 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tiny Machine Learning Model for Point Cloud Object Classification
Mar 20, 2023


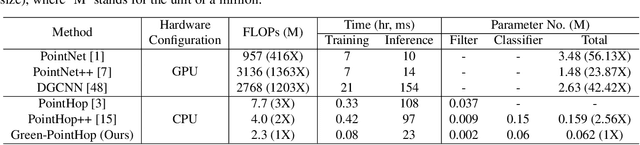
The design of a tiny machine learning model, which can be deployed in mobile and edge devices, for point cloud object classification is investigated in this work. To achieve this objective, we replace the multi-scale representation of a point cloud object with a single-scale representation for complexity reduction, and exploit rich 3D geometric information of a point cloud object for performance improvement. The proposed solution is named Green-PointHop due to its low computational complexity. We evaluate the performance of Green-PointHop on ModelNet40 and ScanObjectNN two datasets. Green-PointHop has a model size of 64K parameters. It demands 2.3M floating-point operations (FLOPs) to classify a ModelNet40 object of 1024 down-sampled points. Its classification performance gaps against the state-of-the-art DGCNN method are 3% and 7% for ModelNet40 and ScanObjectNN, respectively. On the other hand, the model size and inference complexity of DGCNN are 42X and 1203X of those of Green-PointHop, respectively.
PointFlowHop: Green and Interpretable Scene Flow Estimation from Consecutive Point Clouds
Feb 27, 2023



An efficient 3D scene flow estimation method called PointFlowHop is proposed in this work. PointFlowHop takes two consecutive point clouds and determines the 3D flow vectors for every point in the first point cloud. PointFlowHop decomposes the scene flow estimation task into a set of subtasks, including ego-motion compensation, object association and object-wise motion estimation. It follows the green learning (GL) pipeline and adopts the feedforward data processing path. As a result, its underlying mechanism is more transparent than deep-learning (DL) solutions based on end-to-end optimization of network parameters. We conduct experiments on the stereoKITTI and the Argoverse LiDAR point cloud datasets and demonstrate that PointFlowHop outperforms deep-learning methods with a small model size and less training time. Furthermore, we compare the Floating Point Operations (FLOPs) required by PointFlowHop and other learning-based methods in inference, and show its big savings in computational complexity.
S3I-PointHop: SO-Invariant PointHop for 3D Point Cloud Classification
Feb 22, 2023Many point cloud classification methods are developed under the assumption that all point clouds in the dataset are well aligned with the canonical axes so that the 3D Cartesian point coordinates can be employed to learn features. When input point clouds are not aligned, the classification performance drops significantly. In this work, we focus on a mathematically transparent point cloud classification method called PointHop, analyze its reason for failure due to pose variations, and solve the problem by replacing its pose dependent modules with rotation invariant counterparts. The proposed method is named SO(3)-Invariant PointHop (or S3I-PointHop in short). We also significantly simplify the PointHop pipeline using only one single hop along with multiple spatial aggregation techniques. The idea of exploiting more spatial information is novel. Experiments on the ModelNet40 dataset demonstrate the superiority of S3I-PointHop over traditional PointHop-like methods.
PCRP: Unsupervised Point Cloud Object Retrieval and Pose Estimation
Feb 16, 2022

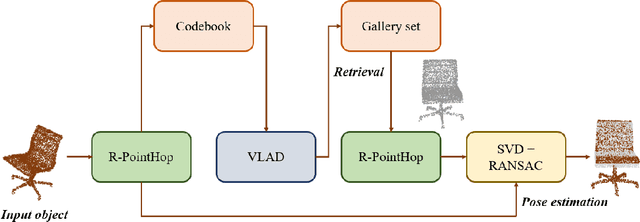

An unsupervised point cloud object retrieval and pose estimation method, called PCRP, is proposed in this work. It is assumed that there exists a gallery point cloud set that contains point cloud objects with given pose orientation information. PCRP attempts to register the unknown point cloud object with those in the gallery set so as to achieve content-based object retrieval and pose estimation jointly, where the point cloud registration task is built upon an enhanced version of the unsupervised R-PointHop method. Experiments on the ModelNet40 dataset demonstrate the superior performance of PCRP in comparison with traditional and learning based methods.
GPCO: An Unsupervised Green Point Cloud Odometry Method
Dec 08, 2021



Visual odometry aims to track the incremental motion of an object using the information captured by visual sensors. In this work, we study the point cloud odometry problem, where only the point cloud scans obtained by the LiDAR (Light Detection And Ranging) are used to estimate object's motion trajectory. A lightweight point cloud odometry solution is proposed and named the green point cloud odometry (GPCO) method. GPCO is an unsupervised learning method that predicts object motion by matching features of consecutive point cloud scans. It consists of three steps. First, a geometry-aware point sampling scheme is used to select discriminant points from the large point cloud. Second, the view is partitioned into four regions surrounding the object, and the PointHop++ method is used to extract point features. Third, point correspondences are established to estimate object motion between two consecutive scans. Experiments on the KITTI dataset are conducted to demonstrate the effectiveness of the GPCO method. It is observed that GPCO outperforms benchmarking deep learning methods in accuracy while it has a significantly smaller model size and less training time.
GSIP: Green Semantic Segmentation of Large-Scale Indoor Point Clouds
Sep 24, 2021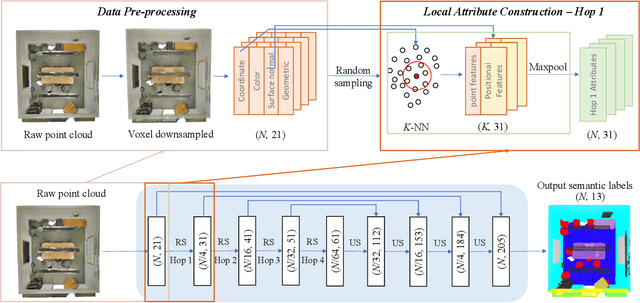



An efficient solution to semantic segmentation of large-scale indoor scene point clouds is proposed in this work. It is named GSIP (Green Segmentation of Indoor Point clouds) and its performance is evaluated on a representative large-scale benchmark -- the Stanford 3D Indoor Segmentation (S3DIS) dataset. GSIP has two novel components: 1) a room-style data pre-processing method that selects a proper subset of points for further processing, and 2) a new feature extractor which is extended from PointHop. For the former, sampled points of each room form an input unit. For the latter, the weaknesses of PointHop's feature extraction when extending it to large-scale point clouds are identified and fixed with a simpler processing pipeline. As compared with PointNet, which is a pioneering deep-learning-based solution, GSIP is green since it has significantly lower computational complexity and a much smaller model size. Furthermore, experiments show that GSIP outperforms PointNet in segmentation performance for the S3DIS dataset.
R-PointHop: A Green, Accurate and Unsupervised Point Cloud Registration Method
Mar 15, 2021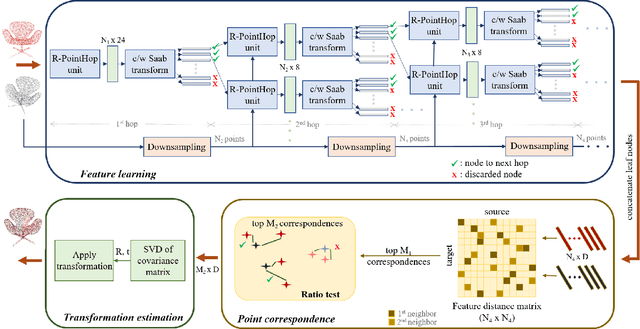
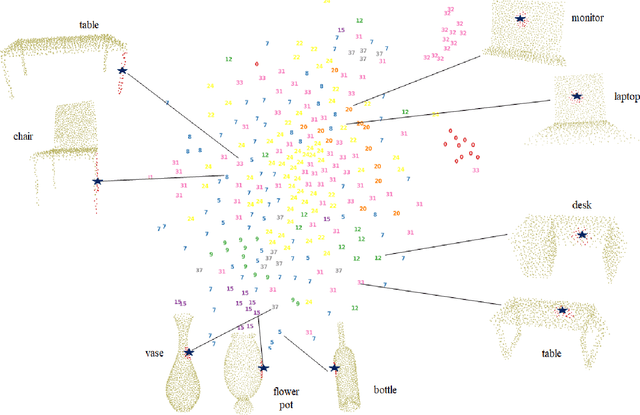

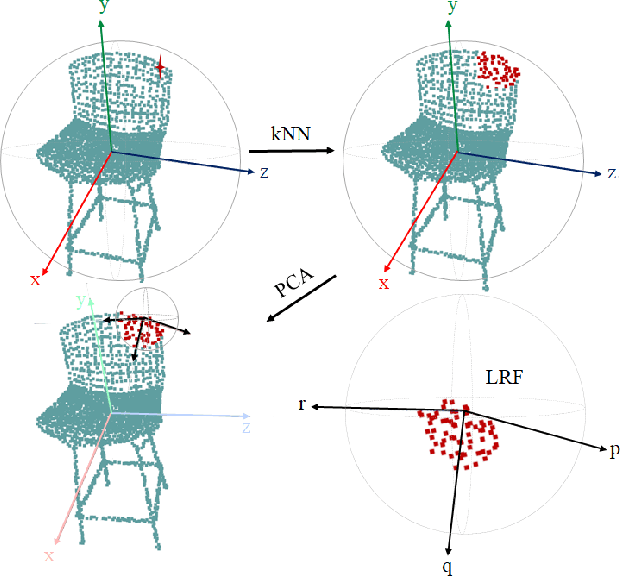
Inspired by the recent PointHop classification method, an unsupervised 3D point cloud registration method, called R-PointHop, is proposed in this work. R-PointHop first determines a local reference frame (LRF) for every point using its nearest neighbors and finds its local attributes. Next, R-PointHop obtains local-to-global hierarchical features by point downsampling, neighborhood expansion, attribute construction and dimensionality reduction steps. Thus, we can build the correspondence of points in the hierarchical feature space using the nearest neighbor rule. Afterwards, a subset of salient points of good correspondence is selected to estimate the 3D transformation. The use of LRF allows for hierarchical features of points to be invariant with respect to rotation and translation, thus making R-PointHop more robust in building point correspondence even when rotation angles are large. Experiments are conducted on the ModelNet40 and the Stanford Bunny dataset, which demonstrate the effectiveness of R-PointHop on the 3D point cloud registration task. R-PointHop is a green and accurate solution since its model size and training time are smaller than those of deep learning methods by an order of magnitude while its registration errors are smaller. Our codes are available on GitHub.
Unsupervised Point Cloud Registration via Salient Points Analysis (SPA)
Sep 02, 2020An unsupervised point cloud registration method, called salient points analysis (SPA), is proposed in this work. The proposed SPA method can register two point clouds effectively using only a small subset of salient points. It first applies the PointHop++ method to point clouds, finds corresponding salient points in two point clouds based on the local surface characteristics of points and performs registration by matching the corresponding salient points. The SPA method offers several advantages over the recent deep learning based solutions for registration. Deep learning methods such as PointNetLK and DCP train end-to-end networks and rely on full supervision (namely, ground truth transformation matrix and class label). In contrast, the SPA is completely unsupervised. Furthermore, SPA's training time and model size are much less. The effectiveness of the SPA method is demonstrated by experiments on seen and unseen classes and noisy point clouds from the ModelNet-40 dataset.
Unsupervised Feedforward Feature (UFF) Learning for Point Cloud Classification and Segmentation
Sep 02, 2020In contrast to supervised backpropagation-based feature learning in deep neural networks (DNNs), an unsupervised feedforward feature (UFF) learning scheme for joint classification and segmentation of 3D point clouds is proposed in this work. The UFF method exploits statistical correlations of points in a point cloud set to learn shape and point features in a one-pass feedforward manner through a cascaded encoder-decoder architecture. It learns global shape features through the encoder and local point features through the concatenated encoder-decoder architecture. The extracted features of an input point cloud are fed to classifiers for shape classification and part segmentation. Experiments are conducted to evaluate the performance of the UFF method. For shape classification, the UFF is superior to existing unsupervised methods and on par with state-of-the-art DNNs. For part segmentation, the UFF outperforms semi-supervised methods and performs slightly worse than DNNs.
PointHop++: A Lightweight Learning Model on Point Sets for 3D Classification
Feb 09, 2020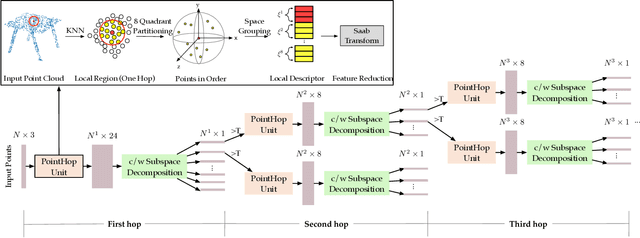
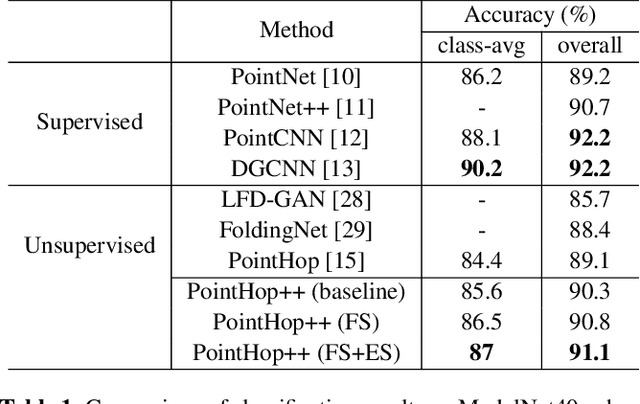


The PointHop method was recently proposed by Zhang et al. for 3D point cloud classification with unsupervised feature extraction. It has an extremely low training complexity while achieving state-of-the-art classification performance. In this work, we improve the PointHop method furthermore in two aspects: 1) reducing its model complexity in terms of the model parameter number and 2) ordering discriminant features automatically based on the cross-entropy criterion. The resulting method is called PointHop++. The first improvement is essential for wearable and mobile computing while the second improvement bridges statistics-based and optimization-based machine learning methodologies. With experiments conducted on the ModelNet40 benchmark dataset, we show that the PointHop++ method performs on par with deep neural network (DNN) solutions and surpasses other unsupervised feature extraction methods.