Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuccessive Subspace Learning: An Overview
Paper and Code
Feb 27, 2021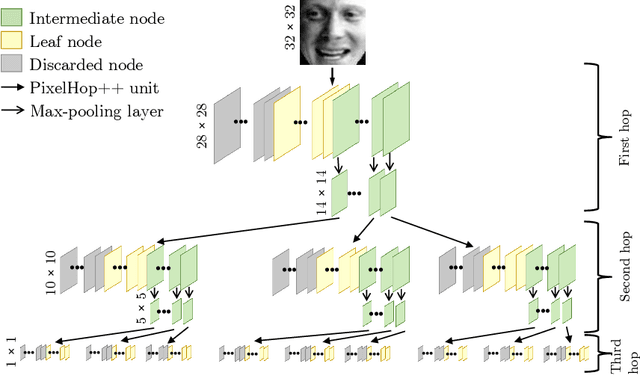
Successive Subspace Learning (SSL) offers a light-weight unsupervised feature learning method based on inherent statistical properties of data units (e.g. image pixels and points in point cloud sets). It has shown promising results, especially on small datasets. In this paper, we intuitively explain this method, provide an overview of its development, and point out some open questions and challenges for future research.
* 4 pages, 1 figure
View paper on