images consists of a light-weight day-night CNN classifier so that two different solutions can be implemented to address the day-night detection issues. Furthurmore, challenging instances are upsampled in the dataset for proper localization of vehicles and later on the detection model is ensembled and trained in different combination of vehicle datasets for better generalization, detection and accuracy. For testing, a real world fisheye dataset provided by the Video and Image Processing (VIP) Cup organizer ISSD has been used which includes images from video clips of different fisheye cameras at junction of different cities during day and night time. Experimental results show that our proposed model has outperformed the YOLOv5 model on the dataset by 13.7% mAP @ 0.5.
Temporally Consistent Dynamic Scene Graphs: An End-to-End Approach for Action Tracklet Generation
Dec 03, 2024



Understanding video content is pivotal for advancing real-world applications like activity recognition, autonomous systems, and human-computer interaction. While scene graphs are adept at capturing spatial relationships between objects in individual frames, extending these representations to capture dynamic interactions across video sequences remains a significant challenge. To address this, we present TCDSG, Temporally Consistent Dynamic Scene Graphs, an innovative end-to-end framework that detects, tracks, and links subject-object relationships across time, generating action tracklets, temporally consistent sequences of entities and their interactions. Our approach leverages a novel bipartite matching mechanism, enhanced by adaptive decoder queries and feedback loops, ensuring temporal coherence and robust tracking over extended sequences. This method not only establishes a new benchmark by achieving over 60% improvement in temporal recall@k on the Action Genome, OpenPVSG, and MEVA datasets but also pioneers the augmentation of MEVA with persistent object ID annotations for comprehensive tracklet generation. By seamlessly integrating spatial and temporal dynamics, our work sets a new standard in multi-frame video analysis, opening new avenues for high-impact applications in surveillance, autonomous navigation, and beyond.
SONICS: Synthetic Or Not -- Identifying Counterfeit Songs
Aug 27, 2024The recent surge in AI-generated songs presents exciting possibilities and challenges. While these tools democratize music creation, they also necessitate the ability to distinguish between human-composed and AI-generated songs for safeguarding artistic integrity and content curation. Existing research and datasets in fake song detection only focus on singing voice deepfake detection (SVDD), where the vocals are AI-generated but the instrumental music is sourced from real songs. However, this approach is inadequate for contemporary end-to-end AI-generated songs where all components (vocals, lyrics, music, and style) could be AI-generated. Additionally, existing datasets lack lyrics-music diversity, long-duration songs, and open fake songs. To address these gaps, we introduce SONICS, a novel dataset for end-to-end Synthetic Song Detection (SSD), comprising over 97k songs with over 49k synthetic songs from popular platforms like Suno and Udio. Furthermore, we highlight the importance of modeling long-range temporal dependencies in songs for effective authenticity detection, an aspect overlooked in existing methods. To capture these patterns, we propose a novel model, SpecTTTra, that is up to 3 times faster and 6 times more memory efficient compared to popular CNN and Transformer-based models while maintaining competitive performance. Finally, we offer both AI-based and Human evaluation benchmarks, addressing another deficiency in current research.
Syn-Att: Synthetic Speech Attribution via Semi-Supervised Unknown Multi-Class Ensemble of CNNs
Sep 15, 2023
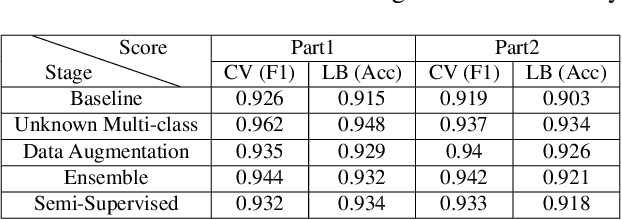
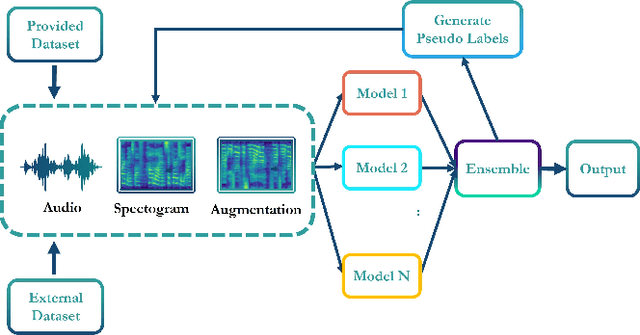
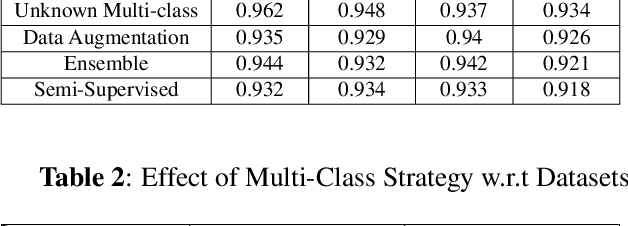
With the huge technological advances introduced by deep learning in audio & speech processing, many novel synthetic speech techniques achieved incredible realistic results. As these methods generate realistic fake human voices, they can be used in malicious acts such as people imitation, fake news, spreading, spoofing, media manipulations, etc. Hence, the ability to detect synthetic or natural speech has become an urgent necessity. Moreover, being able to tell which algorithm has been used to generate a synthetic speech track can be of preeminent importance to track down the culprit. In this paper, a novel strategy is proposed to attribute a synthetic speech track to the generator that is used to synthesize it. The proposed detector transforms the audio into log-mel spectrogram, extracts features using CNN, and classifies it between five known and unknown algorithms, utilizing semi-supervision and ensemble to improve its robustness and generalizability significantly. The proposed detector is validated on two evaluation datasets consisting of a total of 18,000 weakly perturbed (Eval 1) & 10,000 strongly perturbed (Eval 2) synthetic speeches. The proposed method outperforms other top teams in accuracy by 12-13% on Eval 2 and 1-2% on Eval 1, in the IEEE SP Cup challenge at ICASSP 2022.
Semi-Supervised Semantic Depth Estimation using Symbiotic Transformer and NearFarMix Augmentation
Aug 28, 2023In computer vision, depth estimation is crucial for domains like robotics, autonomous vehicles, augmented reality, and virtual reality. Integrating semantics with depth enhances scene understanding through reciprocal information sharing. However, the scarcity of semantic information in datasets poses challenges. Existing convolutional approaches with limited local receptive fields hinder the full utilization of the symbiotic potential between depth and semantics. This paper introduces a dataset-invariant semi-supervised strategy to address the scarcity of semantic information. It proposes the Depth Semantics Symbiosis module, leveraging the Symbiotic Transformer for achieving comprehensive mutual awareness by information exchange within both local and global contexts. Additionally, a novel augmentation, NearFarMix is introduced to combat overfitting and compensate both depth-semantic tasks by strategically merging regions from two images, generating diverse and structurally consistent samples with enhanced control. Extensive experiments on NYU-Depth-V2 and KITTI datasets demonstrate the superiority of our proposed techniques in indoor and outdoor environments.
CIFF-Net: Contextual Image Feature Fusion for Melanoma Diagnosis
Mar 07, 2023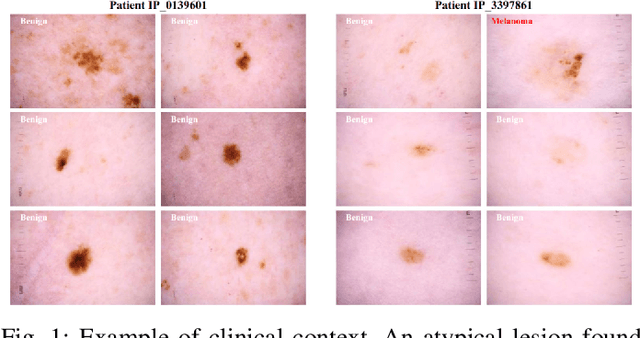
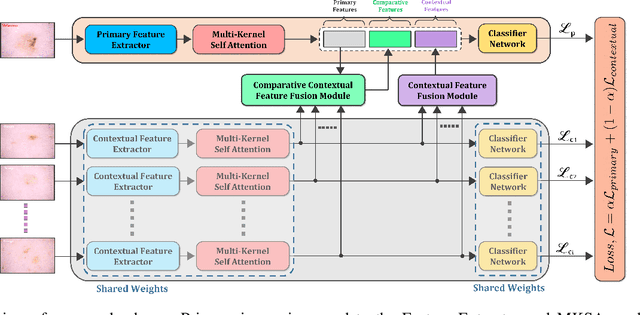
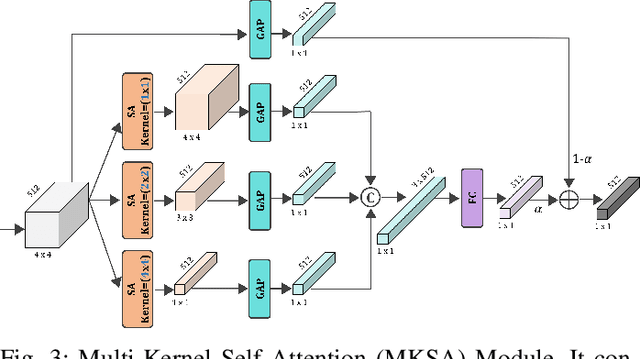
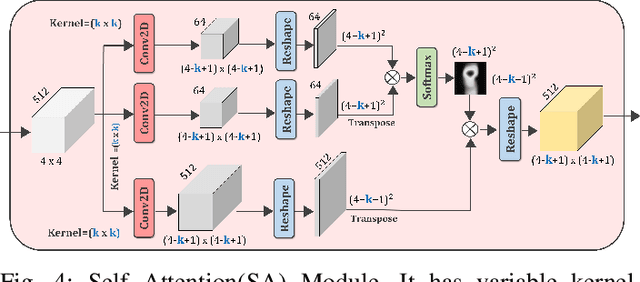
Melanoma is considered to be the deadliest variant of skin cancer causing around 75\% of total skin cancer deaths. To diagnose Melanoma, clinicians assess and compare multiple skin lesions of the same patient concurrently to gather contextual information regarding the patterns, and abnormality of the skin. So far this concurrent multi-image comparative method has not been explored by existing deep learning-based schemes. In this paper, based on contextual image feature fusion (CIFF), a deep neural network (CIFF-Net) is proposed, which integrates patient-level contextual information into the traditional approaches for improved Melanoma diagnosis by concurrent multi-image comparative method. The proposed multi-kernel self attention (MKSA) module offers better generalization of the extracted features by introducing multi-kernel operations in the self attention mechanisms. To utilize both self attention and contextual feature-wise attention, an attention guided module named contextual feature fusion (CFF) is proposed that integrates extracted features from different contextual images into a single feature vector. Finally, in comparative contextual feature fusion (CCFF) module, primary and contextual features are compared concurrently to generate comparative features. Significant improvement in performance has been achieved on the ISIC-2020 dataset over the traditional approaches that validate the effectiveness of the proposed contextual learning scheme.
DwinFormer: Dual Window Transformers for End-to-End Monocular Depth Estimation
Mar 07, 2023



Depth estimation from a single image is of paramount importance in the realm of computer vision, with a multitude of applications. Conventional methods suffer from the trade-off between consistency and fine-grained details due to the local-receptive field limiting their practicality. This lack of long-range dependency inherently comes from the convolutional neural network part of the architecture. In this paper, a dual window transformer-based network, namely DwinFormer, is proposed, which utilizes both local and global features for end-to-end monocular depth estimation. The DwinFormer consists of dual window self-attention and cross-attention transformers, Dwin-SAT and Dwin-CAT, respectively. The Dwin-SAT seamlessly extracts intricate, locally aware features while concurrently capturing global context. It harnesses the power of local and global window attention to adeptly capture both short-range and long-range dependencies, obviating the need for complex and computationally expensive operations, such as attention masking or window shifting. Moreover, Dwin-SAT introduces inductive biases which provide desirable properties, such as translational equvariance and less dependence on large-scale data. Furthermore, conventional decoding methods often rely on skip connections which may result in semantic discrepancies and a lack of global context when fusing encoder and decoder features. In contrast, the Dwin-CAT employs both local and global window cross-attention to seamlessly fuse encoder and decoder features with both fine-grained local and contextually aware global information, effectively amending semantic gap. Empirical evidence obtained through extensive experimentation on the NYU-Depth-V2 and KITTI datasets demonstrates the superiority of the proposed method, consistently outperforming existing approaches across both indoor and outdoor environments.
ArtiFact: A Large-Scale Dataset with Artificial and Factual Images for Generalizable and Robust Synthetic Image Detection
Feb 24, 2023



Synthetic image generation has opened up new opportunities but has also created threats in regard to privacy, authenticity, and security. Detecting fake images is of paramount importance to prevent illegal activities, and previous research has shown that generative models leave unique patterns in their synthetic images that can be exploited to detect them. However, the fundamental problem of generalization remains, as even state-of-the-art detectors encounter difficulty when facing generators never seen during training. To assess the generalizability and robustness of synthetic image detectors in the face of real-world impairments, this paper presents a large-scale dataset named ArtiFact, comprising diverse generators, object categories, and real-world challenges. Moreover, the proposed multi-class classification scheme, combined with a filter stride reduction strategy addresses social platform impairments and effectively detects synthetic images from both seen and unseen generators. The proposed solution significantly outperforms other top teams by 8.34% on Test 1, 1.26% on Test 2, and 15.08% on Test 3 in the IEEE VIP Cup challenge at ICIP 2022, as measured by the accuracy metric.