 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Hierarchical Attention Networks for Lossless Point Cloud Attribute Compression
Apr 01, 2025In this paper, we propose a deep hierarchical attention context model for lossless attribute compression of point clouds, leveraging a multi-resolution spatial structure and residual learning. A simple and effective Level of Detail (LoD) structure is introduced to yield a coarse-to-fine representation. To enhance efficiency, points within the same refinement level are encoded in parallel, sharing a common context point group. By hierarchically aggregating information from neighboring points, our attention model learns contextual dependencies across varying scales and densities, enabling comprehensive feature extraction. We also adopt normalization for position coordinates and attributes to achieve scale-invariant compression. Additionally, we segment the point cloud into multiple slices to facilitate parallel processing, further optimizing time complexity. Experimental results demonstrate that the proposed method offers better coding performance than the latest G-PCC for color and reflectance attributes while maintaining more efficient encoding and decoding runtimes.
Beyond Score Changes: Adversarial Attack on No-Reference Image Quality Assessment from Two Perspectives
Apr 24, 2024



Deep neural networks have demonstrated impressive success in No-Reference Image Quality Assessment (NR-IQA). However, recent researches highlight the vulnerability of NR-IQA models to subtle adversarial perturbations, leading to inconsistencies between model predictions and subjective ratings. Current adversarial attacks, however, focus on perturbing predicted scores of individual images, neglecting the crucial aspect of inter-score correlation relationships within an entire image set. Meanwhile, it is important to note that the correlation, like ranking correlation, plays a significant role in NR-IQA tasks. To comprehensively explore the robustness of NR-IQA models, we introduce a new framework of correlation-error-based attacks that perturb both the correlation within an image set and score changes on individual images. Our research primarily focuses on ranking-related correlation metrics like Spearman's Rank-Order Correlation Coefficient (SROCC) and prediction error-related metrics like Mean Squared Error (MSE). As an instantiation, we propose a practical two-stage SROCC-MSE-Attack (SMA) that initially optimizes target attack scores for the entire image set and then generates adversarial examples guided by these scores. Experimental results demonstrate that our SMA method not only significantly disrupts the SROCC to negative values but also maintains a considerable change in the scores of individual images. Meanwhile, it exhibits state-of-the-art performance across metrics with different categories. Our method provides a new perspective on the robustness of NR-IQA models.
Defense Against Adversarial Attacks on No-Reference Image Quality Models with Gradient Norm Regularization
Mar 18, 2024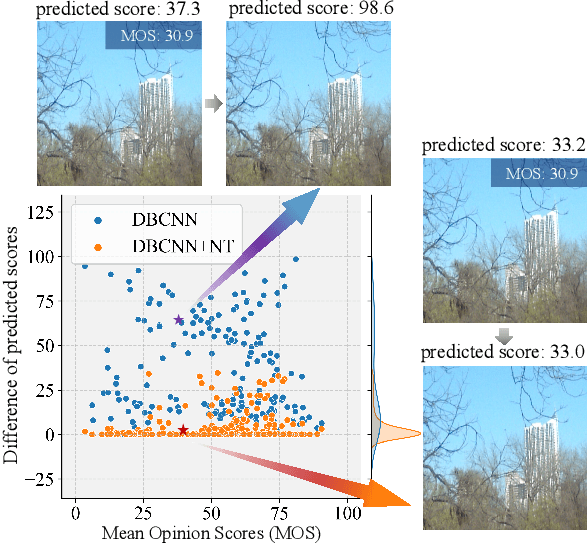
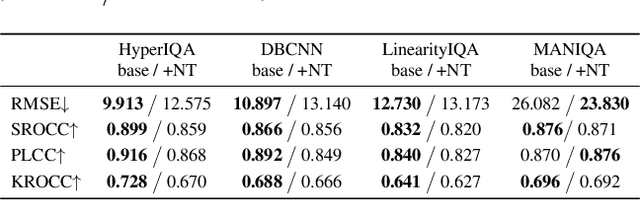


The task of No-Reference Image Quality Assessment (NR-IQA) is to estimate the quality score of an input image without additional information. NR-IQA models play a crucial role in the media industry, aiding in performance evaluation and optimization guidance. However, these models are found to be vulnerable to adversarial attacks, which introduce imperceptible perturbations to input images, resulting in significant changes in predicted scores. In this paper, we propose a defense method to improve the stability in predicted scores when attacked by small perturbations, thus enhancing the adversarial robustness of NR-IQA models. To be specific, we present theoretical evidence showing that the magnitude of score changes is related to the $\ell_1$ norm of the model's gradient with respect to the input image. Building upon this theoretical foundation, we propose a norm regularization training strategy aimed at reducing the $\ell_1$ norm of the gradient, thereby boosting the robustness of NR-IQA models. Experiments conducted on four NR-IQA baseline models demonstrate the effectiveness of our strategy in reducing score changes in the presence of adversarial attacks. To the best of our knowledge, this work marks the first attempt to defend against adversarial attacks on NR-IQA models. Our study offers valuable insights into the adversarial robustness of NR-IQA models and provides a foundation for future research in this area.
Comparison of No-Reference Image Quality Models via MAP Estimation in Diffusion Latents
Mar 11, 2024



Contemporary no-reference image quality assessment (NR-IQA) models can effectively quantify the perceived image quality, with high correlations between model predictions and human perceptual scores on fixed test sets. However, little progress has been made in comparing NR-IQA models from a perceptual optimization perspective. Here, for the first time, we demonstrate that NR-IQA models can be plugged into the maximum a posteriori (MAP) estimation framework for image enhancement. This is achieved by taking the gradients in differentiable and bijective diffusion latents rather than in the raw pixel domain. Different NR-IQA models are likely to induce different enhanced images, which are ultimately subject to psychophysical testing. This leads to a new computational method for comparing NR-IQA models within the analysis-by-synthesis framework. Compared to conventional correlation-based metrics, our method provides complementary insights into the relative strengths and weaknesses of the competing NR-IQA models in the context of perceptual optimization.
Hierarchical Prior-based Super Resolution for Point Cloud Geometry Compression
Feb 17, 2024



The Geometry-based Point Cloud Compression (G-PCC) has been developed by the Moving Picture Experts Group to compress point clouds. In its lossy mode, the reconstructed point cloud by G-PCC often suffers from noticeable distortions due to the na\"{i}ve geometry quantization (i.e., grid downsampling). This paper proposes a hierarchical prior-based super resolution method for point cloud geometry compression. The content-dependent hierarchical prior is constructed at the encoder side, which enables coarse-to-fine super resolution of the point cloud geometry at the decoder side. A more accurate prior generally yields improved reconstruction performance, at the cost of increased bits required to encode this side information. With a proper balance between prior accuracy and bit consumption, the proposed method demonstrates substantial Bjontegaard-delta bitrate savings on the MPEG Cat1A dataset, surpassing the octree-based and trisoup-based G-PCC v14. We provide our implementations for reproducible research at https://github.com/lidq92/mpeg-pcc-tmc13.
Exploring Vulnerabilities of No-Reference Image Quality Assessment Models: A Query-Based Black-Box Method
Jan 17, 2024



No-Reference Image Quality Assessment (NR-IQA) aims to predict image quality scores consistent with human perception without relying on pristine reference images, serving as a crucial component in various visual tasks. Ensuring the robustness of NR-IQA methods is vital for reliable comparisons of different image processing techniques and consistent user experiences in recommendations. The attack methods for NR-IQA provide a powerful instrument to test the robustness of NR-IQA. However, current attack methods of NR-IQA heavily rely on the gradient of the NR-IQA model, leading to limitations when the gradient information is unavailable. In this paper, we present a pioneering query-based black box attack against NR-IQA methods. We propose the concept of score boundary and leverage an adaptive iterative approach with multiple score boundaries. Meanwhile, the initial attack directions are also designed to leverage the characteristics of the Human Visual System (HVS). Experiments show our method outperforms all compared state-of-the-art attack methods and is far ahead of previous black-box methods. The effective NR-IQA model DBCNN suffers a Spearman's rank-order correlation coefficient (SROCC) decline of 0.6381 attacked by our method, revealing the vulnerability of NR-IQA models to black-box attacks. The proposed attack method also provides a potent tool for further exploration into NR-IQA robustness.
Lightweight super resolution network for point cloud geometry compression
Nov 02, 2023This paper presents an approach for compressing point cloud geometry by leveraging a lightweight super-resolution network. The proposed method involves decomposing a point cloud into a base point cloud and the interpolation patterns for reconstructing the original point cloud. While the base point cloud can be efficiently compressed using any lossless codec, such as Geometry-based Point Cloud Compression, a distinct strategy is employed for handling the interpolation patterns. Rather than directly compressing the interpolation patterns, a lightweight super-resolution network is utilized to learn this information through overfitting. Subsequently, the network parameter is transmitted to assist in point cloud reconstruction at the decoder side. Notably, our approach differentiates itself from lookup table-based methods, allowing us to obtain more accurate interpolation patterns by accessing a broader range of neighboring voxels at an acceptable computational cost. Experiments on MPEG Cat1 (Solid) and Cat2 datasets demonstrate the remarkable compression performance achieved by our method.
Perceptual Attacks of No-Reference Image Quality Models with Human-in-the-Loop
Oct 03, 2022


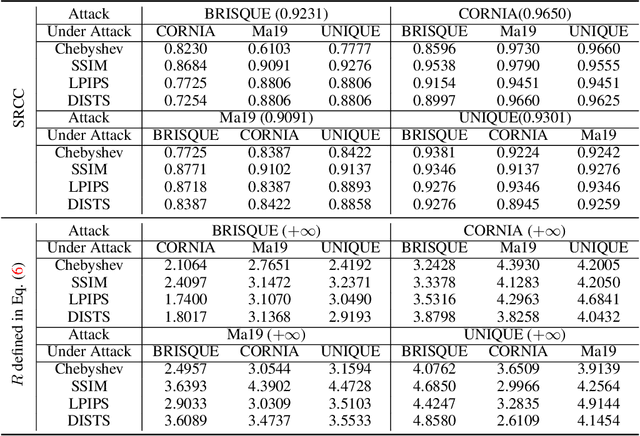
No-reference image quality assessment (NR-IQA) aims to quantify how humans perceive visual distortions of digital images without access to their undistorted references. NR-IQA models are extensively studied in computational vision, and are widely used for performance evaluation and perceptual optimization of man-made vision systems. Here we make one of the first attempts to examine the perceptual robustness of NR-IQA models. Under a Lagrangian formulation, we identify insightful connections of the proposed perceptual attack to previous beautiful ideas in computer vision and machine learning. We test one knowledge-driven and three data-driven NR-IQA methods under four full-reference IQA models (as approximations to human perception of just-noticeable differences). Through carefully designed psychophysical experiments, we find that all four NR-IQA models are vulnerable to the proposed perceptual attack. More interestingly, we observe that the generated counterexamples are not transferable, manifesting themselves as distinct design flows of respective NR-IQA methods.
Image Quality Assessment: Integrating Model-Centric and Data-Centric Approaches
Jul 29, 2022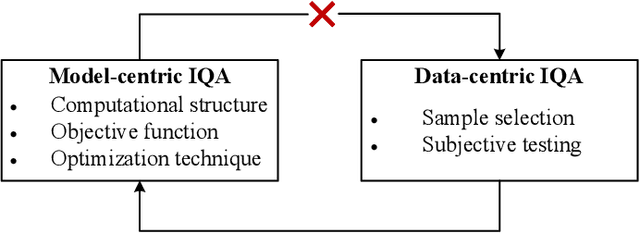
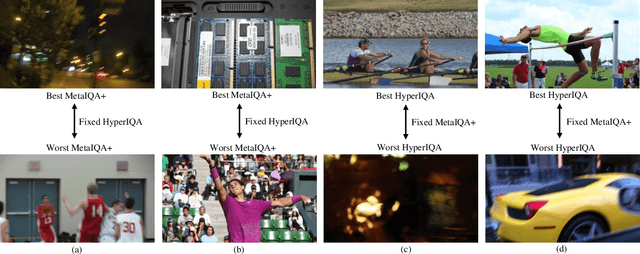
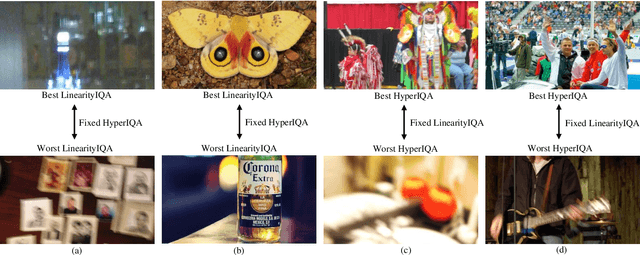

Learning-based image quality assessment (IQA) has made remarkable progress in the past decade, but nearly all consider the two key components - model and data - in relative isolation. Specifically, model-centric IQA focuses on developing "better" objective quality methods on fixed and extensively reused datasets, with a great danger of overfitting. Data-centric IQA involves conducting psychophysical experiments to construct "better" human-annotated datasets, which unfortunately ignores current IQA models during dataset creation. In this paper, we first design a series of experiments to probe computationally that such isolation of model and data impedes further progress of IQA. We then describe a computational framework that integrates model-centric and data-centric IQA. As a specific example, we design computational modules to quantify the sampling-worthiness of candidate images based on blind IQA (BIQA) model predictions and deep content-aware features. Experimental results show that the proposed sampling-worthiness module successfully spots diverse failures of the examined BIQA models, which are indeed worthy samples to be included in next-generation datasets.