 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolySim: Bridging the Sim-to-Real Gap for Humanoid Control via Multi-Simulator Dynamics Randomization
Oct 02, 2025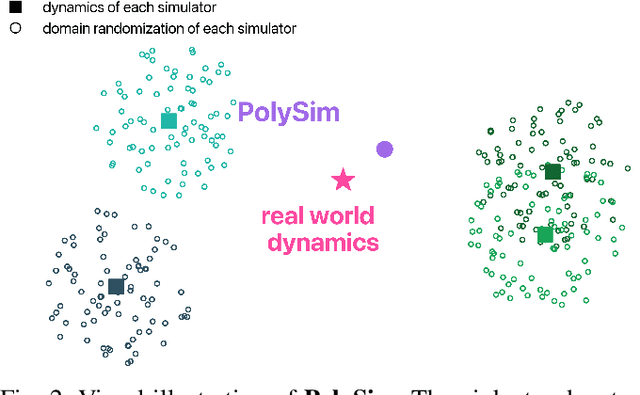
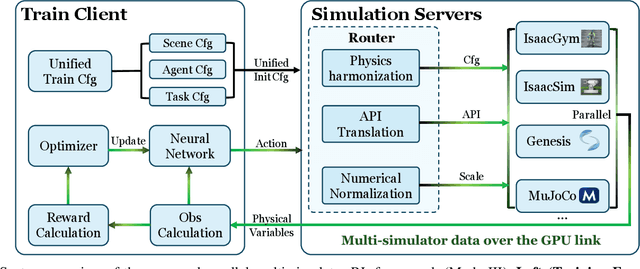
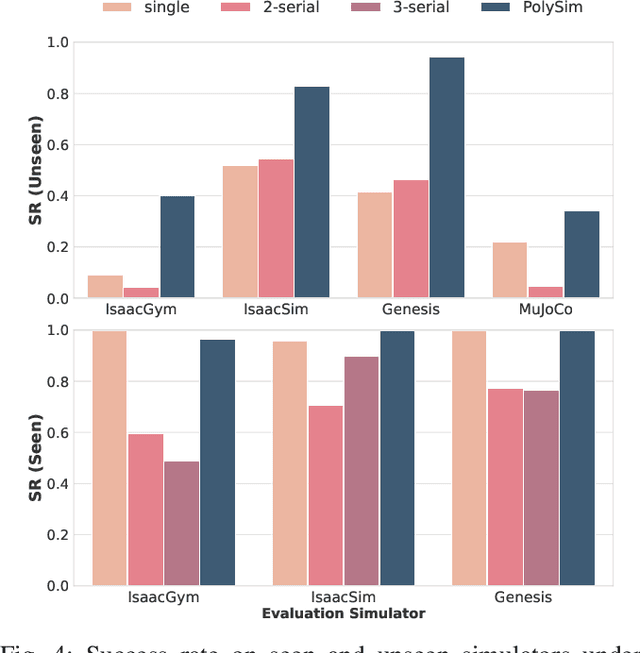

Humanoid whole-body control (WBC) policies trained in simulation often suffer from the sim-to-real gap, which fundamentally arises from simulator inductive bias, the inherent assumptions and limitations of any single simulator. These biases lead to nontrivial discrepancies both across simulators and between simulation and the real world. To mitigate the effect of simulator inductive bias, the key idea is to train policies jointly across multiple simulators, encouraging the learned controller to capture dynamics that generalize beyond any single simulator's assumptions. We thus introduce PolySim, a WBC training platform that integrates multiple heterogeneous simulators. PolySim can launch parallel environments from different engines simultaneously within a single training run, thereby realizing dynamics-level domain randomization. Theoretically, we show that PolySim yields a tighter upper bound on simulator inductive bias than single-simulator training. In experiments, PolySim substantially reduces motion-tracking error in sim-to-sim evaluations; for example, on MuJoCo, it improves execution success by 52.8 over an IsaacSim baseline. PolySim further enables zero-shot deployment on a real Unitree G1 without additional fine-tuning, showing effective transfer from simulation to the real world. We will release the PolySim code upon acceptance of this work.
Hierarchical Attention Networks for Lossless Point Cloud Attribute Compression
Apr 01, 2025In this paper, we propose a deep hierarchical attention context model for lossless attribute compression of point clouds, leveraging a multi-resolution spatial structure and residual learning. A simple and effective Level of Detail (LoD) structure is introduced to yield a coarse-to-fine representation. To enhance efficiency, points within the same refinement level are encoded in parallel, sharing a common context point group. By hierarchically aggregating information from neighboring points, our attention model learns contextual dependencies across varying scales and densities, enabling comprehensive feature extraction. We also adopt normalization for position coordinates and attributes to achieve scale-invariant compression. Additionally, we segment the point cloud into multiple slices to facilitate parallel processing, further optimizing time complexity. Experimental results demonstrate that the proposed method offers better coding performance than the latest G-PCC for color and reflectance attributes while maintaining more efficient encoding and decoding runtimes.
LSR: A Light-Weight Super-Resolution Method
Feb 27, 2023A light-weight super-resolution (LSR) method from a single image targeting mobile applications is proposed in this work. LSR predicts the residual image between the interpolated low-resolution (ILR) and high-resolution (HR) images using a self-supervised framework. To lower the computational complexity, LSR does not adopt the end-to-end optimization deep networks. It consists of three modules: 1) generation of a pool of rich and diversified representations in the neighborhood of a target pixel via unsupervised learning, 2) selecting a subset from the representation pool that is most relevant to the underlying super-resolution task automatically via supervised learning, 3) predicting the residual of the target pixel via regression. LSR has low computational complexity and reasonable model size so that it can be implemented on mobile/edge platforms conveniently. Besides, it offers better visual quality than classical exemplar-based methods in terms of PSNR/SSIM measures.
Point Cloud Attribute Compression via Successive Subspace Graph Transform
Oct 29, 2020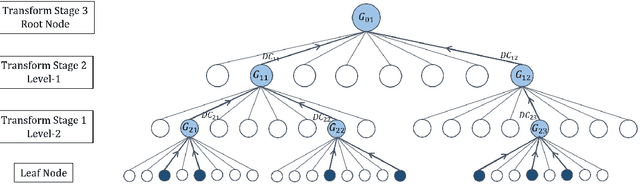
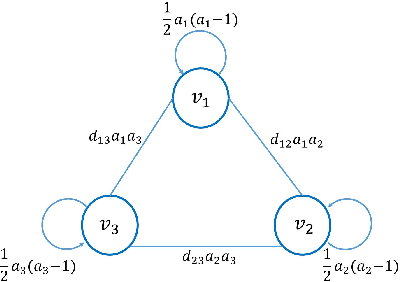
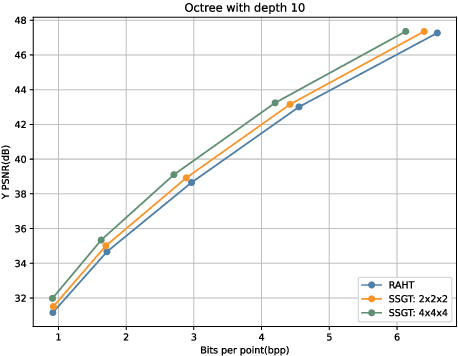

Inspired by the recently proposed successive subspace learning (SSL) principles, we develop a successive subspace graph transform (SSGT) to address point cloud attribute compression in this work. The octree geometry structure is utilized to partition the point cloud, where every node of the octree represents a point cloud subspace with a certain spatial size. We design a weighted graph with self-loop to describe the subspace and define a graph Fourier transform based on the normalized graph Laplacian. The transforms are applied to large point clouds from the leaf nodes to the root node of the octree recursively, while the represented subspace is expanded from the smallest one to the whole point cloud successively. It is shown by experimental results that the proposed SSGT method offers better R-D performances than the previous Region Adaptive Haar Transform (RAHT) method.
PixelHop++: A Small Successive-Subspace-Learning-Based (SSL-based) Model for Image Classification
Feb 08, 2020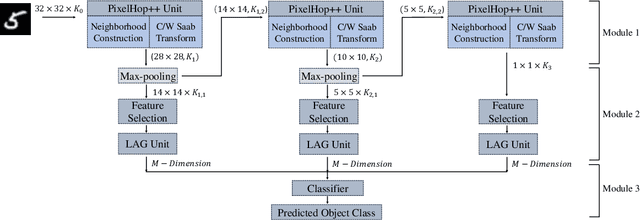
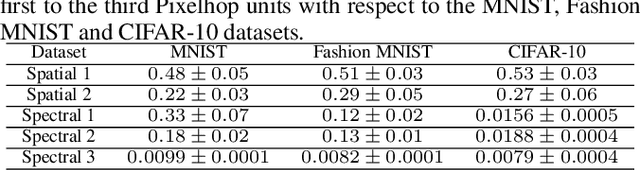
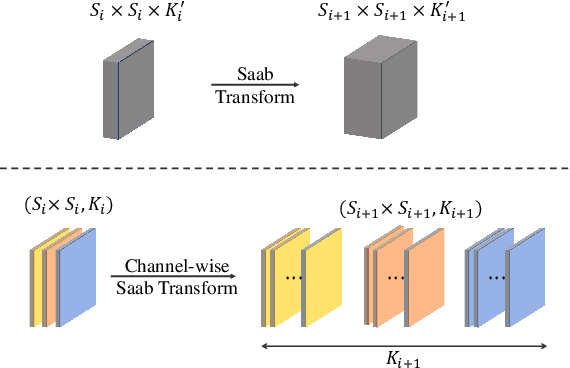
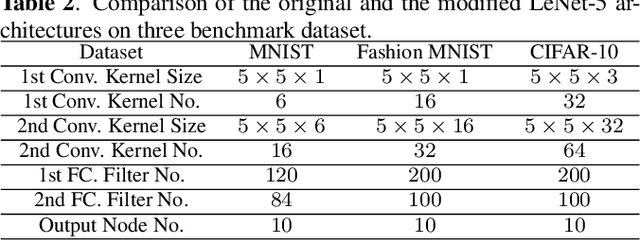
The successive subspace learning (SSL) principle was developed and used to design an interpretable learning model, known as the PixelHop method,for image classification in our prior work. Here, we propose an improved PixelHop method and call it PixelHop++. First, to make the PixelHop model size smaller, we decouple a joint spatial-spectral input tensor to multiple spatial tensors (one for each spectral component) under the spatial-spectral separability assumption and perform the Saab transform in a channel-wise manner, called the channel-wise (c/w) Saab transform.Second, by performing this operation from one hop to another successively, we construct a channel-decomposed feature tree whose leaf nodes contain features of one dimension (1D). Third, these 1D features are ranked according to their cross-entropy values, which allows us to select a subset of discriminant features for image classification. In PixelHop++, one can control the learning model size of fine-granularity,offering a flexible tradeoff between the model size and the classification performance. We demonstrate the flexibility of PixelHop++ on MNIST, Fashion MNIST, and CIFAR-10 three datasets.
PixelHop: A Successive Subspace Learning (SSL) Method for Object Classification
Sep 17, 2019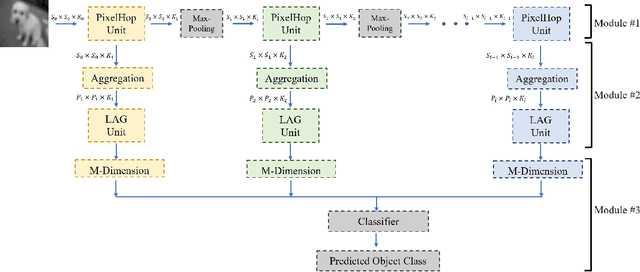
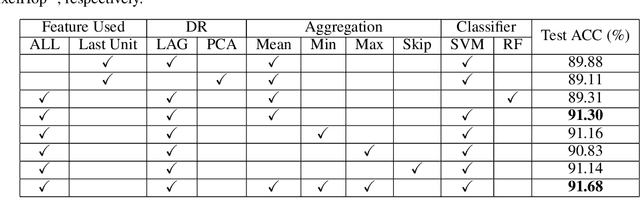
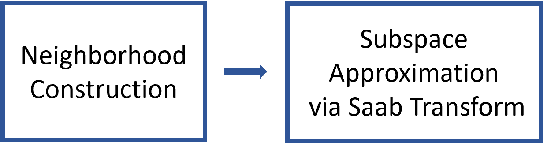

A new machine learning methodology, called successive subspace learning (SSL), is introduced in this work. SSL contains four key ingredients: 1) successive near-to-far neighborhood expansion; 2) unsupervised dimension reduction via subspace approximation; 3) supervised dimension reduction via label-assisted regression (LAG); and 4) feature concatenation and decision making. An image-based object classification method, called PixelHop, is proposed to illustrate the SSL design. It is shown by experimental results that the PixelHop method outperforms the classic CNN model of similar model complexity in three benchmarking datasets (MNIST, Fashion MNIST and CIFAR-10). Although SSL and deep learning (DL) have some high-level concept in common, they are fundamentally different in model formulation, the training process and training complexity. Extensive discussion on the comparison of SSL and DL is made to provide further insights into the potential of SSL.
Semi-supervised learning via Feedforward-Designed Convolutional Neural Networks
Feb 06, 2019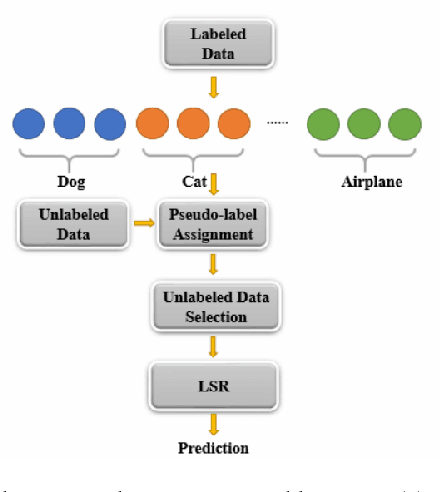
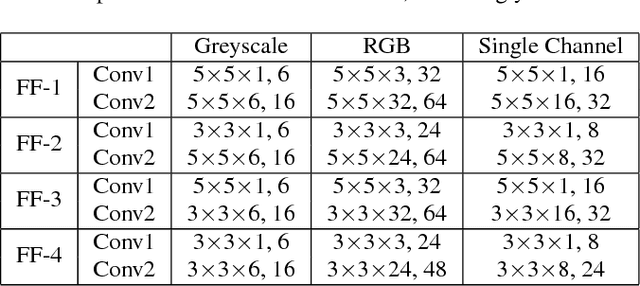

A semi-supervised learning framework using the feedforward-designed convolutional neural networks (FF-CNNs) is proposed for image classification in this work. One unique property of FF-CNNs is that no backpropagation is used in model parameters determination. Since unlabeled data may not always enhance semi-supervised learning, we define an effective quality score and use it to select a subset of unlabeled data in the training process. We conduct experiments on the MNIST, SVHN, and CIFAR-10 datasets, and show that the proposed semi-supervised FF-CNN solution outperforms the CNN trained by backpropagation (BP-CNN) when the amount of labeled data is reduced. Furthermore, we develop an ensemble system that combines the output decision vectors of different semi-supervised FF-CNNs to boost classification accuracy. The ensemble systems can achieve further performance gains on all three benchmarking datasets.
Ensembles of feedforward-designed convolutional neural networks
Jan 08, 2019
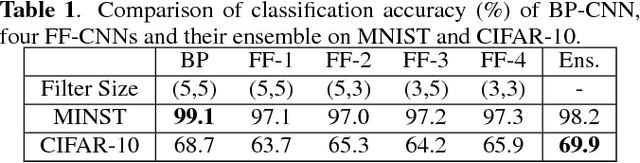
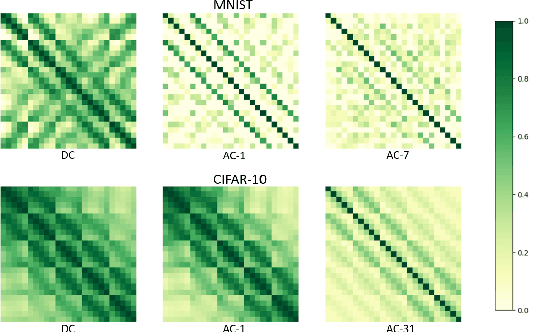

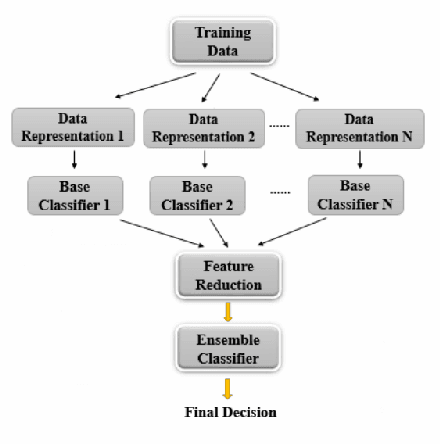
An ensemble method that fuses the output decision vectors of multiple feedforward-designed convolutional neural networks (FF-CNNs) to solve the image classification problem is proposed in this work. To enhance the performance of the ensemble system, it is critical to increasing the diversity of FF-CNN models. To achieve this objective, we introduce diversities by adopting three strategies: 1) different parameter settings in convolutional layers, 2) flexible feature subsets fed into the Fully-connected (FC) layers, and 3) multiple image embeddings of the same input source. Furthermore, we partition input samples into easy and hard ones based on their decision confidence scores. As a result, we can develop a new ensemble system tailored to hard samples to further boost classification accuracy. Experiments are conducted on the MNIST and CIFAR-10 datasets to demonstrate the effectiveness of the ensemble method.
Towards Visible and Thermal Drone Monitoring with Convolutional Neural Networks
Dec 19, 2018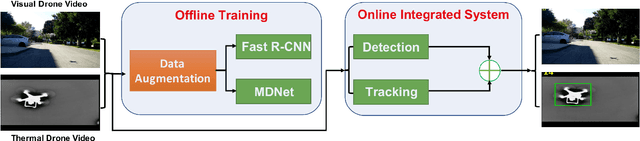



This paper reports a visible and thermal drone monitoring system that integrates deep-learning-based detection and tracking modules. The biggest challenge in adopting deep learning methods for drone detection is the paucity of training drone images especially thermal drone images. To address this issue, we develop two data augmentation techniques. One is a model-based drone augmentation technique that automatically generates visible drone images with a bounding box label on the drone's location. The other is exploiting an adversarial data augmentation methodology to create thermal drone images. To track a small flying drone, we utilize the residual information between consecutive image frames. Finally, we present an integrated detection and tracking system that outperforms the performance of each individual module containing detection or tracking only. The experiments show that even being trained on synthetic data, the proposed system performs well on real-world drone images with complex background. The USC drone detection and tracking dataset with user labeled bounding boxes is available to the public.
Unsupervised Video Object Segmentation with Distractor-Aware Online Adaptation
Dec 19, 2018

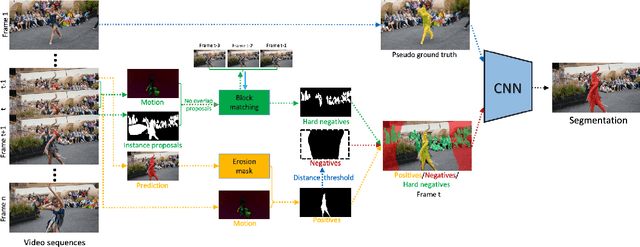

Unsupervised video object segmentation is a crucial application in video analysis without knowing any prior information about the objects. It becomes tremendously challenging when multiple objects occur and interact in a given video clip. In this paper, a novel unsupervised video object segmentation approach via distractor-aware online adaptation (DOA) is proposed. DOA models spatial-temporal consistency in video sequences by capturing background dependencies from adjacent frames. Instance proposals are generated by the instance segmentation network for each frame and then selected by motion information as hard negatives if they exist and positives. To adopt high-quality hard negatives, the block matching algorithm is then applied to preceding frames to track the associated hard negatives. General negatives are also introduced in case that there are no hard negatives in the sequence and experiments demonstrate both kinds of negatives (distractors) are complementary. Finally, we conduct DOA using the positive, negative, and hard negative masks to update the foreground/background segmentation. The proposed approach achieves state-of-the-art results on two benchmark datasets, DAVIS 2016 and FBMS-59 datasets.