 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
Mar 22, 2026Recent progress in multimodal large language models has led to strong performance on reasoning tasks, but these improvements largely rely on high-quality annotated data or teacher-model distillation, both of which are costly and difficult to scale.To address this, we propose an unsupervised self-evolution training framework for multimodal reasoning that achieves stable performance improvements without using human-annotated answers or external reward models. For each input, we sample multiple reasoning trajectories and jointly model their within group structure.We use the Actor's self-consistency signal as a training prior, and introduce a bounded Judge based modulation to continuously reweight trajectories of different quality.We further model the modulated scores as a group level distribution and convert absolute scores into relative advantages within each group, enabling more robust policy updates. Trained with Group Relative Policy Optimization (GRPO) on unlabeled data, our method consistently improves reasoning performance and generalization on five mathematical reasoning benchmarks, offering a scalable path toward self-evolving multimodal models.The code are available at https://dingwu1021.github.io/SelfJudge/.
DB-Explore: Automated Database Exploration and Instruction Synthesis for Text-to-SQL
Mar 06, 2025Recent text-to-SQL systems powered by large language models (LLMs) have demonstrated remarkable performance in translating natural language queries into SQL. However, these systems often struggle with complex database structures and domain-specific queries, as they primarily focus on enhancing logical reasoning and SQL syntax while overlooking the critical need for comprehensive database understanding. To address this limitation, we propose DB-Explore, a novel framework that systematically aligns LLMs with database knowledge through automated exploration and instruction synthesis. DB-Explore constructs database graphs to capture complex relational schemas, leverages GPT-4 to systematically mine structural patterns and semantic knowledge, and synthesizes instructions to distill this knowledge for efficient fine-tuning of LLMs. Our framework enables comprehensive database understanding through diverse sampling strategies and automated instruction generation, bridging the gap between database structures and language models. Experiments conducted on the SPIDER and BIRD benchmarks validate the effectiveness of DB-Explore, achieving an execution accuracy of 52.1% on BIRD and 84.0% on SPIDER. Notably, our open-source implementation, based on the Qwen2.5-coder-7B model, outperforms multiple GPT-4-driven text-to-SQL systems in comparative evaluations, and achieves near state-of-the-art performance with minimal computational cost.
AskToAct: Enhancing LLMs Tool Use via Self-Correcting Clarification
Mar 03, 2025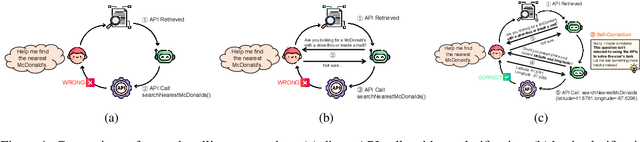
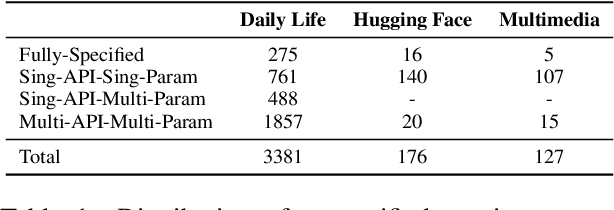
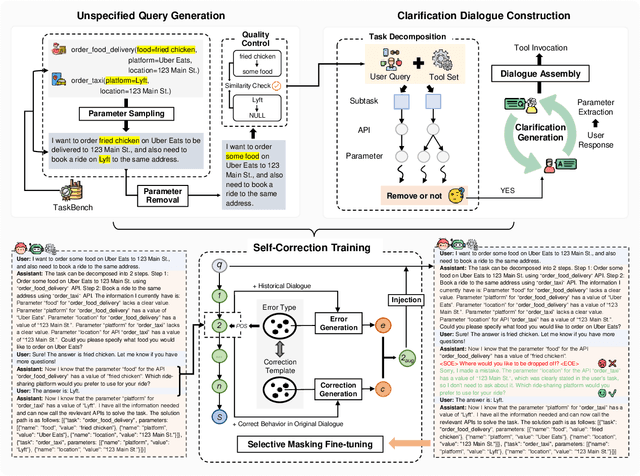

Large language models (LLMs) have demonstrated remarkable capabilities in tool learning. In real-world scenarios, user queries are often ambiguous and incomplete, requiring effective clarification. However, existing interactive clarification approaches face two critical limitations: reliance on manually constructed datasets and lack of error correction mechanisms during multi-turn clarification. We present AskToAct, which addresses these challenges by exploiting the structural mapping between queries and their tool invocation solutions. Our key insight is that tool parameters naturally represent explicit user intents. By systematically removing key parameters from queries while retaining them as ground truth, we enable automated construction of high-quality training data. We further enhance model robustness by fine-tuning on error-correction augmented data using selective masking mechanism, enabling dynamic error detection during clarification interactions. Comprehensive experiments demonstrate that AskToAct significantly outperforms existing approaches, achieving above 79% accuracy in recovering critical unspecified intents and enhancing clarification efficiency by an average of 48.34% while maintaining high accuracy in tool invocation. Our framework exhibits robust performance across varying complexity levels and successfully generalizes to entirely unseen APIs without additional training, achieving performance comparable to GPT-4 with substantially fewer computational resources.
STaR-SQL: Self-Taught Reasoner for Text-to-SQL
Feb 19, 2025



Generating step-by-step "chain-of-thought" rationales has proven effective for improving the performance of large language models on complex reasoning tasks. However, applying such techniques to structured tasks, such as text-to-SQL, remains largely unexplored. In this paper, we introduce Self-Taught Reasoner for text-to-SQL (STaR-SQL), a novel approach that reframes SQL query generation as a reasoning-driven process. Our method prompts the LLM to produce detailed reasoning steps for SQL queries and fine-tunes it on rationales that lead to correct outcomes. Unlike traditional methods, STaR-SQL dedicates additional test-time computation to reasoning, thereby positioning LLMs as spontaneous reasoners rather than mere prompt-based agents. To further scale the inference process, we incorporate an outcome-supervised reward model (ORM) as a verifier, which enhances SQL query accuracy. Experimental results on the challenging Spider benchmark demonstrate that STaR-SQL significantly improves text-to-SQL performance, achieving an execution accuracy of 86.6%. This surpasses a few-shot baseline by 31.6% and a baseline fine-tuned to predict answers directly by 18.0%. Additionally, STaR-SQL outperforms agent-like prompting methods that leverage more powerful yet closed-source models such as GPT-4. These findings underscore the potential of reasoning-augmented training for structured tasks and open the door to extending self-improving reasoning models to text-to-SQL generation and beyond.
HammerBench: Fine-Grained Function-Calling Evaluation in Real Mobile Device Scenarios
Dec 21, 2024



Evaluating the capabilities of large language models (LLMs) in human-LLM interactions remains challenging due to the inherent complexity and openness of dialogue processes. This paper introduces HammerBench, a novel benchmarking framework designed to assess the function-calling ability of LLMs more effectively in such interactions. We model a wide range of real-world user scenarios on mobile devices, encompassing imperfect instructions, diverse question-answer trajectories, intent/argument shifts, and the use of external individual information through pronouns. To construct the corresponding datasets, we propose a comprehensive pipeline that involves LLM-generated data and multiple rounds of human validation, ensuring high data quality. Additionally, we decompose the conversations into function-calling snapshots, enabling a fine-grained evaluation of each turn. We evaluate several popular LLMs using HammerBench and highlight different performance aspects. Our empirical findings reveal that errors in parameter naming constitute the primary factor behind conversation failures across different data types.
Multi-LLM-Agent Systems: Techniques and Business Perspectives
Nov 21, 2024


In the era of (multi-modal) large language models, most operational processes can be reformulated and reproduced using LLM agents. The LLM agents can perceive, control, and get feedback from the environment so as to accomplish the given tasks in an autonomous manner. Besides the environment-interaction property, the LLM agents can call various external tools to ease the task completion process. The tools can be regarded as a predefined operational process with private or real-time knowledge that does not exist in the parameters of LLMs. As a natural trend of development, the tools for calling are becoming autonomous agents, thus the full intelligent system turns out to be a multi-LLM-agent system (MLAS). This paper discusses the technical and business landscapes of MLAS. Compared to the previous single-LLM-agent system, a MLAS has the advantages of i) higher potential of task-solving performance, ii) higher flexibility for system changing, iii) proprietary data preserving for each participating entity, and iv) feasibility of monetization for each entity. To support the ecosystem of MLAS, we provide a preliminary version of such MLAS protocol considering technical requirements, data privacy, and business incentives. As such, MLAS would be a practical solution to achieve artificial collective intelligence in the near future.
Hammer: Robust Function-Calling for On-Device Language Models via Function Masking
Oct 06, 2024
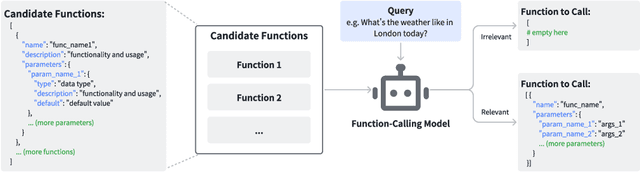


Large language models have demonstrated impressive value in performing as autonomous agents when equipped with external tools and API calls. Nonetheless, effectively harnessing their potential for executing complex tasks crucially relies on enhancements in their function calling capabilities. This paper identifies a critical gap in existing function calling models, where performance varies significantly across benchmarks, often due to being misled by specific naming conventions. To address such an issue, we introduce Hammer, a novel family of foundation models specifically engineered for on-device function calling. Hammer employs an augmented dataset that enhances models' sensitivity to irrelevant functions and incorporates function masking techniques to minimize misleading. Our empirical evaluations reveal that Hammer not only outperforms larger models but also demonstrates robust generalization across diverse benchmarks, achieving sota results. Our open source contributions include a specialized dataset for irrelevance detection, a tuning framework for enhanced generalization, and the Hammer models, establishing a new standard for function calling performance.
Knowledge-aware Dual-side Attribute-enhanced Recommendation
Mar 24, 2024



\textit{Knowledge-aware} recommendation methods (KGR) based on \textit{graph neural networks} (GNNs) and \textit{contrastive learning} (CL) have achieved promising performance. However, they fall short in modeling fine-grained user preferences and further fail to leverage the \textit{preference-attribute connection} to make predictions, leading to sub-optimal performance. To address the issue, we propose a method named \textit{\textbf{K}nowledge-aware \textbf{D}ual-side \textbf{A}ttribute-enhanced \textbf{R}ecommendation} (KDAR). Specifically, we build \textit{user preference representations} and \textit{attribute fusion representations} upon the attribute information in knowledge graphs, which are utilized to enhance \textit{collaborative filtering} (CF) based user and item representations, respectively. To discriminate the contribution of each attribute in these two types of attribute-based representations, a \textit{multi-level collaborative alignment contrasting} mechanism is proposed to align the importance of attributes with CF signals. Experimental results on four benchmark datasets demonstrate the superiority of KDAR over several state-of-the-art baselines. Further analyses verify the effectiveness of our method. The code of KDAR is released at: \href{https://github.com/TJTP/KDAR}{https://github.com/TJTP/KDAR}.
A Framework to Implement 1+N Multi-task Fine-tuning Pattern in LLMs Using the CGC-LORA Algorithm
Jan 22, 2024With the productive evolution of large language models (LLMs) in the field of natural language processing (NLP), tons of effort has been made to effectively fine-tune common pre-trained LLMs to fulfill a variety of tasks in one or multiple specific domain. In practice, there are two prevailing ways, in which the adaptation can be achieved: (i) Multiple Independent Models: Pre-trained LLMs are fine-tuned a few times independently using the corresponding training samples from each task. (ii) An Integrated Model: Samples from all tasks are employed to fine-tune a pre-trianed LLM unitedly. To address the high computing cost and seesawing issue simultaneously, we propose a unified framework that implements a 1 + N mutli-task fine-tuning pattern in LLMs using a novel Customized Gate Control (CGC) Low-rank Adaptation (LoRA) algorithm. Our work aims to take an advantage of both MTL (i.e., CGC) and PEFT (i.e., LoRA) scheme. For a given cluster of tasks, we design an innovative layer that contains two types of experts as additional trainable parameters to make LoRA be compatible with MTL. To comprehensively evaluate the proposed framework, we conduct well-designed experiments on two public datasets. The experimental results demonstrate that the unified framework with CGC-LoRA modules achieves higher evaluation scores than all benchmarks on both two datasets.
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives
Jan 04, 2024



The reflection capacity of Large Language Model (LLM) has garnered extensive attention. A post-hoc prompting strategy, e.g., reflexion and self-refine, refines LLM's response based on self-evaluated or external feedback. However, recent research indicates without external feedback, LLM's intrinsic reflection is unstable. Our investigation unveils that the key bottleneck is the quality of the self-evaluated feedback. We find LLMs often exhibit overconfidence or high randomness when self-evaluate, offering stubborn or inconsistent feedback, which causes poor reflection. To remedy this, we advocate Self-Contrast: It adaptively explores diverse solving perspectives tailored to the request, contrasts the differences, and summarizes these discrepancies into a checklist which could be used to re-examine and eliminate discrepancies. Our method endows LLM with diverse perspectives to alleviate stubborn biases. Moreover, their discrepancies indicate potential errors or inherent uncertainties that LLM often overlooks. Reflecting upon these can catalyze more accurate and stable reflection. Experiments conducted on a series of reasoning and translation tasks with different LLMs serve to underscore the effectiveness and generality of our strategy.