 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAllTracker: Efficient Dense Point Tracking at High Resolution
Jun 08, 2025We introduce AllTracker: a model that estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame. We develop a new architecture for this task, blending techniques from existing work in optical flow and point tracking: the model performs iterative inference on low-resolution grids of correspondence estimates, propagating information spatially via 2D convolution layers, and propagating information temporally via pixel-aligned attention layers. The model is fast and parameter-efficient (16 million parameters), and delivers state-of-the-art point tracking accuracy at high resolution (i.e., tracking 768x1024 pixels, on a 40G GPU). A benefit of our design is that we can train on a wider set of datasets, and we find that doing so is crucial for top performance. We provide an extensive ablation study on our architecture details and training recipe, making it clear which details matter most. Our code and model weights are available at https://alltracker.github.io .
Feature4X: Bridging Any Monocular Video to 4D Agentic AI with Versatile Gaussian Feature Fields
Mar 26, 2025Recent advancements in 2D and multimodal models have achieved remarkable success by leveraging large-scale training on extensive datasets. However, extending these achievements to enable free-form interactions and high-level semantic operations with complex 3D/4D scenes remains challenging. This difficulty stems from the limited availability of large-scale, annotated 3D/4D or multi-view datasets, which are crucial for generalizable vision and language tasks such as open-vocabulary and prompt-based segmentation, language-guided editing, and visual question answering (VQA). In this paper, we introduce Feature4X, a universal framework designed to extend any functionality from 2D vision foundation model into the 4D realm, using only monocular video input, which is widely available from user-generated content. The "X" in Feature4X represents its versatility, enabling any task through adaptable, model-conditioned 4D feature field distillation. At the core of our framework is a dynamic optimization strategy that unifies multiple model capabilities into a single representation. Additionally, to the best of our knowledge, Feature4X is the first method to distill and lift the features of video foundation models (e.g. SAM2, InternVideo2) into an explicit 4D feature field using Gaussian Splatting. Our experiments showcase novel view segment anything, geometric and appearance scene editing, and free-form VQA across all time steps, empowered by LLMs in feedback loops. These advancements broaden the scope of agentic AI applications by providing a foundation for scalable, contextually and spatiotemporally aware systems capable of immersive dynamic 4D scene interaction.
CAM-Seg: A Continuous-valued Embedding Approach for Semantic Image Generation
Mar 19, 2025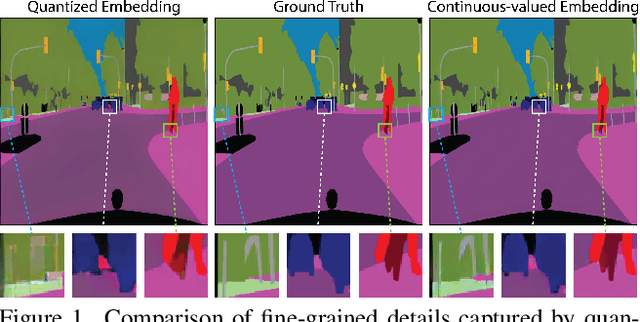
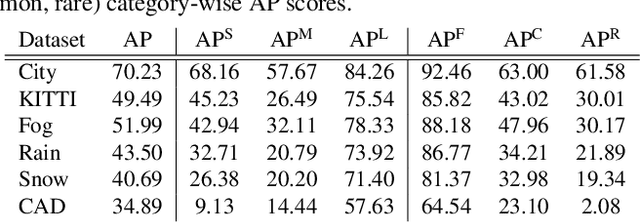
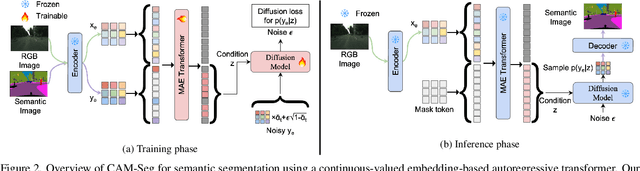
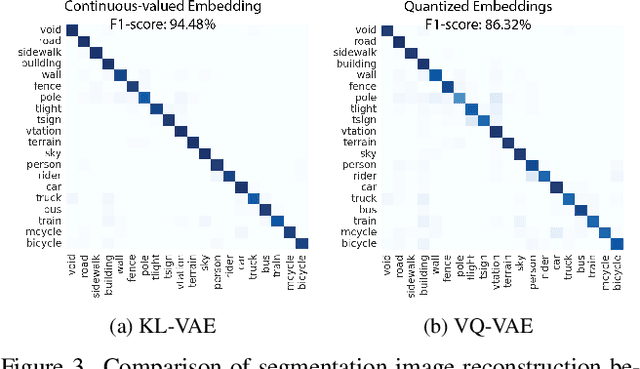
Traditional transformer-based semantic segmentation relies on quantized embeddings. However, our analysis reveals that autoencoder accuracy on segmentation mask using quantized embeddings (e.g. VQ-VAE) is 8% lower than continuous-valued embeddings (e.g. KL-VAE). Motivated by this, we propose a continuous-valued embedding framework for semantic segmentation. By reformulating semantic mask generation as a continuous image-to-embedding diffusion process, our approach eliminates the need for discrete latent representations while preserving fine-grained spatial and semantic details. Our key contribution includes a diffusion-guided autoregressive transformer that learns a continuous semantic embedding space by modeling long-range dependencies in image features. Our framework contains a unified architecture combining a VAE encoder for continuous feature extraction, a diffusion-guided transformer for conditioned embedding generation, and a VAE decoder for semantic mask reconstruction. Our setting facilitates zero-shot domain adaptation capabilities enabled by the continuity of the embedding space. Experiments across diverse datasets (e.g., Cityscapes and domain-shifted variants) demonstrate state-of-the-art robustness to distribution shifts, including adverse weather (e.g., fog, snow) and viewpoint variations. Our model also exhibits strong noise resilience, achieving robust performance ($\approx$ 95% AP compared to baseline) under gaussian noise, moderate motion blur, and moderate brightness/contrast variations, while experiencing only a moderate impact ($\approx$ 90% AP compared to baseline) from 50% salt and pepper noise, saturation and hue shifts. Code available: https://github.com/mahmed10/CAMSS.git
Green Video Camouflaged Object Detection
Jan 19, 2025Camouflaged object detection (COD) aims to distinguish hidden objects embedded in an environment highly similar to the object. Conventional video-based COD (VCOD) methods explicitly extract motion cues or employ complex deep learning networks to handle the temporal information, which is limited by high complexity and unstable performance. In this work, we propose a green VCOD method named GreenVCOD. Built upon a green ICOD method, GreenVCOD uses long- and short-term temporal neighborhoods (TN) to capture joint spatial/temporal context information for decision refinement. Experimental results show that GreenVCOD offers competitive performance compared to state-of-the-art VCOD benchmarks.
Temporally Consistent Dynamic Scene Graphs: An End-to-End Approach for Action Tracklet Generation
Dec 03, 2024



Understanding video content is pivotal for advancing real-world applications like activity recognition, autonomous systems, and human-computer interaction. While scene graphs are adept at capturing spatial relationships between objects in individual frames, extending these representations to capture dynamic interactions across video sequences remains a significant challenge. To address this, we present TCDSG, Temporally Consistent Dynamic Scene Graphs, an innovative end-to-end framework that detects, tracks, and links subject-object relationships across time, generating action tracklets, temporally consistent sequences of entities and their interactions. Our approach leverages a novel bipartite matching mechanism, enhanced by adaptive decoder queries and feedback loops, ensuring temporal coherence and robust tracking over extended sequences. This method not only establishes a new benchmark by achieving over 60% improvement in temporal recall@k on the Action Genome, OpenPVSG, and MEVA datasets but also pioneers the augmentation of MEVA with persistent object ID annotations for comprehensive tracklet generation. By seamlessly integrating spatial and temporal dynamics, our work sets a new standard in multi-frame video analysis, opening new avenues for high-impact applications in surveillance, autonomous navigation, and beyond.
Efficient Human-Object-Interaction (EHOI) Detection via Interaction Label Coding and Conditional Decision
Aug 13, 2024Human-Object Interaction (HOI) detection is a fundamental task in image understanding. While deep-learning-based HOI methods provide high performance in terms of mean Average Precision (mAP), they are computationally expensive and opaque in training and inference processes. An Efficient HOI (EHOI) detector is proposed in this work to strike a good balance between detection performance, inference complexity, and mathematical transparency. EHOI is a two-stage method. In the first stage, it leverages a frozen object detector to localize the objects and extract various features as intermediate outputs. In the second stage, the first-stage outputs predict the interaction type using the XGBoost classifier. Our contributions include the application of error correction codes (ECCs) to encode rare interaction cases, which reduces the model size and the complexity of the XGBoost classifier in the second stage. Additionally, we provide a mathematical formulation of the relabeling and decision-making process. Apart from the architecture, we present qualitative results to explain the functionalities of the feedforward modules. Experimental results demonstrate the advantages of ECC-coded interaction labels and the excellent balance of detection performance and complexity of the proposed EHOI method.
Img2CAD: Reverse Engineering 3D CAD Models from Images through VLM-Assisted Conditional Factorization
Jul 19, 2024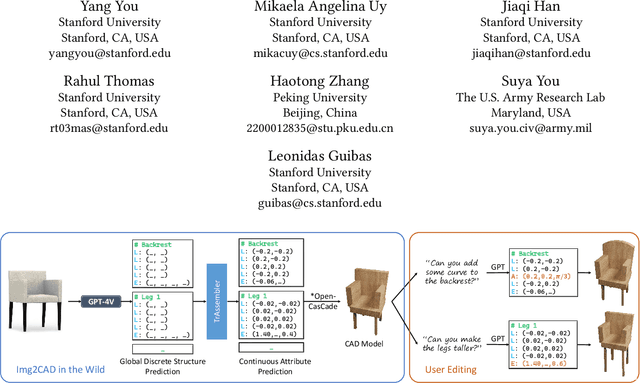
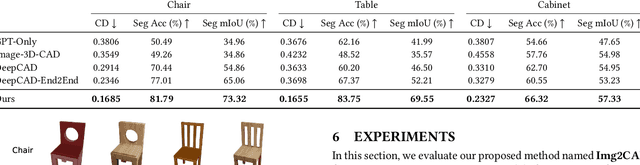
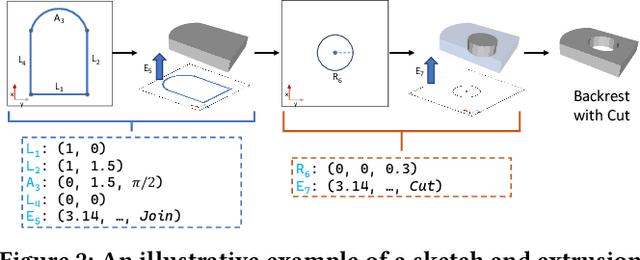

Reverse engineering 3D computer-aided design (CAD) models from images is an important task for many downstream applications including interactive editing, manufacturing, architecture, robotics, etc. The difficulty of the task lies in vast representational disparities between the CAD output and the image input. CAD models are precise, programmatic constructs that involves sequential operations combining discrete command structure with continuous attributes -- making it challenging to learn and optimize in an end-to-end fashion. Concurrently, input images introduce inherent challenges such as photo-metric variability and sensor noise, complicating the reverse engineering process. In this work, we introduce a novel approach that conditionally factorizes the task into two sub-problems. First, we leverage large foundation models, particularly GPT-4V, to predict the global discrete base structure with semantic information. Second, we propose TrAssembler that conditioned on the discrete structure with semantics predicts the continuous attribute values. To support the training of our TrAssembler, we further constructed an annotated CAD dataset of common objects from ShapeNet. Putting all together, our approach and data demonstrate significant first steps towards CAD-ifying images in the wild. Our project page: https://anonymous123342.github.io/
GreenCOD: A Green Camouflaged Object Detection Method
May 25, 2024



We introduce GreenCOD, a green method for detecting camouflaged objects, distinct in its avoidance of backpropagation techniques. GreenCOD leverages gradient boosting and deep features extracted from pre-trained Deep Neural Networks (DNNs). Traditional camouflaged object detection (COD) approaches often rely on complex deep neural network architectures, seeking performance improvements through backpropagation-based fine-tuning. However, such methods are typically computationally demanding and exhibit only marginal performance variations across different models. This raises the question of whether effective training can be achieved without backpropagation. Addressing this, our work proposes a new paradigm that utilizes gradient boosting for COD. This approach significantly simplifies the model design, resulting in a system that requires fewer parameters and operations and maintains high performance compared to state-of-the-art deep learning models. Remarkably, our models are trained without backpropagation and achieve the best performance with fewer than 20G Multiply-Accumulate Operations (MACs). This new, more efficient paradigm opens avenues for further exploration in green, backpropagation-free model training.
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Apr 10, 2024
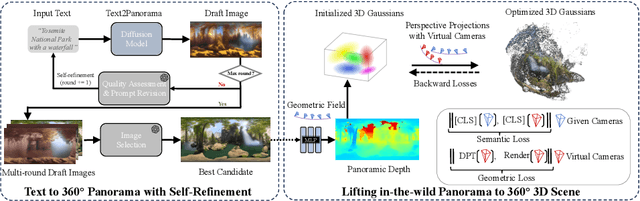
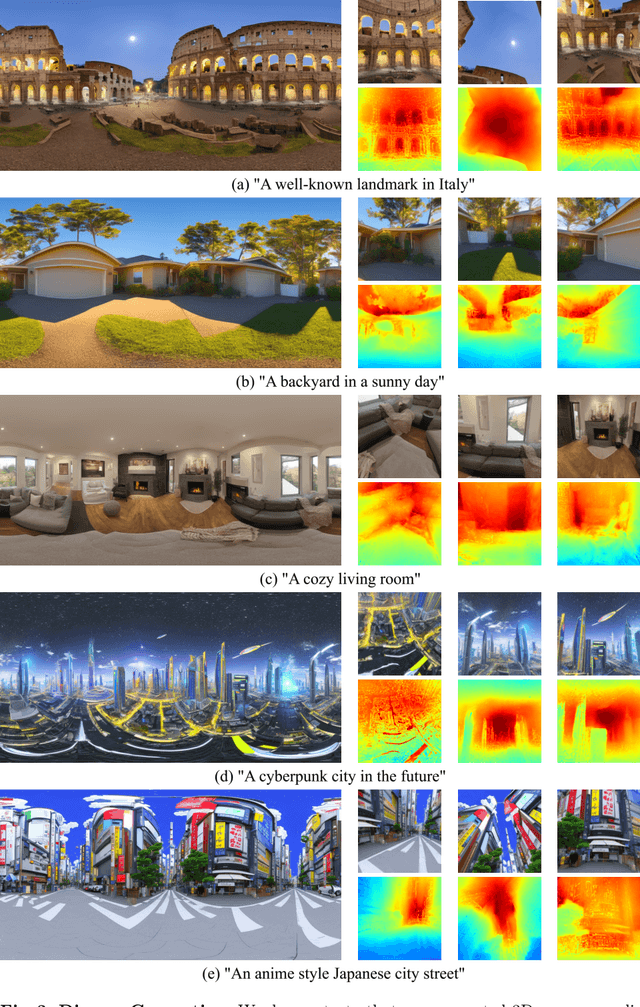

The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary "flat" (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
Feature 3DGS: Supercharging 3D Gaussian Splatting to Enable Distilled Feature Fields
Dec 06, 2023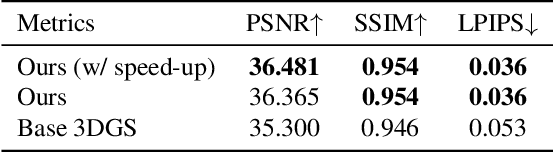
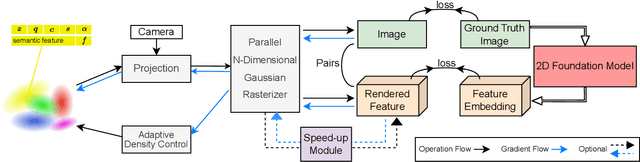
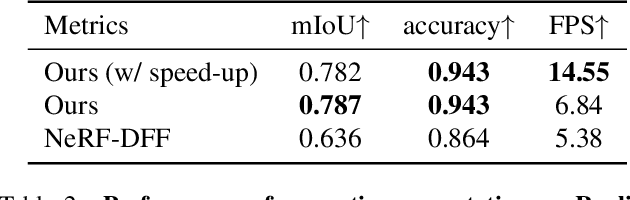
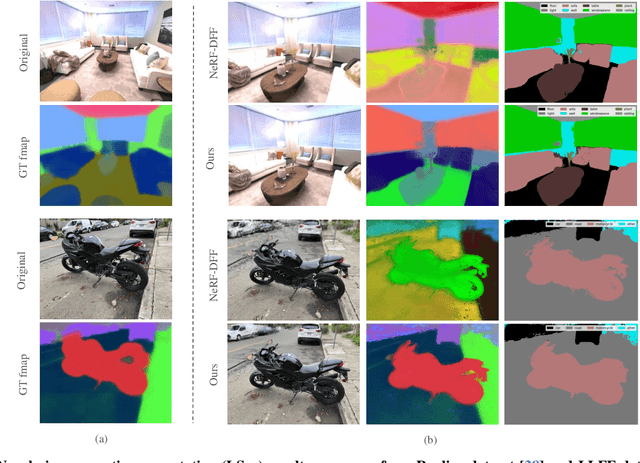
3D scene representations have gained immense popularity in recent years. Methods that use Neural Radiance fields are versatile for traditional tasks such as novel view synthesis. In recent times, some work has emerged that aims to extend the functionality of NeRF beyond view synthesis, for semantically aware tasks such as editing and segmentation using 3D feature field distillation from 2D foundation models. However, these methods have two major limitations: (a) they are limited by the rendering speed of NeRF pipelines, and (b) implicitly represented feature fields suffer from continuity artifacts reducing feature quality. Recently, 3D Gaussian Splatting has shown state-of-the-art performance on real-time radiance field rendering. In this work, we go one step further: in addition to radiance field rendering, we enable 3D Gaussian splatting on arbitrary-dimension semantic features via 2D foundation model distillation. This translation is not straightforward: naively incorporating feature fields in the 3DGS framework leads to warp-level divergence. We propose architectural and training changes to efficiently avert this problem. Our proposed method is general, and our experiments showcase novel view semantic segmentation, language-guided editing and segment anything through learning feature fields from state-of-the-art 2D foundation models such as SAM and CLIP-LSeg. Across experiments, our distillation method is able to provide comparable or better results, while being significantly faster to both train and render. Additionally, to the best of our knowledge, we are the first method to enable point and bounding-box prompting for radiance field manipulation, by leveraging the SAM model. Project website at: https://feature-3dgs.github.io/