 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Trajectory Image for Multi-Month Trajectory Anomaly Detection
Mar 26, 2026Trajectory anomaly detection underpins applications from fraud detection to urban mobility analysis. Dense GPS methods preserve fine-grained evidence such as abnormal speeds and short-duration events, but their quadratic cost makes multi-month analysis intractable; consequently, no existing approach detects anomalies over multi-month dense GPS trajectories. The field instead relies on scalable sparse stay-point methods that discard this evidence, forcing separate architectures for each regime and preventing knowledge transfer. We argue this bottleneck is unnecessary: human trajectories, dense or sparse, share a natural two-dimensional cyclic structure along within-day and across-day axes. We therefore propose TITAnD (Trajectory Image Transformer for Anomaly Detection), which reformulates trajectory anomaly detection as a vision problem by representing trajectories as a Hyperspectral Trajectory Image (HTI): a day x time-of-day grid whose channels encode spatial, semantic, temporal, and kinematic information from either modality, unifying both under a single representation. Under this formulation, agent-level detection reduces to image classification and temporal localization to semantic segmentation. To model this representation, we introduce the Cyclic Factorized Transformer (CFT), which factorizes attention along the two temporal axes, encoding the cyclic inductive bias of human routines, while reducing attention cost by orders of magnitude and enabling dense multi-month anomaly detection for the first time. Empirically, TITAnD achieves the best AUC-PR across sparse and dense benchmarks, surpassing vision models like UNet while being 11-75x faster than the Transformer with comparable memory, demonstrating that vision reformulation and structure-aware modeling are jointly essential. Code will be made public soon.
Wrivinder: Towards Spatial Intelligence for Geo-locating Ground Images onto Satellite Imagery
Feb 16, 2026Aligning ground-level imagery with geo-registered satellite maps is crucial for mapping, navigation, and situational awareness, yet remains challenging under large viewpoint gaps or when GPS is unreliable. We introduce Wrivinder, a zero-shot, geometry-driven framework that aggregates multiple ground photographs to reconstruct a consistent 3D scene and align it with overhead satellite imagery. Wrivinder combines SfM reconstruction, 3D Gaussian Splatting, semantic grounding, and monocular depth--based metric cues to produce a stable zenith-view rendering that can be directly matched to satellite context for metrically accurate camera geo-localization. To support systematic evaluation of this task, which lacks suitable benchmarks, we also release MC-Sat, a curated dataset linking multi-view ground imagery with geo-registered satellite tiles across diverse outdoor environments. Together, Wrivinder and MC-Sat provide a first comprehensive baseline and testbed for studying geometry-centered cross-view alignment without paired supervision. In zero-shot experiments, Wrivinder achieves sub-30\,m geolocation accuracy across both dense and large-area scenes, highlighting the promise of geometry-based aggregation for robust ground-to-satellite localization.
A Lightweight CNN-Attention-BiLSTM Architecture for Multi-Class Arrhythmia Classification on Standard and Wearable ECGs
Nov 11, 2025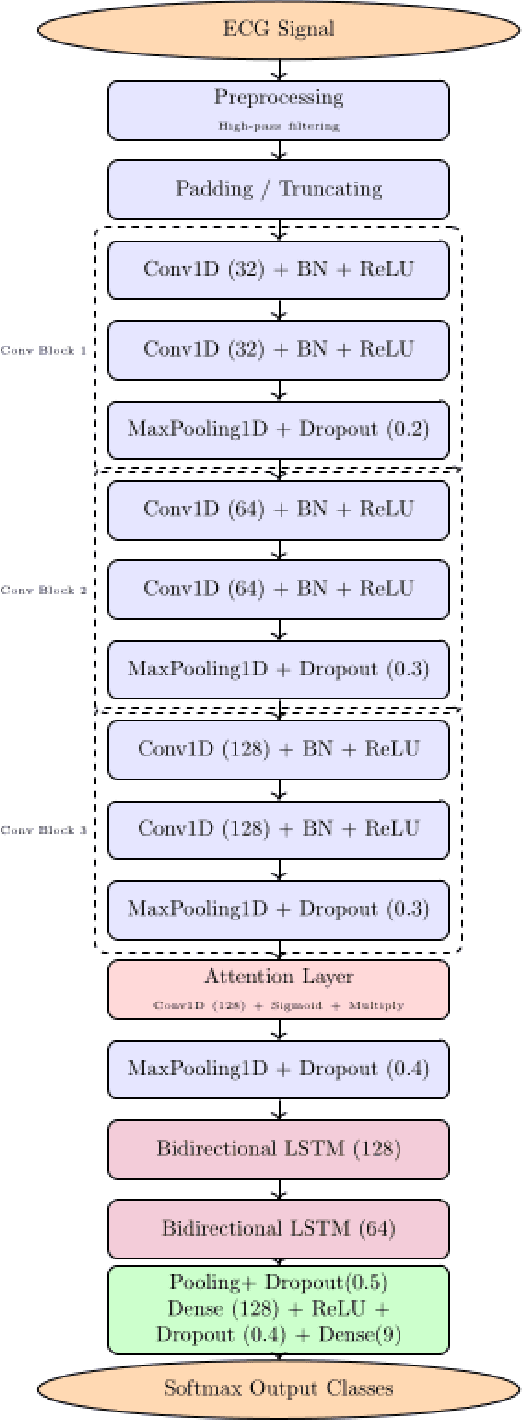
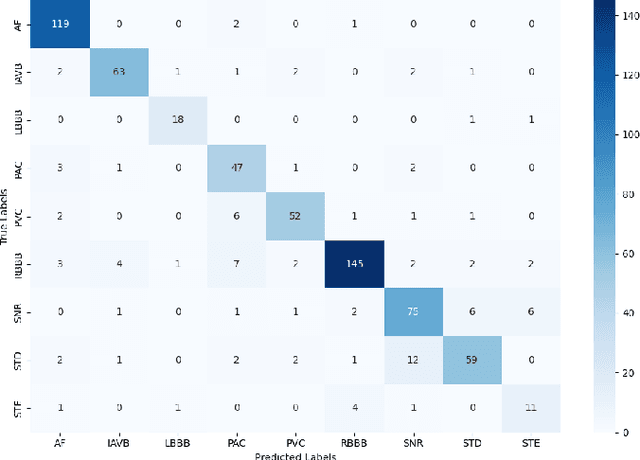
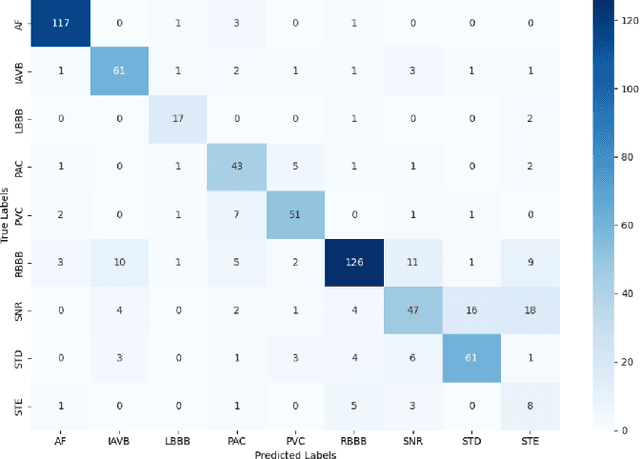
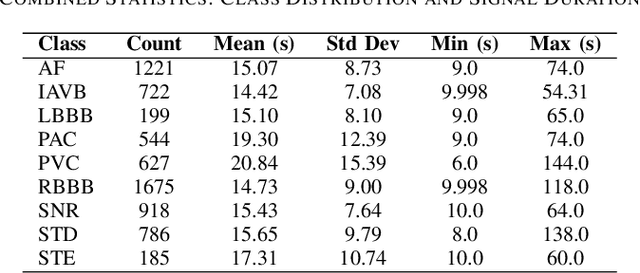
Early and accurate detection of cardiac arrhythmias is vital for timely diagnosis and intervention. We propose a lightweight deep learning model combining 1D Convolutional Neural Networks (CNN), attention mechanisms, and Bidirectional Long Short-Term Memory (BiLSTM) for classifying arrhythmias from both 12-lead and single-lead ECGs. Evaluated on the CPSC 2018 dataset, the model addresses class imbalance using a class-weighted loss and demonstrates superior accuracy and F1- scores over baseline models. With only 0.945 million parameters, our model is well-suited for real-time deployment in wearable health monitoring systems.
Temporally Consistent Dynamic Scene Graphs: An End-to-End Approach for Action Tracklet Generation
Dec 03, 2024



Understanding video content is pivotal for advancing real-world applications like activity recognition, autonomous systems, and human-computer interaction. While scene graphs are adept at capturing spatial relationships between objects in individual frames, extending these representations to capture dynamic interactions across video sequences remains a significant challenge. To address this, we present TCDSG, Temporally Consistent Dynamic Scene Graphs, an innovative end-to-end framework that detects, tracks, and links subject-object relationships across time, generating action tracklets, temporally consistent sequences of entities and their interactions. Our approach leverages a novel bipartite matching mechanism, enhanced by adaptive decoder queries and feedback loops, ensuring temporal coherence and robust tracking over extended sequences. This method not only establishes a new benchmark by achieving over 60% improvement in temporal recall@k on the Action Genome, OpenPVSG, and MEVA datasets but also pioneers the augmentation of MEVA with persistent object ID annotations for comprehensive tracklet generation. By seamlessly integrating spatial and temporal dynamics, our work sets a new standard in multi-frame video analysis, opening new avenues for high-impact applications in surveillance, autonomous navigation, and beyond.
A Tiny Machine Learning Model for Point Cloud Object Classification
Mar 20, 2023


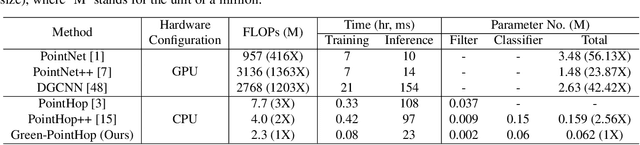
The design of a tiny machine learning model, which can be deployed in mobile and edge devices, for point cloud object classification is investigated in this work. To achieve this objective, we replace the multi-scale representation of a point cloud object with a single-scale representation for complexity reduction, and exploit rich 3D geometric information of a point cloud object for performance improvement. The proposed solution is named Green-PointHop due to its low computational complexity. We evaluate the performance of Green-PointHop on ModelNet40 and ScanObjectNN two datasets. Green-PointHop has a model size of 64K parameters. It demands 2.3M floating-point operations (FLOPs) to classify a ModelNet40 object of 1024 down-sampled points. Its classification performance gaps against the state-of-the-art DGCNN method are 3% and 7% for ModelNet40 and ScanObjectNN, respectively. On the other hand, the model size and inference complexity of DGCNN are 42X and 1203X of those of Green-PointHop, respectively.
S3I-PointHop: SO-Invariant PointHop for 3D Point Cloud Classification
Feb 22, 2023Many point cloud classification methods are developed under the assumption that all point clouds in the dataset are well aligned with the canonical axes so that the 3D Cartesian point coordinates can be employed to learn features. When input point clouds are not aligned, the classification performance drops significantly. In this work, we focus on a mathematically transparent point cloud classification method called PointHop, analyze its reason for failure due to pose variations, and solve the problem by replacing its pose dependent modules with rotation invariant counterparts. The proposed method is named SO(3)-Invariant PointHop (or S3I-PointHop in short). We also significantly simplify the PointHop pipeline using only one single hop along with multiple spatial aggregation techniques. The idea of exploiting more spatial information is novel. Experiments on the ModelNet40 dataset demonstrate the superiority of S3I-PointHop over traditional PointHop-like methods.