 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Quality Assessment: Integrating Model-Centric and Data-Centric Approaches
Paper and Code
Jul 29, 2022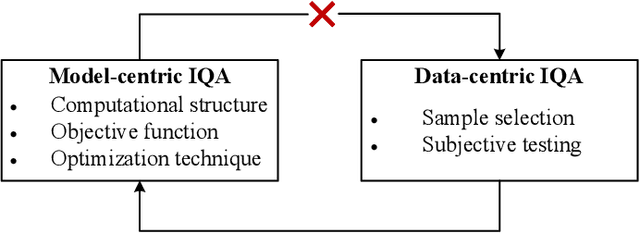
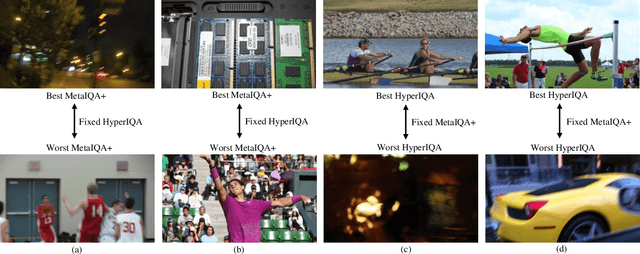
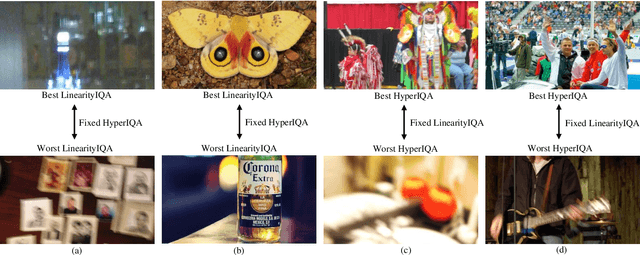

Learning-based image quality assessment (IQA) has made remarkable progress in the past decade, but nearly all consider the two key components - model and data - in relative isolation. Specifically, model-centric IQA focuses on developing "better" objective quality methods on fixed and extensively reused datasets, with a great danger of overfitting. Data-centric IQA involves conducting psychophysical experiments to construct "better" human-annotated datasets, which unfortunately ignores current IQA models during dataset creation. In this paper, we first design a series of experiments to probe computationally that such isolation of model and data impedes further progress of IQA. We then describe a computational framework that integrates model-centric and data-centric IQA. As a specific example, we design computational modules to quantify the sampling-worthiness of candidate images based on blind IQA (BIQA) model predictions and deep content-aware features. Experimental results show that the proposed sampling-worthiness module successfully spots diverse failures of the examined BIQA models, which are indeed worthy samples to be included in next-generation datasets.