 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs in Biomedicine: A study on clinical Named Entity Recognition
Apr 10, 2024



Large Language Models (LLMs) demonstrate remarkable versatility in various NLP tasks but encounter distinct challenges in biomedicine due to medical language complexities and data scarcity. This paper investigates the application of LLMs in the medical domain by exploring strategies to enhance their performance for the Named-Entity Recognition (NER) task. Specifically, our study reveals the importance of meticulously designed prompts in biomedicine. Strategic selection of in-context examples yields a notable improvement, showcasing ~15-20\% increase in F1 score across all benchmark datasets for few-shot clinical NER. Additionally, our findings suggest that integrating external resources through prompting strategies can bridge the gap between general-purpose LLM proficiency and the specialized demands of medical NER. Leveraging a medical knowledge base, our proposed method inspired by Retrieval-Augmented Generation (RAG) can boost the F1 score of LLMs for zero-shot clinical NER. We will release the code upon publication.
MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models
Jun 02, 2023
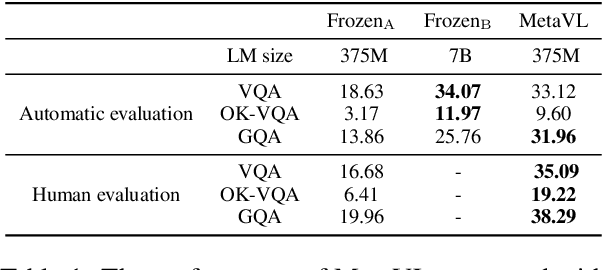

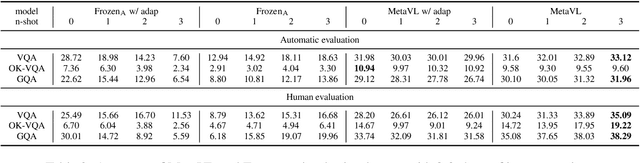
Large-scale language models have shown the ability to adapt to a new task via conditioning on a few demonstrations (i.e., in-context learning). However, in the vision-language domain, most large-scale pre-trained vision-language (VL) models do not possess the ability to conduct in-context learning. How can we enable in-context learning for VL models? In this paper, we study an interesting hypothesis: can we transfer the in-context learning ability from the language domain to VL domain? Specifically, we first meta-trains a language model to perform in-context learning on NLP tasks (as in MetaICL); then we transfer this model to perform VL tasks by attaching a visual encoder. Our experiments suggest that indeed in-context learning ability can be transferred cross modalities: our model considerably improves the in-context learning capability on VL tasks and can even compensate for the size of the model significantly. On VQA, OK-VQA, and GQA, our method could outperform the baseline model while having 20 times fewer parameters.
MAGIC: Mask-Guided Image Synthesis by Inverting a Quasi-Robust Classifier
Sep 23, 2022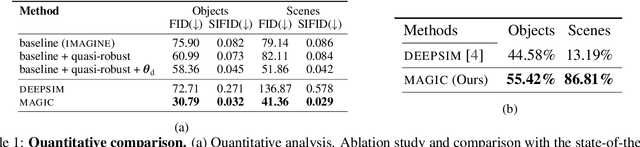
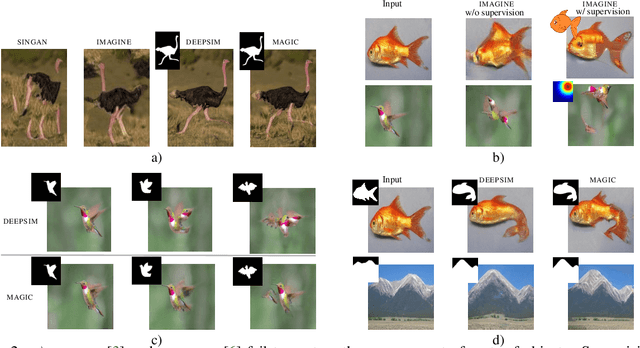
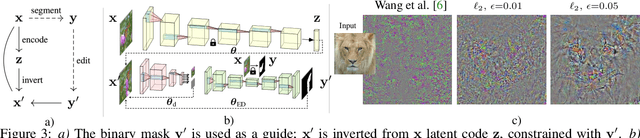

We offer a method for one-shot image synthesis that allows controlling manipulations of a single image by inverting a quasi-robust classifier equipped with strong regularizers. Our proposed method, entitled Magic, samples structured gradients from a pre-trained quasi-robust classifier to better preserve the input semantics while preserving its classification accuracy, thereby guaranteeing credibility in the synthesis. Unlike current methods that use complex primitives to supervise the process or use attention maps as a weak supervisory signal, Magic aggregates gradients over the input, driven by a guide binary mask that enforces a strong, spatial prior. Magic implements a series of manipulations with a single framework achieving shape and location control, intense non-rigid shape deformations, and copy/move operations in the presence of repeating objects and gives users firm control over the synthesis by requiring simply specifying binary guide masks. Our study and findings are supported by various qualitative comparisons with the state-of-the-art on the same images sampled from ImageNet and quantitative analysis using machine perception along with a user survey of 100+ participants that endorse our synthesis quality.
BERTHop: An Effective Vision-and-Language Model for Chest X-ray Disease Diagnosis
Aug 10, 2021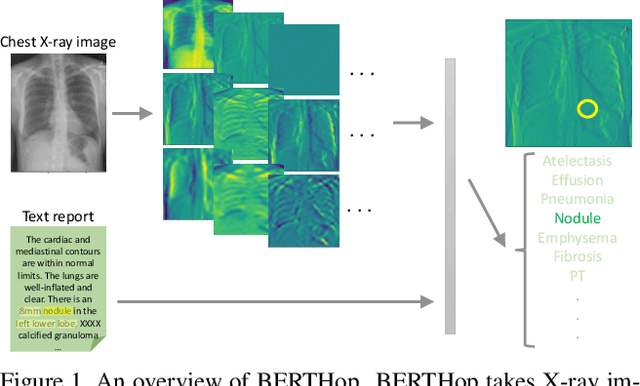
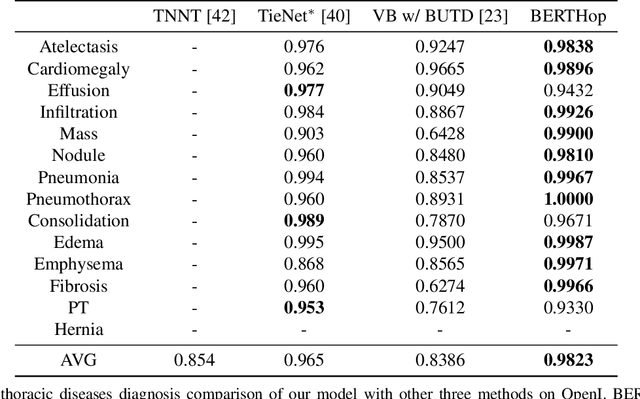
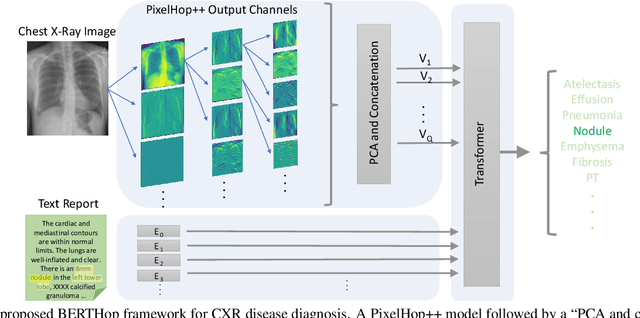
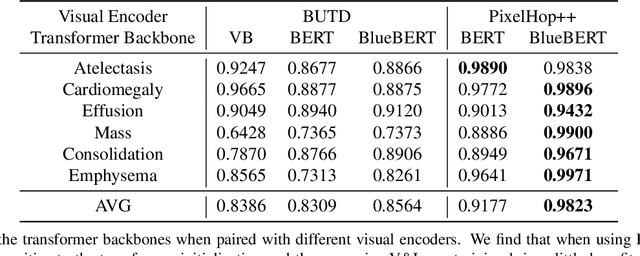
Vision-and-language(V&L) models take image and text as input and learn to capture the associations between them. Prior studies show that pre-trained V&L models can significantly improve the model performance for downstream tasks such as Visual Question Answering (VQA). However, V&L models are less effective when applied in the medical domain (e.g., on X-ray images and clinical notes) due to the domain gap. In this paper, we investigate the challenges of applying pre-trained V&L models in medical applications. In particular, we identify that the visual representation in general V&L models is not suitable for processing medical data. To overcome this limitation, we propose BERTHop, a transformer-based model based on PixelHop++ and VisualBERT, for better capturing the associations between the two modalities. Experiments on the OpenI dataset, a commonly used thoracic disease diagnosis benchmark, show that BERTHop achieves an average Area Under the Curve (AUC) of 98.12% which is 1.62% higher than state-of-the-art (SOTA) while it is trained on a 9 times smaller dataset.
DefakeHop: A Light-Weight High-Performance Deepfake Detector
Mar 11, 2021

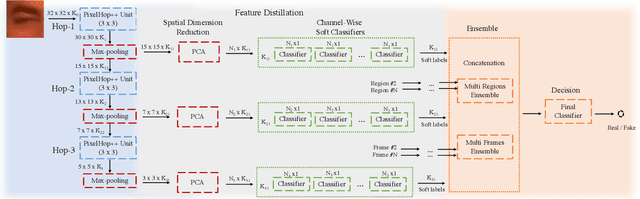
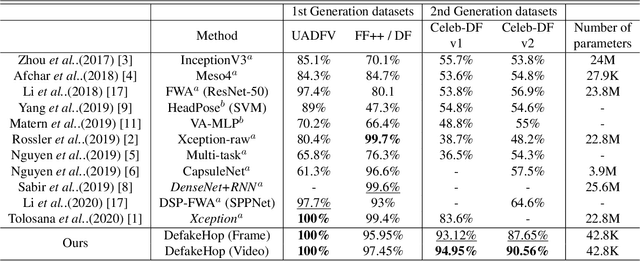
A light-weight high-performance Deepfake detection method, called DefakeHop, is proposed in this work. State-of-the-art Deepfake detection methods are built upon deep neural networks. DefakeHop extracts features automatically using the successive subspace learning (SSL) principle from various parts of face images. The features are extracted by c/w Saab transform and further processed by our feature distillation module using spatial dimension reduction and soft classification for each channel to get a more concise description of the face. Extensive experiments are conducted to demonstrate the effectiveness of the proposed DefakeHop method. With a small model size of 42,845 parameters, DefakeHop achieves state-of-the-art performance with the area under the ROC curve (AUC) of 100%, 94.95%, and 90.56% on UADFV, Celeb-DF v1 and Celeb-DF v2 datasets, respectively.
Successive Subspace Learning: An Overview
Feb 27, 2021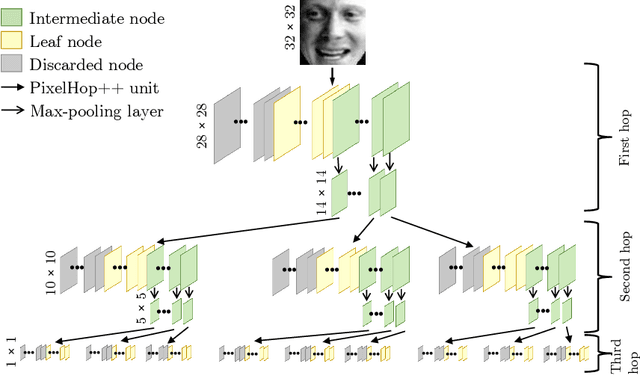
Successive Subspace Learning (SSL) offers a light-weight unsupervised feature learning method based on inherent statistical properties of data units (e.g. image pixels and points in point cloud sets). It has shown promising results, especially on small datasets. In this paper, we intuitively explain this method, provide an overview of its development, and point out some open questions and challenges for future research.
Low-Resolution Face Recognition In Resource-Constrained Environments
Nov 23, 2020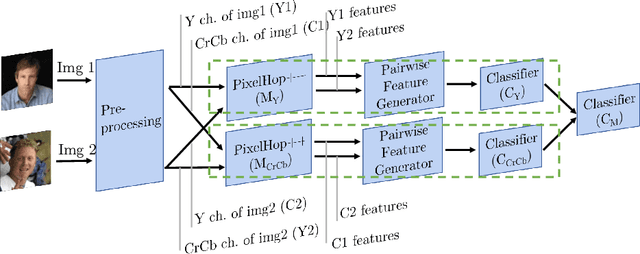


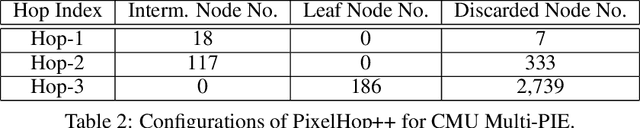
A non-parametric low-resolution face recognition model for resource-constrained environments with limited networking and computing is proposed in this work. Such environments often demand a small model capable of being effectively trained on a small number of labeled data samples, with low training complexity, and low-resolution input images. To address these challenges, we adopt an emerging explainable machine learning methodology called successive subspace learning (SSL).SSL offers an explainable non-parametric model that flexibly trades the model size for verification performance. Its training complexity is significantly lower since its model is trained in a one-pass feedforward manner without backpropagation. Furthermore, active learning can be conveniently incorporated to reduce the labeling cost. The effectiveness of the proposed model is demonstrated by experiments on the LFW and the CMU Multi-PIE datasets.
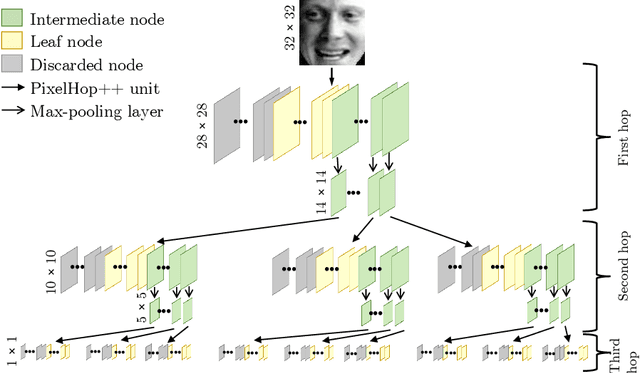
FaceHop: A Light-Weight Low-Resolution Face Gender Classification Method
Jul 21, 2020
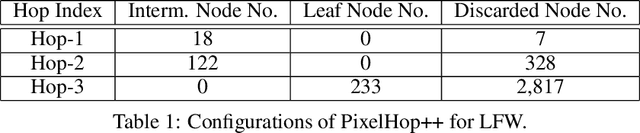
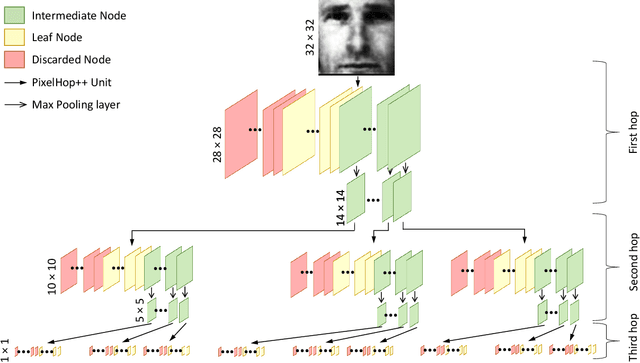
A light-weight low-resolution face gender classification method, called FaceHop, is proposed in this research. We have witnessed a rapid progress in face gender classification accuracy due to the adoption of deep learning (DL) technology. Yet, DL-based systems are not suitable for resource-constrained environments with limited networking and computing. FaceHop offers an interpretable non-parametric machine learning solution. It has desired characteristics such as a small model size, a small training data amount, low training complexity, and low resolution input images. FaceHop is developed with the successive subspace learning (SSL) principle and built upon the foundation of PixelHop++. The effectiveness of the FaceHop method is demonstrated by experiments. For gray-scale face images of resolution $32 \times 32$ in the LFW and the CMU Multi-PIE datasets, FaceHop achieves correct gender classification rates of 94.63\% and 95.12\% with model sizes of 16.9K and 17.6K parameters, respectively. It outperforms LeNet-5 in classification accuracy while LeNet-5 has a model size of 75.8K parameters.
PixelHop++: A Small Successive-Subspace-Learning-Based (SSL-based) Model for Image Classification
Feb 08, 2020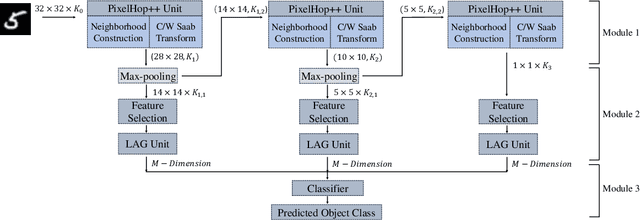
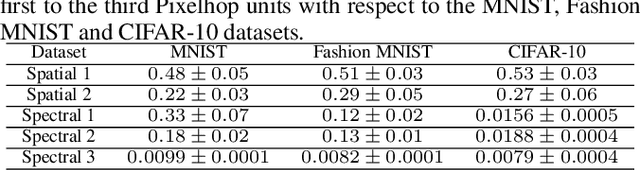
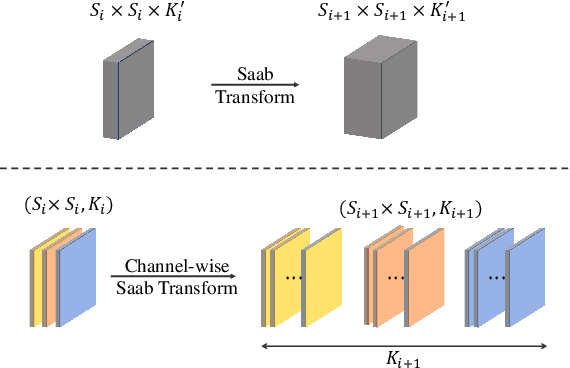
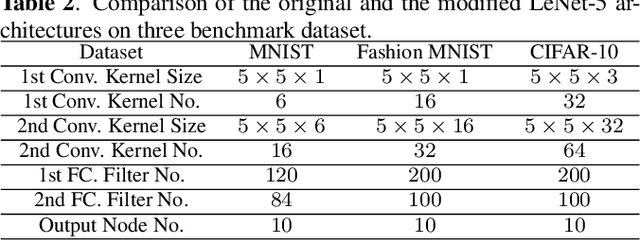
The successive subspace learning (SSL) principle was developed and used to design an interpretable learning model, known as the PixelHop method,for image classification in our prior work. Here, we propose an improved PixelHop method and call it PixelHop++. First, to make the PixelHop model size smaller, we decouple a joint spatial-spectral input tensor to multiple spatial tensors (one for each spectral component) under the spatial-spectral separability assumption and perform the Saab transform in a channel-wise manner, called the channel-wise (c/w) Saab transform.Second, by performing this operation from one hop to another successively, we construct a channel-decomposed feature tree whose leaf nodes contain features of one dimension (1D). Third, these 1D features are ranked according to their cross-entropy values, which allows us to select a subset of discriminant features for image classification. In PixelHop++, one can control the learning model size of fine-granularity,offering a flexible tradeoff between the model size and the classification performance. We demonstrate the flexibility of PixelHop++ on MNIST, Fashion MNIST, and CIFAR-10 three datasets.