 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Video Camouflaged Object Detection
Jan 19, 2025Camouflaged object detection (COD) aims to distinguish hidden objects embedded in an environment highly similar to the object. Conventional video-based COD (VCOD) methods explicitly extract motion cues or employ complex deep learning networks to handle the temporal information, which is limited by high complexity and unstable performance. In this work, we propose a green VCOD method named GreenVCOD. Built upon a green ICOD method, GreenVCOD uses long- and short-term temporal neighborhoods (TN) to capture joint spatial/temporal context information for decision refinement. Experimental results show that GreenVCOD offers competitive performance compared to state-of-the-art VCOD benchmarks.
GreenCOD: A Green Camouflaged Object Detection Method
May 25, 2024



We introduce GreenCOD, a green method for detecting camouflaged objects, distinct in its avoidance of backpropagation techniques. GreenCOD leverages gradient boosting and deep features extracted from pre-trained Deep Neural Networks (DNNs). Traditional camouflaged object detection (COD) approaches often rely on complex deep neural network architectures, seeking performance improvements through backpropagation-based fine-tuning. However, such methods are typically computationally demanding and exhibit only marginal performance variations across different models. This raises the question of whether effective training can be achieved without backpropagation. Addressing this, our work proposes a new paradigm that utilizes gradient boosting for COD. This approach significantly simplifies the model design, resulting in a system that requires fewer parameters and operations and maintains high performance compared to state-of-the-art deep learning models. Remarkably, our models are trained without backpropagation and achieve the best performance with fewer than 20G Multiply-Accumulate Operations (MACs). This new, more efficient paradigm opens avenues for further exploration in green, backpropagation-free model training.
Green Steganalyzer: A Green Learning Approach to Image Steganalysis
Jun 06, 2023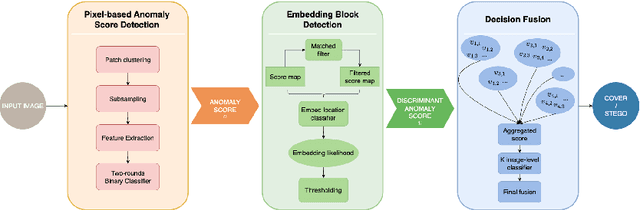



A novel learning solution to image steganalysis based on the green learning paradigm, called Green Steganalyzer (GS), is proposed in this work. GS consists of three modules: 1) pixel-based anomaly prediction, 2) embedding location detection, and 3) decision fusion for image-level detection. In the first module, GS decomposes an image into patches, adopts Saab transforms for feature extraction, and conducts self-supervised learning to predict an anomaly score of their center pixel. In the second module, GS analyzes the anomaly scores of a pixel and its neighborhood to find pixels of higher embedding probabilities. In the third module, GS focuses on pixels of higher embedding probabilities and fuses their anomaly scores to make final image-level classification. Compared with state-of-the-art deep-learning models, GS achieves comparable detection performance against S-UNIWARD, WOW and HILL steganography schemes with significantly lower computational complexity and a smaller model size, making it attractive for mobile/edge applications. Furthermore, GS is mathematically transparent because of its modular design.
DefakeHop++: An Enhanced Lightweight Deepfake Detector
Apr 30, 2022
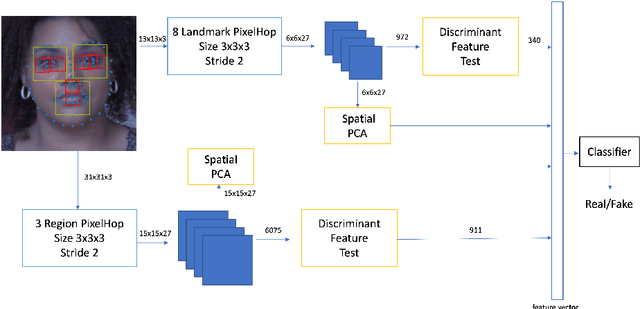
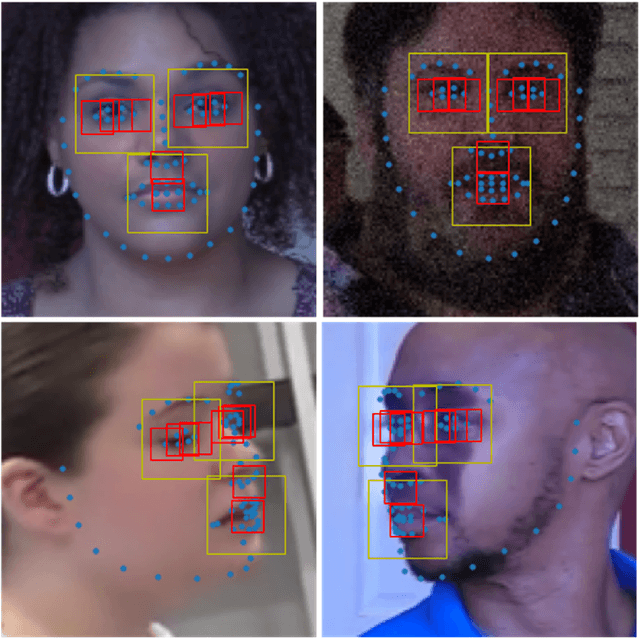
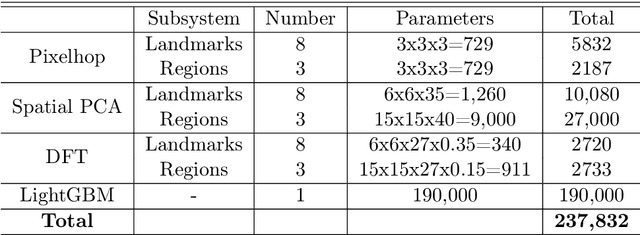
On the basis of DefakeHop, an enhanced lightweight Deepfake detector called DefakeHop++ is proposed in this work. The improvements lie in two areas. First, DefakeHop examines three facial regions (i.e., two eyes and mouth) while DefakeHop++ includes eight more landmarks for broader coverage. Second, for discriminant features selection, DefakeHop uses an unsupervised approach while DefakeHop++ adopts a more effective approach with supervision, called the Discriminant Feature Test (DFT). In DefakeHop++, rich spatial and spectral features are first derived from facial regions and landmarks automatically. Then, DFT is used to select a subset of discriminant features for classifier training. As compared with MobileNet v3 (a lightweight CNN model of 1.5M parameters targeting at mobile applications), DefakeHop++ has a model of 238K parameters, which is 16% of MobileNet v3. Furthermore, DefakeHop++ outperforms MobileNet v3 in Deepfake image detection performance in a weakly-supervised setting.
A-PixelHop: A Green, Robust and Explainable Fake-Image Detector
Nov 07, 2021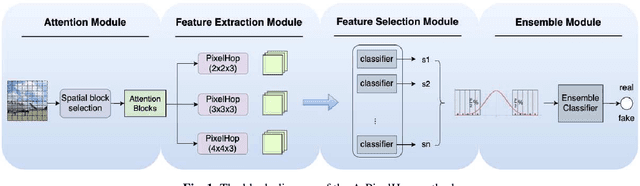


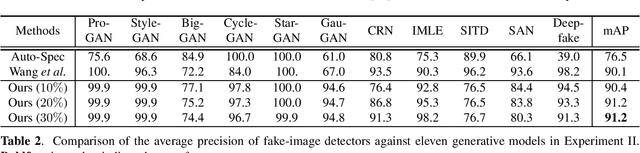
A novel method for detecting CNN-generated images, called Attentive PixelHop (or A-PixelHop), is proposed in this work. It has three advantages: 1) low computational complexity and a small model size, 2) high detection performance against a wide range of generative models, and 3) mathematical transparency. A-PixelHop is designed under the assumption that it is difficult to synthesize high-quality, high-frequency components in local regions. It contains four building modules: 1) selecting edge/texture blocks that contain significant high-frequency components, 2) applying multiple filter banks to them to obtain rich sets of spatial-spectral responses as features, 3) feeding features to multiple binary classifiers to obtain a set of soft decisions, 4) developing an effective ensemble scheme to fuse the soft decisions into the final decision. Experimental results show that A-PixelHop outperforms state-of-the-art methods in detecting CycleGAN-generated images. Furthermore, it can generalize well to unseen generative models and datasets.
Geo-DefakeHop: High-Performance Geographic Fake Image Detection
Oct 19, 2021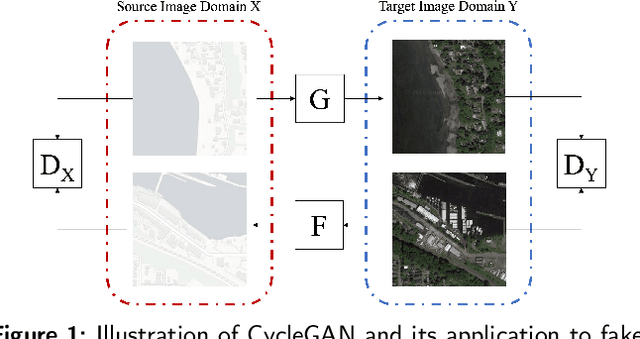
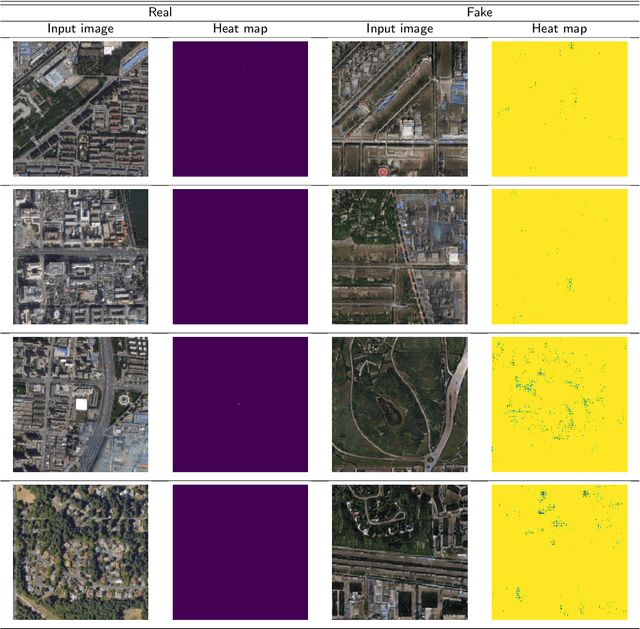
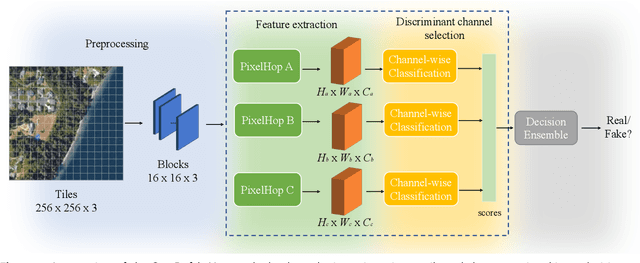

A robust fake satellite image detection method, called Geo-DefakeHop, is proposed in this work. Geo-DefakeHop is developed based on the parallel subspace learning (PSL) methodology. PSL maps the input image space into several feature subspaces using multiple filter banks. By exploring response differences of different channels between real and fake images for a filter bank, Geo-DefakeHop learns the most discriminant channels and uses their soft decision scores as features. Then, Geo-DefakeHop selects a few discriminant features from each filter bank and ensemble them to make a final binary decision. Geo-DefakeHop offers a light-weight high-performance solution to fake satellite images detection. Its model size is analyzed, which ranges from 0.8 to 62K parameters. Furthermore, it is shown by experimental results that it achieves an F1-score higher than 95\% under various common image manipulations such as resizing, compression and noise corruption.
Dynamic Texture Synthesis by Incorporating Long-range Spatial and Temporal Correlations
Apr 14, 2021

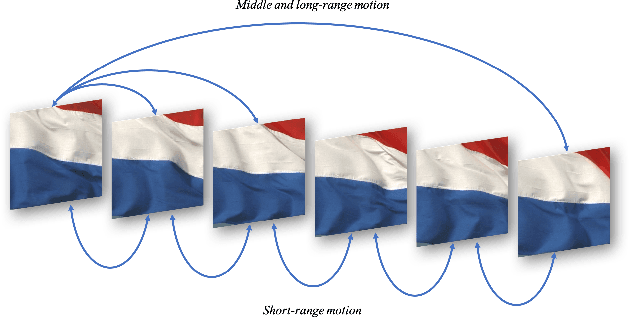

The main challenge of dynamic texture synthesis lies in how to maintain spatial and temporal consistency in synthesized videos. The major drawback of existing dynamic texture synthesis models comes from poor treatment of the long-range texture correlation and motion information. To address this problem, we incorporate a new loss term, called the Shifted Gram loss, to capture the structural and long-range correlation of the reference texture video. Furthermore, we introduce a frame sampling strategy to exploit long-period motion across multiple frames. With these two new techniques, the application scope of existing texture synthesis models can be extended. That is, they can synthesize not only homogeneous but also structured dynamic texture patterns. Thorough experimental results are provided to demonstrate that our proposed dynamic texture synthesis model offers state-of-the-art visual performance.
DefakeHop: A Light-Weight High-Performance Deepfake Detector
Mar 11, 2021

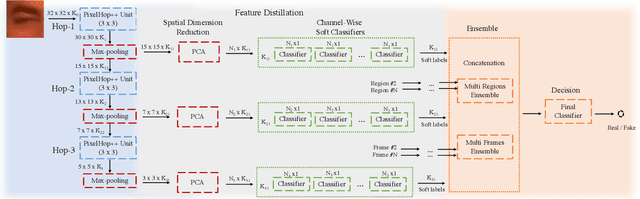
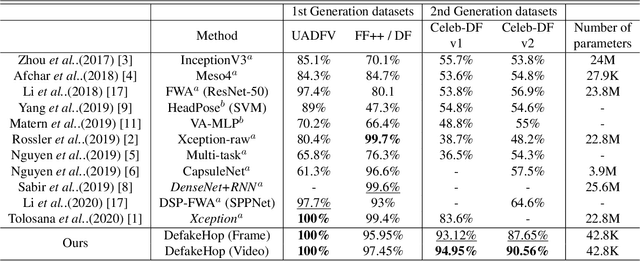
A light-weight high-performance Deepfake detection method, called DefakeHop, is proposed in this work. State-of-the-art Deepfake detection methods are built upon deep neural networks. DefakeHop extracts features automatically using the successive subspace learning (SSL) principle from various parts of face images. The features are extracted by c/w Saab transform and further processed by our feature distillation module using spatial dimension reduction and soft classification for each channel to get a more concise description of the face. Extensive experiments are conducted to demonstrate the effectiveness of the proposed DefakeHop method. With a small model size of 42,845 parameters, DefakeHop achieves state-of-the-art performance with the area under the ROC curve (AUC) of 100%, 94.95%, and 90.56% on UADFV, Celeb-DF v1 and Celeb-DF v2 datasets, respectively.