 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Wideband Spectrum Sensing with Dual-Representation Inputs and Subband Shuffling Augmentation
Apr 10, 2025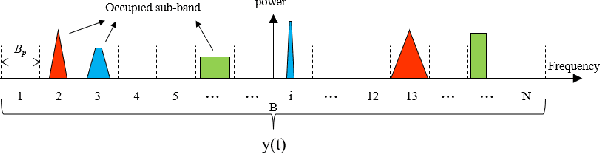
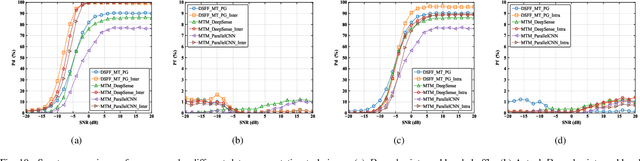
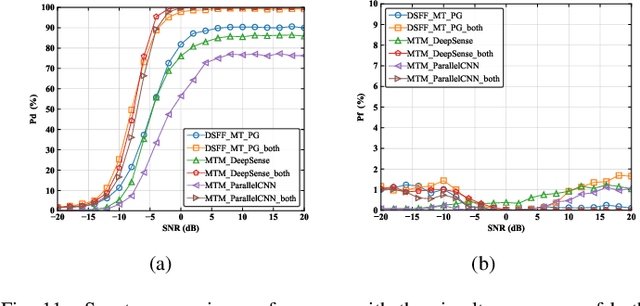
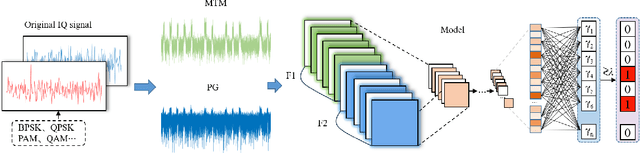
The widespread adoption of mobile communication technology has led to a severe shortage of spectrum resources, driving the development of cognitive radio technologies aimed at improving spectrum utilization, with spectrum sensing being the key enabler. This paper presents a novel deep learning-based wideband spectrum sensing framework that leverages multi-taper power spectral inputs to achieve high-precision and sample-efficient sensing. To enhance sensing accuracy, we incorporate a feature fusion strategy that combines multiple power spectrum representations. To tackle the challenge of limited sample sizes, we propose two data augmentation techniques designed to expand the training set and improve the network's detection probability. Comprehensive simulation results demonstrate that our method outperforms existing approaches, particularly in low signal-to-noise ratio conditions, achieving higher detection probabilities and lower false alarm rates. The method also exhibits strong robustness across various scenarios, highlighting its significant potential for practical applications in wireless communication systems.
A Framework to Implement 1+N Multi-task Fine-tuning Pattern in LLMs Using the CGC-LORA Algorithm
Jan 22, 2024With the productive evolution of large language models (LLMs) in the field of natural language processing (NLP), tons of effort has been made to effectively fine-tune common pre-trained LLMs to fulfill a variety of tasks in one or multiple specific domain. In practice, there are two prevailing ways, in which the adaptation can be achieved: (i) Multiple Independent Models: Pre-trained LLMs are fine-tuned a few times independently using the corresponding training samples from each task. (ii) An Integrated Model: Samples from all tasks are employed to fine-tune a pre-trianed LLM unitedly. To address the high computing cost and seesawing issue simultaneously, we propose a unified framework that implements a 1 + N mutli-task fine-tuning pattern in LLMs using a novel Customized Gate Control (CGC) Low-rank Adaptation (LoRA) algorithm. Our work aims to take an advantage of both MTL (i.e., CGC) and PEFT (i.e., LoRA) scheme. For a given cluster of tasks, we design an innovative layer that contains two types of experts as additional trainable parameters to make LoRA be compatible with MTL. To comprehensively evaluate the proposed framework, we conduct well-designed experiments on two public datasets. The experimental results demonstrate that the unified framework with CGC-LoRA modules achieves higher evaluation scores than all benchmarks on both two datasets.
AdaptSSR: Pre-training User Model with Augmentation-Adaptive Self-Supervised Ranking
Oct 24, 2023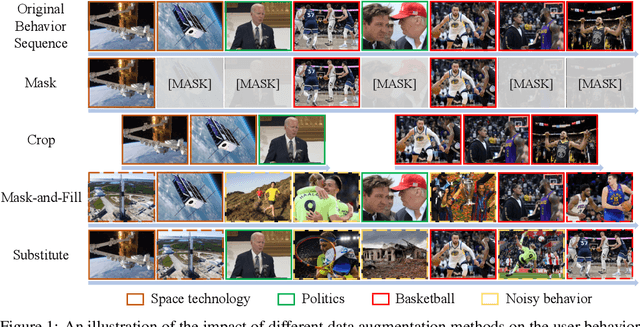
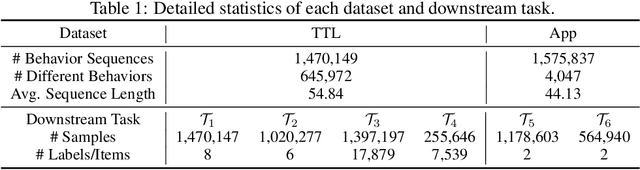
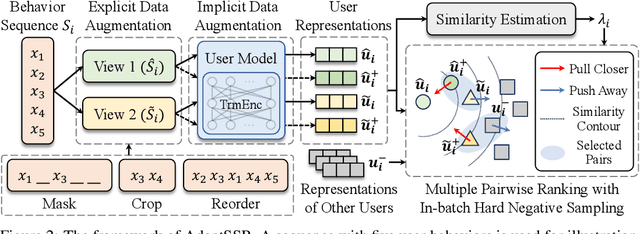
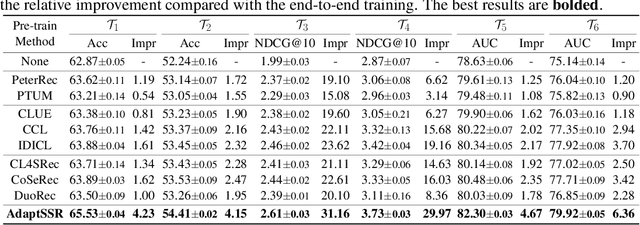
User modeling, which aims to capture users' characteristics or interests, heavily relies on task-specific labeled data and suffers from the data sparsity issue. Several recent studies tackled this problem by pre-training the user model on massive user behavior sequences with a contrastive learning task. Generally, these methods assume different views of the same behavior sequence constructed via data augmentation are semantically consistent, i.e., reflecting similar characteristics or interests of the user, and thus maximizing their agreement in the feature space. However, due to the diverse interests and heavy noise in user behaviors, existing augmentation methods tend to lose certain characteristics of the user or introduce noisy behaviors. Thus, forcing the user model to directly maximize the similarity between the augmented views may result in a negative transfer. To this end, we propose to replace the contrastive learning task with a new pretext task: Augmentation-Adaptive SelfSupervised Ranking (AdaptSSR), which alleviates the requirement of semantic consistency between the augmented views while pre-training a discriminative user model. Specifically, we adopt a multiple pairwise ranking loss which trains the user model to capture the similarity orders between the implicitly augmented view, the explicitly augmented view, and views from other users. We further employ an in-batch hard negative sampling strategy to facilitate model training. Moreover, considering the distinct impacts of data augmentation on different behavior sequences, we design an augmentation-adaptive fusion mechanism to automatically adjust the similarity order constraint applied to each sample based on the estimated similarity between the augmented views. Extensive experiments on both public and industrial datasets with six downstream tasks verify the effectiveness of AdaptSSR.
Imitator Learning: Achieve Out-of-the-Box Imitation Ability in Variable Environments
Oct 09, 2023

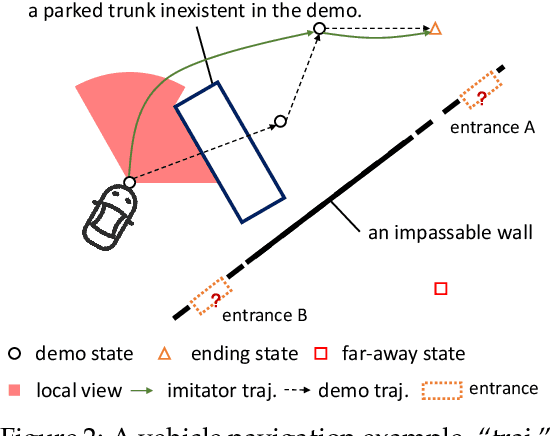

Imitation learning (IL) enables agents to mimic expert behaviors. Most previous IL techniques focus on precisely imitating one policy through mass demonstrations. However, in many applications, what humans require is the ability to perform various tasks directly through a few demonstrations of corresponding tasks, where the agent would meet many unexpected changes when deployed. In this scenario, the agent is expected to not only imitate the demonstration but also adapt to unforeseen environmental changes. This motivates us to propose a new topic called imitator learning (ItorL), which aims to derive an imitator module that can on-the-fly reconstruct the imitation policies based on very limited expert demonstrations for different unseen tasks, without any extra adjustment. In this work, we focus on imitator learning based on only one expert demonstration. To solve ItorL, we propose Demo-Attention Actor-Critic (DAAC), which integrates IL into a reinforcement-learning paradigm that can regularize policies' behaviors in unexpected situations. Besides, for autonomous imitation policy building, we design a demonstration-based attention architecture for imitator policy that can effectively output imitated actions by adaptively tracing the suitable states in demonstrations. We develop a new navigation benchmark and a robot environment for \topic~and show that DAAC~outperforms previous imitation methods \textit{with large margins} both on seen and unseen tasks.