 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreativeGame:Toward Mechanic-Aware Creative Game Generation
Apr 21, 2026Large language models can generate plausible game code, but turning this capability into \emph{iterative creative improvement} remains difficult. In practice, single-shot generation often produces brittle runtime behavior, weak accumulation of experience across versions, and creativity scores that are too subjective to serve as reliable optimization signals. A further limitation is that mechanics are frequently treated only as post-hoc descriptions, rather than as explicit objects that can be planned, tracked, preserved, and evaluated during generation. This report presents \textbf{CreativeGame}, a multi-agent system for iterative HTML5 game generation that addresses these issues through four coupled ideas: a proxy reward centered on programmatic signals rather than pure LLM judgment; lineage-scoped memory for cross-version experience accumulation; runtime validation integrated into both repair and reward; and a mechanic-guided planning loop in which retrieved mechanic knowledge is converted into an explicit mechanic plan before code generation begins. The goal is not merely to produce a playable artifact in one step, but to support interpretable version-to-version evolution. The current system contains 71 stored lineages, 88 saved nodes, and a 774-entry global mechanic archive, implemented in 6{,}181 lines of Python together with inspection and visualization tooling. The system is therefore substantial enough to support architectural analysis, reward inspection, and real lineage-level case studies rather than only prompt-level demos. A real 4-generation lineage shows that mechanic-level innovation can emerge in later versions and can be inspected directly through version-to-version records. The central contribution is therefore not only game generation, but a concrete pipeline for observing progressive evolution through explicit mechanic change.
Towards Cold-Start Drafting and Continual Refining: A Value-Driven Memory Approach with Application to NPU Kernel Synthesis
Mar 11, 2026Deploying Large Language Models to data-scarce programming domains poses significant challenges, particularly for kernel synthesis on emerging Domain-Specific Architectures where a "Data Wall" limits available training data. While models excel on data-rich platforms like CUDA, they suffer catastrophic performance drops on data-scarce ecosystems such as NPU programming. To overcome this cold-start barrier without expensive fine-tuning, we introduce EvoKernel, a self-evolving agentic framework that automates the lifecycle of kernel synthesis from initial drafting to continual refining. EvoKernel addresses this by formulating the synthesis process as a memory-based reinforcement learning task. Through a novel value-driven retrieval mechanism, it learns stage-specific Q-values that prioritize experiences based on their contribution to the current objective, whether bootstrapping a feasible draft or iteratively refining latency. Furthermore, by enabling cross-task memory sharing, the agent generalizes insights from simple to complex operators. By building an NPU variant of KernelBench and evaluating on it, EvoKernel improves frontier models' correctness from 11.0% to 83.0% and achieves a median speedup of 3.60x over initial drafts through iterative refinement. This demonstrates that value-guided experience accumulation allows general-purpose models to master the kernel synthesis task on niche hardware ecosystems. Our official page is available at https://evokernel.zhuo.li.
Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity
Feb 03, 2026LLM-based multi-agent systems (MAS) have emerged as a promising approach to tackle complex tasks that are difficult for individual LLMs. A natural strategy is to scale performance by increasing the number of agents; however, we find that such scaling exhibits strong diminishing returns in homogeneous settings, while introducing heterogeneity (e.g., different models, prompts, or tools) continues to yield substantial gains. This raises a fundamental question: what limits scaling, and why does diversity help? We present an information-theoretic framework showing that MAS performance is bounded by the intrinsic task uncertainty, not by agent count. We derive architecture-agnostic bounds demonstrating that improvements depend on how many effective channels the system accesses. Homogeneous agents saturate early because their outputs are strongly correlated, whereas heterogeneous agents contribute complementary evidence. We further introduce $K^*$, an effective channel count that quantifies the number of effective channels without ground-truth labels. Empirically, we show that heterogeneous configurations consistently outperform homogeneous scaling: 2 diverse agents can match or exceed the performance of 16 homogeneous agents. Our results provide principled guidelines for building efficient and robust MAS through diversity-aware design. Code and Dataset are available at the link: https://github.com/SafeRL-Lab/Agent-Scaling.
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
Jan 06, 2026The hallmark of human intelligence is the ability to master new skills through Constructive Episodic Simulation-retrieving past experiences to synthesize solutions for novel tasks. While Large Language Models possess strong reasoning capabilities, they struggle to emulate this self-evolution: fine-tuning is computationally expensive and prone to catastrophic forgetting, while existing memory-based methods rely on passive semantic matching that often retrieves noise. To address these challenges, we propose MemRL, a framework that enables agents to self-evolve via non-parametric reinforcement learning on episodic memory. MemRL explicitly separates the stable reasoning of a frozen LLM from the plastic, evolving memory. Unlike traditional methods, MemRL employs a Two-Phase Retrieval mechanism that filters candidates by semantic relevance and then selects them based on learned Q-values (utility). These utilities are continuously refined via environmental feedback in an trial-and-error manner, allowing the agent to distinguish high-value strategies from similar noise. Extensive experiments on HLE, BigCodeBench, ALFWorld, and Lifelong Agent Bench demonstrate that MemRL significantly outperforms state-of-the-art baselines. Our analysis experiments confirm that MemRL effectively reconciles the stability-plasticity dilemma, enabling continuous runtime improvement without weight updates.
MARFT: Multi-Agent Reinforcement Fine-Tuning
Apr 24, 2025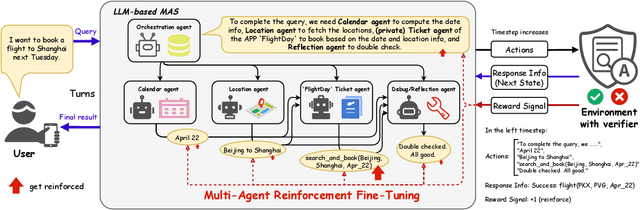


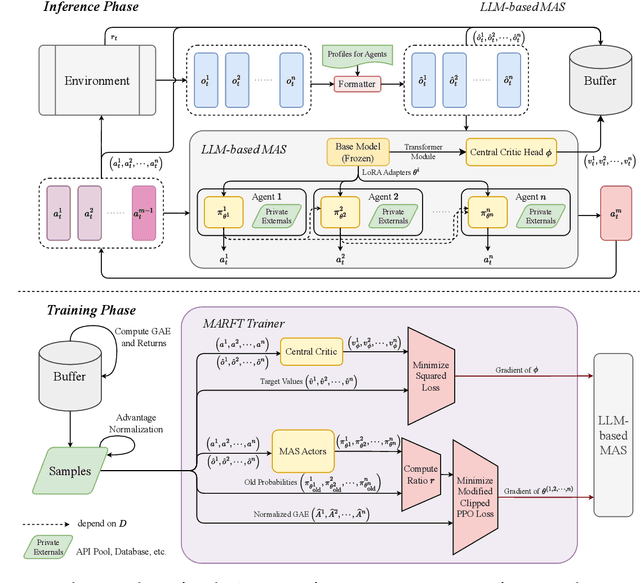
LLM-based Multi-Agent Systems have demonstrated remarkable capabilities in addressing complex, agentic tasks requiring multifaceted reasoning and collaboration, from generating high-quality presentation slides to conducting sophisticated scientific research. Meanwhile, RL has been widely recognized for its effectiveness in enhancing agent intelligence, but limited research has investigated the fine-tuning of LaMAS using foundational RL techniques. Moreover, the direct application of MARL methodologies to LaMAS introduces significant challenges, stemming from the unique characteristics and mechanisms inherent to LaMAS. To address these challenges, this article presents a comprehensive study of LLM-based MARL and proposes a novel paradigm termed Multi-Agent Reinforcement Fine-Tuning (MARFT). We introduce a universal algorithmic framework tailored for LaMAS, outlining the conceptual foundations, key distinctions, and practical implementation strategies. We begin by reviewing the evolution from RL to Reinforcement Fine-Tuning, setting the stage for a parallel analysis in the multi-agent domain. In the context of LaMAS, we elucidate critical differences between MARL and MARFT. These differences motivate a transition toward a novel, LaMAS-oriented formulation of RFT. Central to this work is the presentation of a robust and scalable MARFT framework. We detail the core algorithm and provide a complete, open-source implementation to facilitate adoption and further research. The latter sections of the paper explore real-world application perspectives and opening challenges in MARFT. By bridging theoretical underpinnings with practical methodologies, this work aims to serve as a roadmap for researchers seeking to advance MARFT toward resilient and adaptive solutions in agentic systems. Our implementation of the proposed framework is publicly available at: https://github.com/jwliao-ai/MARFT.
A Survey of AI Agent Protocols
Apr 23, 2025The rapid development of large language models (LLMs) has led to the widespread deployment of LLM agents across diverse industries, including customer service, content generation, data analysis, and even healthcare. However, as more LLM agents are deployed, a major issue has emerged: there is no standard way for these agents to communicate with external tools or data sources. This lack of standardized protocols makes it difficult for agents to work together or scale effectively, and it limits their ability to tackle complex, real-world tasks. A unified communication protocol for LLM agents could change this. It would allow agents and tools to interact more smoothly, encourage collaboration, and triggering the formation of collective intelligence. In this paper, we provide a systematic overview of existing communication protocols for LLM agents. We classify them into four main categories and make an analysis to help users and developers select the most suitable protocols for specific applications. Additionally, we conduct a comparative performance analysis of these protocols across key dimensions such as security, scalability, and latency. Finally, we explore future challenges, such as how protocols can adapt and survive in fast-evolving environments, and what qualities future protocols might need to support the next generation of LLM agent ecosystems. We expect this work to serve as a practical reference for both researchers and engineers seeking to design, evaluate, or integrate robust communication infrastructures for intelligent agents.
Robust Gymnasium: A Unified Modular Benchmark for Robust Reinforcement Learning
Feb 27, 2025



Driven by inherent uncertainty and the sim-to-real gap, robust reinforcement learning (RL) seeks to improve resilience against the complexity and variability in agent-environment sequential interactions. Despite the existence of a large number of RL benchmarks, there is a lack of standardized benchmarks for robust RL. Current robust RL policies often focus on a specific type of uncertainty and are evaluated in distinct, one-off environments. In this work, we introduce Robust-Gymnasium, a unified modular benchmark designed for robust RL that supports a wide variety of disruptions across all key RL components-agents' observed state and reward, agents' actions, and the environment. Offering over sixty diverse task environments spanning control and robotics, safe RL, and multi-agent RL, it provides an open-source and user-friendly tool for the community to assess current methods and foster the development of robust RL algorithms. In addition, we benchmark existing standard and robust RL algorithms within this framework, uncovering significant deficiencies in each and offering new insights.
PMAT: Optimizing Action Generation Order in Multi-Agent Reinforcement Learning
Feb 23, 2025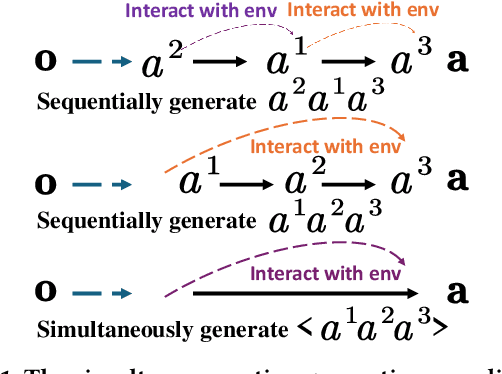
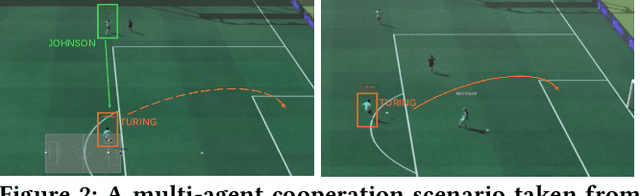
Multi-agent reinforcement learning (MARL) faces challenges in coordinating agents due to complex interdependencies within multi-agent systems. Most MARL algorithms use the simultaneous decision-making paradigm but ignore the action-level dependencies among agents, which reduces coordination efficiency. In contrast, the sequential decision-making paradigm provides finer-grained supervision for agent decision order, presenting the potential for handling dependencies via better decision order management. However, determining the optimal decision order remains a challenge. In this paper, we introduce Action Generation with Plackett-Luce Sampling (AGPS), a novel mechanism for agent decision order optimization. We model the order determination task as a Plackett-Luce sampling process to address issues such as ranking instability and vanishing gradient during the network training process. AGPS realizes credit-based decision order determination by establishing a bridge between the significance of agents' local observations and their decision credits, thus facilitating order optimization and dependency management. Integrating AGPS with the Multi-Agent Transformer, we propose the Prioritized Multi-Agent Transformer (PMAT), a sequential decision-making MARL algorithm with decision order optimization. Experiments on benchmarks including StarCraft II Multi-Agent Challenge, Google Research Football, and Multi-Agent MuJoCo show that PMAT outperforms state-of-the-art algorithms, greatly enhancing coordination efficiency.
Learning Humanoid Standing-up Control across Diverse Postures
Feb 12, 2025Standing-up control is crucial for humanoid robots, with the potential for integration into current locomotion and loco-manipulation systems, such as fall recovery. Existing approaches are either limited to simulations that overlook hardware constraints or rely on predefined ground-specific motion trajectories, failing to enable standing up across postures in real-world scenes. To bridge this gap, we present HoST (Humanoid Standing-up Control), a reinforcement learning framework that learns standing-up control from scratch, enabling robust sim-to-real transfer across diverse postures. HoST effectively learns posture-adaptive motions by leveraging a multi-critic architecture and curriculum-based training on diverse simulated terrains. To ensure successful real-world deployment, we constrain the motion with smoothness regularization and implicit motion speed bound to alleviate oscillatory and violent motions on physical hardware, respectively. After simulation-based training, the learned control policies are directly deployed on the Unitree G1 humanoid robot. Our experimental results demonstrate that the controllers achieve smooth, stable, and robust standing-up motions across a wide range of laboratory and outdoor environments. Videos are available at https://taohuang13.github.io/humanoid-standingup.github.io/.
HammerBench: Fine-Grained Function-Calling Evaluation in Real Mobile Device Scenarios
Dec 21, 2024



Evaluating the capabilities of large language models (LLMs) in human-LLM interactions remains challenging due to the inherent complexity and openness of dialogue processes. This paper introduces HammerBench, a novel benchmarking framework designed to assess the function-calling ability of LLMs more effectively in such interactions. We model a wide range of real-world user scenarios on mobile devices, encompassing imperfect instructions, diverse question-answer trajectories, intent/argument shifts, and the use of external individual information through pronouns. To construct the corresponding datasets, we propose a comprehensive pipeline that involves LLM-generated data and multiple rounds of human validation, ensuring high data quality. Additionally, we decompose the conversations into function-calling snapshots, enabling a fine-grained evaluation of each turn. We evaluate several popular LLMs using HammerBench and highlight different performance aspects. Our empirical findings reveal that errors in parameter naming constitute the primary factor behind conversation failures across different data types.