 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Pre-training for Person Re-identification with Noisy Labels
Apr 04, 2022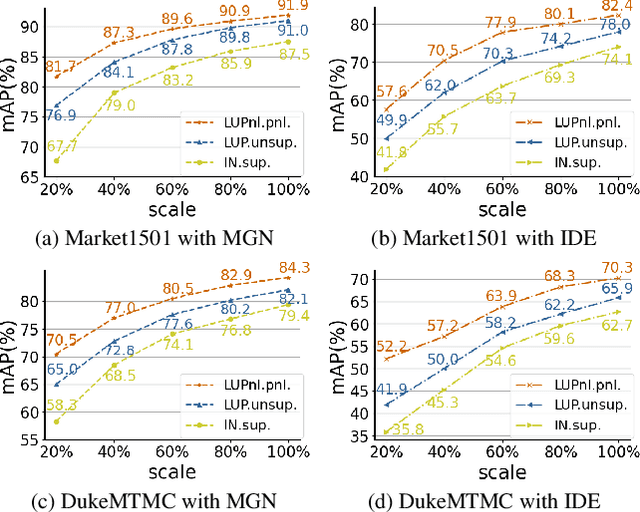
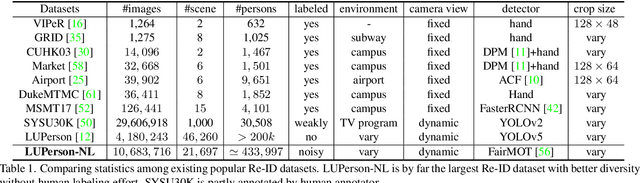
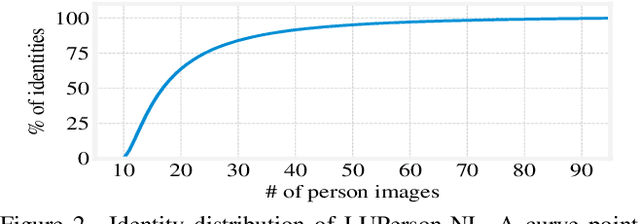
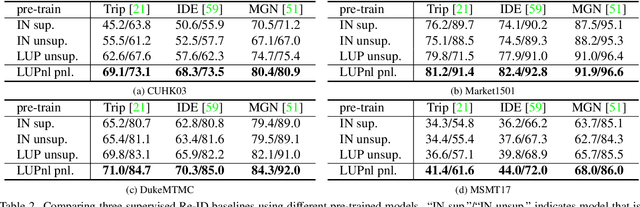
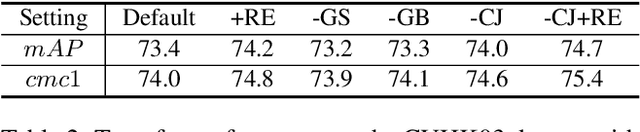
This paper aims to address the problem of pre-training for person re-identification (Re-ID) with noisy labels. To setup the pre-training task, we apply a simple online multi-object tracking system on raw videos of an existing unlabeled Re-ID dataset "LUPerson" nd build the Noisy Labeled variant called "LUPerson-NL". Since theses ID labels automatically derived from tracklets inevitably contain noises, we develop a large-scale Pre-training framework utilizing Noisy Labels (PNL), which consists of three learning modules: supervised Re-ID learning, prototype-based contrastive learning, and label-guided contrastive learning. In principle, joint learning of these three modules not only clusters similar examples to one prototype, but also rectifies noisy labels based on the prototype assignment. We demonstrate that learning directly from raw videos is a promising alternative for pre-training, which utilizes spatial and temporal correlations as weak supervision. This simple pre-training task provides a scalable way to learn SOTA Re-ID representations from scratch on "LUPerson-NL" without bells and whistles. For example, by applying on the same supervised Re-ID method MGN, our pre-trained model improves the mAP over the unsupervised pre-training counterpart by 5.7%, 2.2%, 2.3% on CUHK03, DukeMTMC, and MSMT17 respectively. Under the small-scale or few-shot setting, the performance gain is even more significant, suggesting a better transferability of the learned representation. Code is available at https://github.com/DengpanFu/LUPerson-NL
Tips and Tricks for Webly-Supervised Fine-Grained Recognition: Learning from the WebFG 2020 Challenge
Dec 29, 2020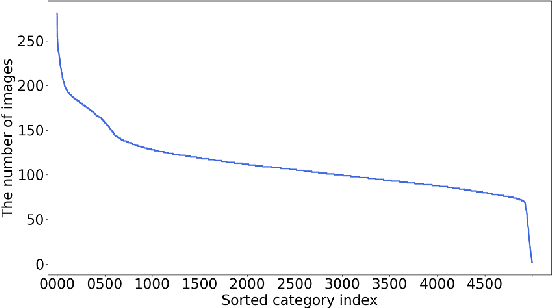
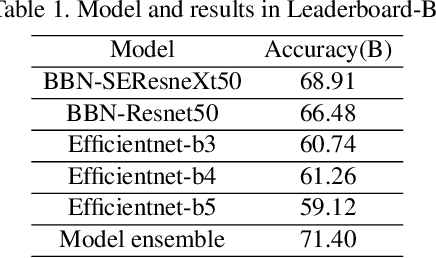

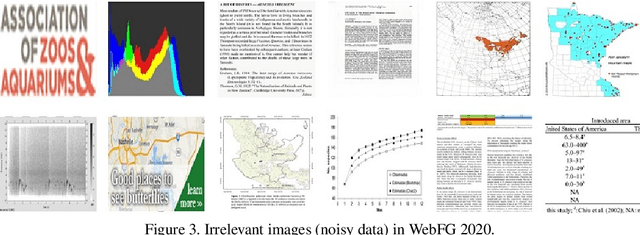
WebFG 2020 is an international challenge hosted by Nanjing University of Science and Technology, University of Edinburgh, Nanjing University, The University of Adelaide, Waseda University, etc. This challenge mainly pays attention to the webly-supervised fine-grained recognition problem. In the literature, existing deep learning methods highly rely on large-scale and high-quality labeled training data, which poses a limitation to their practicability and scalability in real world applications. In particular, for fine-grained recognition, a visual task that requires professional knowledge for labeling, the cost of acquiring labeled training data is quite high. It causes extreme difficulties to obtain a large amount of high-quality training data. Therefore, utilizing free web data to train fine-grained recognition models has attracted increasing attentions from researchers in the fine-grained community. This challenge expects participants to develop webly-supervised fine-grained recognition methods, which leverages web images in training fine-grained recognition models to ease the extreme dependence of deep learning methods on large-scale manually labeled datasets and to enhance their practicability and scalability. In this technical report, we have pulled together the top WebFG 2020 solutions of total 54 competing teams, and discuss what methods worked best across the set of winning teams, and what surprisingly did not help.
Unsupervised Pre-training for Person Re-identification
Dec 07, 2020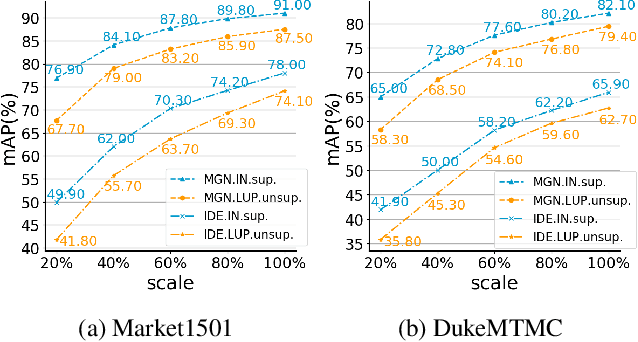
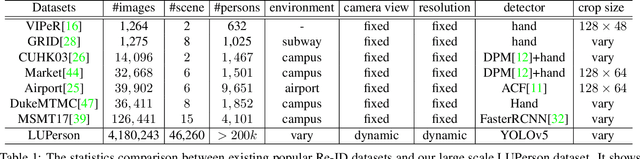

In this paper, we present a large scale unlabeled person re-identification (Re-ID) dataset "LUPerson" and make the first attempt of performing unsupervised pre-training for improving the generalization ability of the learned person Re-ID feature representation. This is to address the problem that all existing person Re-ID datasets are all of limited scale due to the costly effort required for data annotation. Previous research tries to leverage models pre-trained on ImageNet to mitigate the shortage of person Re-ID data but suffers from the large domain gap between ImageNet and person Re-ID data. LUPerson is an unlabeled dataset of 4M images of over 200K identities, which is 30X larger than the largest existing Re-ID dataset. It also covers a much diverse range of capturing environments (eg, camera settings, scenes, etc.). Based on this dataset, we systematically study the key factors for learning Re-ID features from two perspectives: data augmentation and contrastive loss. Unsupervised pre-training performed on this large-scale dataset effectively leads to a generic Re-ID feature that can benefit all existing person Re-ID methods. Using our pre-trained model in some basic frameworks, our methods achieve state-of-the-art results without bells and whistles on four widely used Re-ID datasets: CUHK03, Market1501, DukeMTMC, and MSMT17. Our results also show that the performance improvement is more significant on small-scale target datasets or under few-shot setting.
Improving Person Re-identification with Iterative Impression Aggregation
Sep 21, 2020

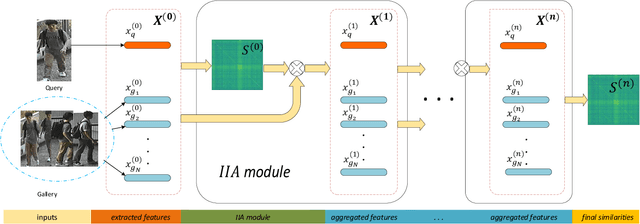

Our impression about one person often updates after we see more aspects of him/her and this process keeps iterating given more meetings. We formulate such an intuition into the problem of person re-identification (re-ID), where the representation of a query (probe) image is iteratively updated with new information from the candidates in the gallery. Specifically, we propose a simple attentional aggregation formulation to instantiate this idea and showcase that such a pipeline achieves competitive performance on standard benchmarks including CUHK03, Market-1501 and DukeMTMC. Not only does such a simple method improve the performance of the baseline models, it also achieves comparable performance with latest advanced re-ranking methods. Another advantage of this proposal is its flexibility to incorporate different representations and similarity metrics. By utilizing stronger representations and metrics, we further demonstrate state-of-the-art person re-ID performance, which also validates the general applicability of the proposed method.
Benchmarking Single Image Dehazing and Beyond
Aug 27, 2018
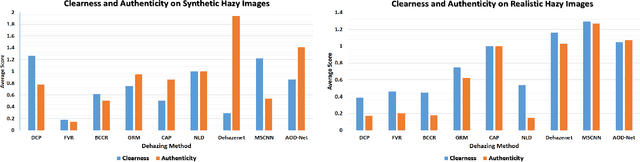


We present a comprehensive study and evaluation of existing single image dehazing algorithms, using a new large-scale benchmark consisting of both synthetic and real-world hazy images, called REalistic Single Image DEhazing (RESIDE). RESIDE highlights diverse data sources and image contents, and is divided into five subsets, each serving different training or evaluation purposes. We further provide a rich variety of criteria for dehazing algorithm evaluation, ranging from full-reference metrics, to no-reference metrics, to subjective evaluation and the novel task-driven evaluation. Experiments on RESIDE shed light on the comparisons and limitations of state-of-the-art dehazing algorithms, and suggest promising future directions.