 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Diffusion-Based Quantitatively Controllable Image Generation via Matrix-Form EDM and Adaptive Vicinal Training
Feb 02, 2026Continuous Conditional Diffusion Model (CCDM) is a diffusion-based framework designed to generate high-quality images conditioned on continuous regression labels. Although CCDM has demonstrated clear advantages over prior approaches across a range of datasets, it still exhibits notable limitations and has recently been surpassed by a GAN-based method, namely CcGAN-AVAR. These limitations mainly arise from its reliance on an outdated diffusion framework and its low sampling efficiency due to long sampling trajectories. To address these issues, we propose an improved CCDM framework, termed iCCDM, which incorporates the more advanced \textit{Elucidated Diffusion Model} (EDM) framework with substantial modifications to improve both generation quality and sampling efficiency. Specifically, iCCDM introduces a novel matrix-form EDM formulation together with an adaptive vicinal training strategy. Extensive experiments on four benchmark datasets, spanning image resolutions from $64\times64$ to $256\times256$, demonstrate that iCCDM consistently outperforms existing methods, including state-of-the-art large-scale text-to-image diffusion models (e.g., Stable Diffusion 3, FLUX.1, and Qwen-Image), achieving higher generation quality while significantly reducing sampling cost.
HiLLIE: Human-in-the-Loop Training for Low-Light Image Enhancement
May 04, 2025Developing effective approaches to generate enhanced results that align well with human visual preferences for high-quality well-lit images remains a challenge in low-light image enhancement (LLIE). In this paper, we propose a human-in-the-loop LLIE training framework that improves the visual quality of unsupervised LLIE model outputs through iterative training stages, named HiLLIE. At each stage, we introduce human guidance into the training process through efficient visual quality annotations of enhanced outputs. Subsequently, we employ a tailored image quality assessment (IQA) model to learn human visual preferences encoded in the acquired labels, which is then utilized to guide the training process of an enhancement model. With only a small amount of pairwise ranking annotations required at each stage, our approach continually improves the IQA model's capability to simulate human visual assessment of enhanced outputs, thus leading to visually appealing LLIE results. Extensive experiments demonstrate that our approach significantly improves unsupervised LLIE model performance in terms of both quantitative and qualitative performance. The code and collected ranking dataset will be available at https://github.com/LabShuHangGU/HiLLIE.
Learned HDR Image Compression for Perceptually Optimal Storage and Display
Jul 18, 2024



High dynamic range (HDR) capture and display have seen significant growth in popularity driven by the advancements in technology and increasing consumer demand for superior image quality. As a result, HDR image compression is crucial to fully realize the benefits of HDR imaging without suffering from large file sizes and inefficient data handling. Conventionally, this is achieved by introducing a residual/gain map as additional metadata to bridge the gap between HDR and low dynamic range (LDR) images, making the former compatible with LDR image codecs but offering suboptimal rate-distortion performance. In this work, we initiate efforts towards end-to-end optimized HDR image compression for perceptually optimal storage and display. Specifically, we learn to compress an HDR image into two bitstreams: one for generating an LDR image to ensure compatibility with legacy LDR displays, and another as side information to aid HDR image reconstruction from the output LDR image. To measure the perceptual quality of output HDR and LDR images, we use two recently proposed image distortion metrics, both validated against human perceptual data of image quality and with reference to the uncompressed HDR image. Through end-to-end optimization for rate-distortion performance, our method dramatically improves HDR and LDR image quality at all bit rates.
Perceptual Assessment and Optimization of High Dynamic Range Image Rendering
Oct 23, 2023



High dynamic range (HDR) imaging has gained increasing popularity for its ability to faithfully reproduce the luminance levels in natural scenes. Accordingly, HDR image quality assessment (IQA) is crucial but has been superficially treated. The majority of existing IQA models are developed for and calibrated against low dynamic range (LDR) images, which have been shown to be poorly correlated with human perception of HDR image quality. In this work, we propose a family of HDR IQA models by transferring the recent advances in LDR IQA. The key step in our approach is to specify a simple inverse display model that decomposes an HDR image to a set of LDR images with different exposures, which will be assessed by existing LDR quality models. The local quality scores of each exposure are then aggregated with the help of a simple well-exposedness measure into a global quality score for each exposure, which will be further weighted across exposures to obtain the overall quality score. When assessing LDR images, the proposed HDR quality models reduce gracefully to the original LDR ones with the same performance. Experiments on four human-rated HDR image datasets demonstrate that our HDR quality models are consistently better than existing IQA methods, including the HDR-VDP family. Moreover, we demonstrate their strengths in perceptual optimization of HDR novel view synthesis.
Image Quality Assessment: Integrating Model-Centric and Data-Centric Approaches
Jul 29, 2022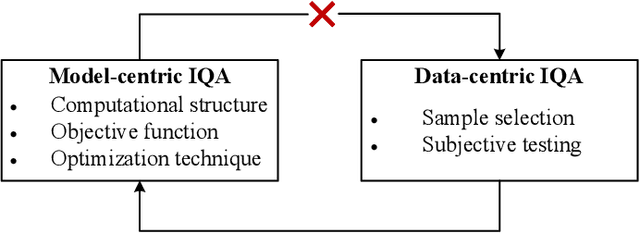
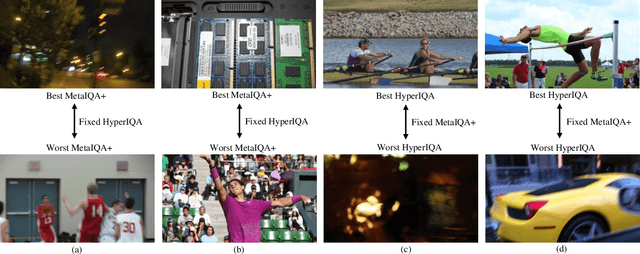
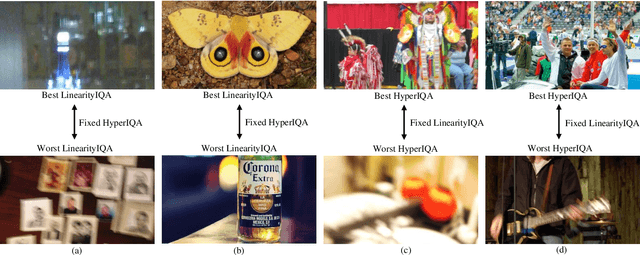

Learning-based image quality assessment (IQA) has made remarkable progress in the past decade, but nearly all consider the two key components - model and data - in relative isolation. Specifically, model-centric IQA focuses on developing "better" objective quality methods on fixed and extensively reused datasets, with a great danger of overfitting. Data-centric IQA involves conducting psychophysical experiments to construct "better" human-annotated datasets, which unfortunately ignores current IQA models during dataset creation. In this paper, we first design a series of experiments to probe computationally that such isolation of model and data impedes further progress of IQA. We then describe a computational framework that integrates model-centric and data-centric IQA. As a specific example, we design computational modules to quantify the sampling-worthiness of candidate images based on blind IQA (BIQA) model predictions and deep content-aware features. Experimental results show that the proposed sampling-worthiness module successfully spots diverse failures of the examined BIQA models, which are indeed worthy samples to be included in next-generation datasets.
Perceptual Optimization of a Biologically-Inspired Tone Mapping Operator
Jun 18, 2022

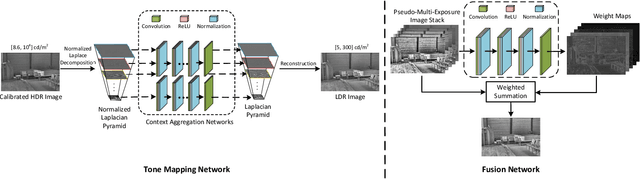
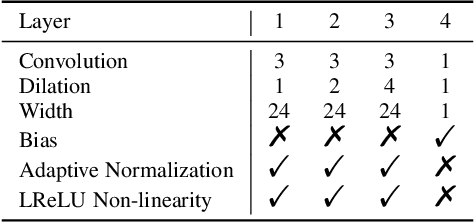
With the increasing popularity and accessibility of high dynamic range (HDR) photography, tone mapping operators (TMOs) for dynamic range compression and medium presentation are practically demanding. In this paper, we develop a two-stage neural network-based HDR image TMO that is biologically-inspired, computationally efficient, and perceptually optimized. In Stage one, motivated by the physiology of the early stages of the human visual system (HVS), we first decompose an HDR image into a normalized Laplacian pyramid. We then use two lightweight deep neural networks (DNNs) that take this normalized representation as input and estimate the Laplacian pyramid of the corresponding LDR image. We optimize the tone mapping network by minimizing the normalized Laplacian pyramid distance (NLPD), a perceptual metric calibrated against human judgments of tone-mapped image quality. In Stage two, we generate a pseudo-multi-exposure image stack with different color saturation and detail visibility by inputting an HDR image ``calibrated'' with different maximum luminances to the learned tone mapping network. We then train another lightweight DNN to fuse the LDR image stack into a desired LDR image by maximizing a variant of MEF-SSIM, another perceptually calibrated metric for image fusion. By doing so, the proposed TMO is fully automatic to tone map uncalibrated HDR images. Across an independent set of HDR images, we find that our method produces images with consistently better visual quality, and is among the fastest local TMOs.