 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Video Camouflaged Object Detection
Jan 19, 2025Camouflaged object detection (COD) aims to distinguish hidden objects embedded in an environment highly similar to the object. Conventional video-based COD (VCOD) methods explicitly extract motion cues or employ complex deep learning networks to handle the temporal information, which is limited by high complexity and unstable performance. In this work, we propose a green VCOD method named GreenVCOD. Built upon a green ICOD method, GreenVCOD uses long- and short-term temporal neighborhoods (TN) to capture joint spatial/temporal context information for decision refinement. Experimental results show that GreenVCOD offers competitive performance compared to state-of-the-art VCOD benchmarks.
GreenCOD: A Green Camouflaged Object Detection Method
May 25, 2024



We introduce GreenCOD, a green method for detecting camouflaged objects, distinct in its avoidance of backpropagation techniques. GreenCOD leverages gradient boosting and deep features extracted from pre-trained Deep Neural Networks (DNNs). Traditional camouflaged object detection (COD) approaches often rely on complex deep neural network architectures, seeking performance improvements through backpropagation-based fine-tuning. However, such methods are typically computationally demanding and exhibit only marginal performance variations across different models. This raises the question of whether effective training can be achieved without backpropagation. Addressing this, our work proposes a new paradigm that utilizes gradient boosting for COD. This approach significantly simplifies the model design, resulting in a system that requires fewer parameters and operations and maintains high performance compared to state-of-the-art deep learning models. Remarkably, our models are trained without backpropagation and achieve the best performance with fewer than 20G Multiply-Accumulate Operations (MACs). This new, more efficient paradigm opens avenues for further exploration in green, backpropagation-free model training.
Green Learning: Introduction, Examples and Outlook
Oct 03, 2022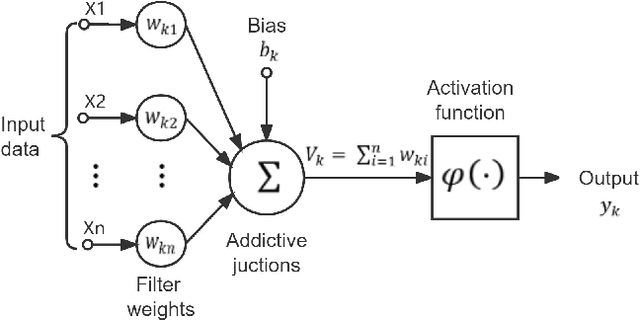
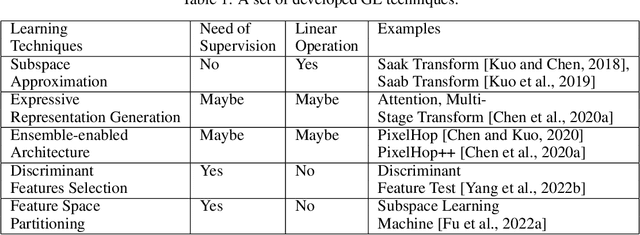
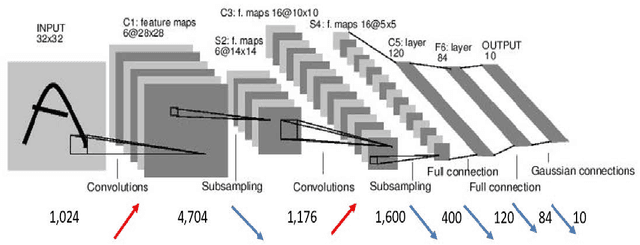

Rapid advances in artificial intelligence (AI) in the last decade have largely been built upon the wide applications of deep learning (DL). However, the high carbon footprint yielded by larger and larger DL networks becomes a concern for sustainability. Furthermore, DL decision mechanism is somewhat obsecure and can only be verified by test data. Green learning (GL) has been proposed as an alternative paradigm to address these concerns. GL is characterized by low carbon footprints, small model sizes, low computational complexity, and logical transparency. It offers energy-effective solutions in cloud centers as well as mobile/edge devices. GL also provides a clear and logical decision-making process to gain people's trust. Several statistical tools have been developed to achieve this goal in recent years. They include subspace approximation, unsupervised and supervised representation learning, supervised discriminant feature selection, and feature space partitioning. We have seen a few successful GL examples with performance comparable with state-of-the-art DL solutions. This paper offers an introduction to GL, its demonstrated applications, and future outlook.