 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny-step Dynamics Model Improves Future Predictions for Online and Offline Reinforcement Learning
May 27, 2024Model-based methods in reinforcement learning offer a promising approach to enhance data efficiency by facilitating policy exploration within a dynamics model. However, accurately predicting sequential steps in the dynamics model remains a challenge due to the bootstrapping prediction, which attributes the next state to the prediction of the current state. This leads to accumulated errors during model roll-out. In this paper, we propose the Any-step Dynamics Model (ADM) to mitigate the compounding error by reducing bootstrapping prediction to direct prediction. ADM allows for the use of variable-length plans as inputs for predicting future states without frequent bootstrapping. We design two algorithms, ADMPO-ON and ADMPO-OFF, which apply ADM in online and offline model-based frameworks, respectively. In the online setting, ADMPO-ON demonstrates improved sample efficiency compared to previous state-of-the-art methods. In the offline setting, ADMPO-OFF not only demonstrates superior performance compared to recent state-of-the-art offline approaches but also offers better quantification of model uncertainty using only a single ADM.
Imitator Learning: Achieve Out-of-the-Box Imitation Ability in Variable Environments
Oct 09, 2023Imitation learning (IL) enables agents to mimic expert behaviors. Most previous IL techniques focus on precisely imitating one policy through mass demonstrations. However, in many applications, what humans require is the ability to perform various tasks directly through a few demonstrations of corresponding tasks, where the agent would meet many unexpected changes when deployed. In this scenario, the agent is expected to not only imitate the demonstration but also adapt to unforeseen environmental changes. This motivates us to propose a new topic called imitator learning (ItorL), which aims to derive an imitator module that can on-the-fly reconstruct the imitation policies based on very limited expert demonstrations for different unseen tasks, without any extra adjustment. In this work, we focus on imitator learning based on only one expert demonstration. To solve ItorL, we propose Demo-Attention Actor-Critic (DAAC), which integrates IL into a reinforcement-learning paradigm that can regularize policies' behaviors in unexpected situations. Besides, for autonomous imitation policy building, we design a demonstration-based attention architecture for imitator policy that can effectively output imitated actions by adaptively tracing the suitable states in demonstrations. We develop a new navigation benchmark and a robot environment for \topic~and show that DAAC~outperforms previous imitation methods \textit{with large margins} both on seen and unseen tasks.
Tips and Tricks for Webly-Supervised Fine-Grained Recognition: Learning from the WebFG 2020 Challenge
Dec 29, 2020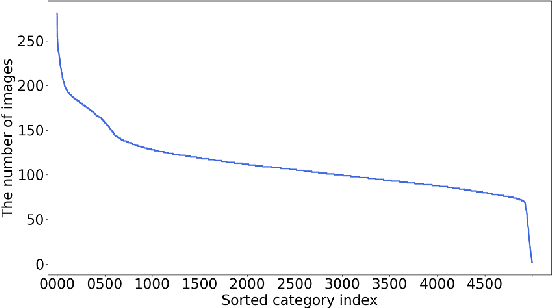
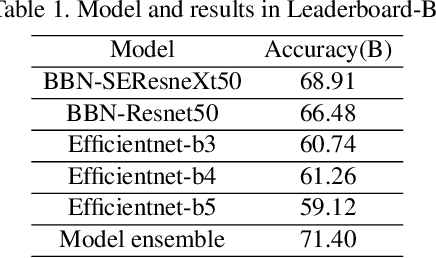

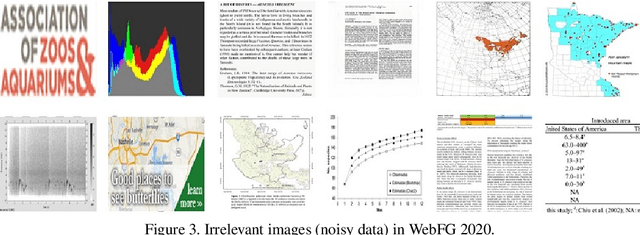
WebFG 2020 is an international challenge hosted by Nanjing University of Science and Technology, University of Edinburgh, Nanjing University, The University of Adelaide, Waseda University, etc. This challenge mainly pays attention to the webly-supervised fine-grained recognition problem. In the literature, existing deep learning methods highly rely on large-scale and high-quality labeled training data, which poses a limitation to their practicability and scalability in real world applications. In particular, for fine-grained recognition, a visual task that requires professional knowledge for labeling, the cost of acquiring labeled training data is quite high. It causes extreme difficulties to obtain a large amount of high-quality training data. Therefore, utilizing free web data to train fine-grained recognition models has attracted increasing attentions from researchers in the fine-grained community. This challenge expects participants to develop webly-supervised fine-grained recognition methods, which leverages web images in training fine-grained recognition models to ease the extreme dependence of deep learning methods on large-scale manually labeled datasets and to enhance their practicability and scalability. In this technical report, we have pulled together the top WebFG 2020 solutions of total 54 competing teams, and discuss what methods worked best across the set of winning teams, and what surprisingly did not help.