 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation
May 28, 2024There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker's voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
ComSL: A Composite Speech-Language Model for End-to-End Speech-to-Text Translation
May 24, 2023



Joint speech-language training is challenging due to the large demand for training data and GPU consumption, as well as the modality gap between speech and language. We present ComSL, a speech-language model built atop a composite architecture of public pretrained speech-only and language-only models and optimized data-efficiently for spoken language tasks. Particularly, we propose to incorporate cross-modality learning into transfer learning and conduct them simultaneously for downstream tasks in a multi-task learning manner. Our approach has demonstrated effectiveness in end-to-end speech-to-text translation tasks, achieving a new state-of-the-art average BLEU score of 31.5 on the multilingual speech to English text translation task for 21 languages, as measured on the public CoVoST2 evaluation set.
On Realization of Intelligent Decision-Making in the Real World: A Foundation Decision Model Perspective
Dec 24, 2022Our situated environment is full of uncertainty and highly dynamic, thus hindering the widespread adoption of machine-led Intelligent Decision-Making (IDM) in real world scenarios. This means IDM should have the capability of continuously learning new skills and efficiently generalizing across wider applications. IDM benefits from any new approaches and theoretical breakthroughs that exhibit Artificial General Intelligence (AGI) breaking the barriers between tasks and applications. Recent research has well-examined neural architecture, Transformer, as a backbone foundation model and its generalization to various tasks, including computer vision, natural language processing, and reinforcement learning. We therefore argue that a foundation decision model (FDM) can be established by formulating various decision-making tasks as a sequence decoding task using the Transformer architecture; this would be a promising solution to advance the applications of IDM in more complex real world tasks. In this paper, we elaborate on how a foundation decision model improves the efficiency and generalization of IDM. We also discuss potential applications of a FDM in multi-agent game AI, production scheduling, and robotics tasks. Finally, through a case study, we demonstrate our realization of the FDM, DigitalBrain (DB1) with 1.2 billion parameters, which achieves human-level performance over 453 tasks, including text generation, images caption, video games playing, robotic control, and traveling salesman problems. As a foundation decision model, DB1 would be a baby step towards more autonomous and efficient real world IDM applications.
Perceptual Optimization of a Biologically-Inspired Tone Mapping Operator
Jun 18, 2022

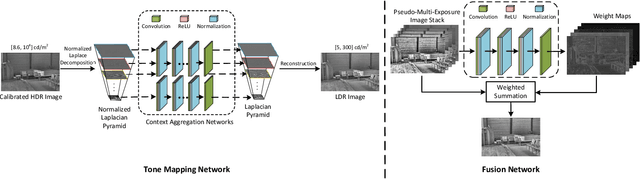
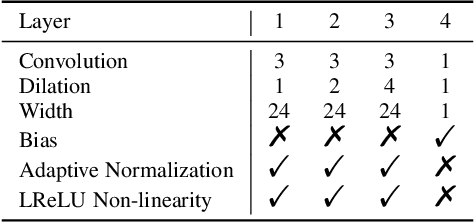
With the increasing popularity and accessibility of high dynamic range (HDR) photography, tone mapping operators (TMOs) for dynamic range compression and medium presentation are practically demanding. In this paper, we develop a two-stage neural network-based HDR image TMO that is biologically-inspired, computationally efficient, and perceptually optimized. In Stage one, motivated by the physiology of the early stages of the human visual system (HVS), we first decompose an HDR image into a normalized Laplacian pyramid. We then use two lightweight deep neural networks (DNNs) that take this normalized representation as input and estimate the Laplacian pyramid of the corresponding LDR image. We optimize the tone mapping network by minimizing the normalized Laplacian pyramid distance (NLPD), a perceptual metric calibrated against human judgments of tone-mapped image quality. In Stage two, we generate a pseudo-multi-exposure image stack with different color saturation and detail visibility by inputting an HDR image ``calibrated'' with different maximum luminances to the learned tone mapping network. We then train another lightweight DNN to fuse the LDR image stack into a desired LDR image by maximizing a variant of MEF-SSIM, another perceptually calibrated metric for image fusion. By doing so, the proposed TMO is fully automatic to tone map uncalibrated HDR images. Across an independent set of HDR images, we find that our method produces images with consistently better visual quality, and is among the fastest local TMOs.
Offline Pre-trained Multi-Agent Decision Transformer: One Big Sequence Model Tackles All SMAC Tasks
Dec 20, 2021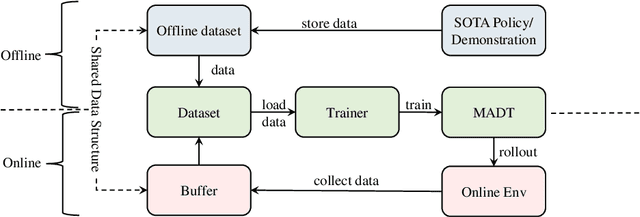
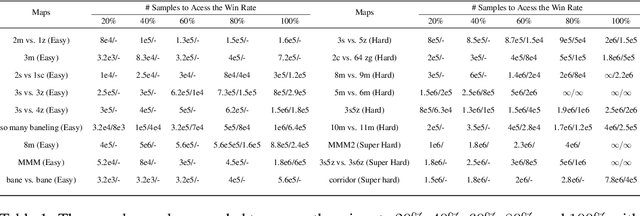
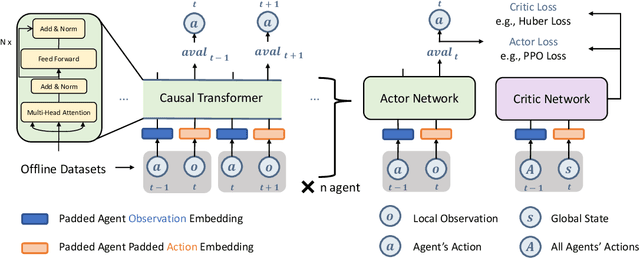
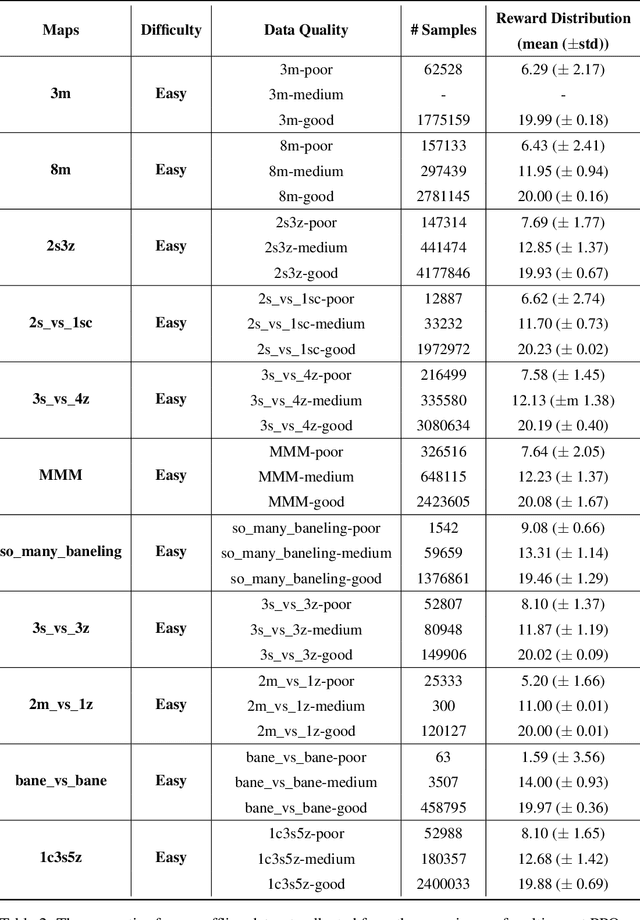
Offline reinforcement learning leverages previously-collected offline datasets to learn optimal policies with no necessity to access the real environment. Such a paradigm is also desirable for multi-agent reinforcement learning (MARL) tasks, given the increased interactions among agents and with the enviroment. Yet, in MARL, the paradigm of offline pre-training with online fine-tuning has not been studied, nor datasets or benchmarks for offline MARL research are available. In this paper, we facilitate the research by providing large-scale datasets, and use them to examine the usage of the Decision Transformer in the context of MARL. We investigate the generalisation of MARL offline pre-training in the following three aspects: 1) between single agents and multiple agents, 2) from offline pretraining to the online fine-tuning, and 3) to that of multiple downstream tasks with few-shot and zero-shot capabilities. We start by introducing the first offline MARL dataset with diverse quality levels based on the StarCraftII environment, and then propose the novel architecture of multi-agent decision transformer (MADT) for effective offline learning. MADT leverages transformer's modelling ability of sequence modelling and integrates it seamlessly with both offline and online MARL tasks. A crucial benefit of MADT is that it learns generalizable policies that can transfer between different types of agents under different task scenarios. On StarCraft II offline dataset, MADT outperforms the state-of-the-art offline RL baselines. When applied to online tasks, the pre-trained MADT significantly improves sample efficiency, and enjoys strong performance both few-short and zero-shot cases. To our best knowledge, this is the first work that studies and demonstrates the effectiveness of offline pre-trained models in terms of sample efficiency and generalisability enhancements in MARL.
Perceptually Optimized Deep High-Dynamic-Range Image Tone Mapping
Sep 02, 2021
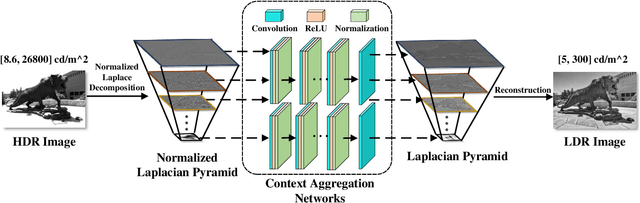


We describe a deep high-dynamic-range (HDR) image tone mapping operator that is computationally efficient and perceptually optimized. We first decompose an HDR image into a normalized Laplacian pyramid, and use two deep neural networks (DNNs) to estimate the Laplacian pyramid of the desired tone-mapped image from the normalized representation. We then end-to-end optimize the entire method over a database of HDR images by minimizing the normalized Laplacian pyramid distance (NLPD), a recently proposed perceptual metric. Qualitative and quantitative experiments demonstrate that our method produces images with better visual quality, and runs the fastest among existing local tone mapping algorithms.