 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalPaint: Spatiotemporal Coherent Video Outpainting with Global Feature Guidance
Jan 10, 2026Video outpainting extends a video beyond its original boundaries by synthesizing missing border content. Compared with image outpainting, it requires not only per-frame spatial plausibility but also long-range temporal coherence, especially when outpainted content becomes visible across time under camera or object motion. We propose GlobalPaint, a diffusion-based framework for spatiotemporal coherent video outpainting. Our approach adopts a hierarchical pipeline that first outpaints key frames and then completes intermediate frames via an interpolation model conditioned on the completed boundaries, reducing error accumulation in sequential processing. At the model level, we augment a pretrained image inpainting backbone with (i) an Enhanced Spatial-Temporal module featuring 3D windowed attention for stronger spatiotemporal interaction, and (ii) global feature guidance that distills OpenCLIP features from observed regions across all frames into compact global tokens using a dedicated extractor. Comprehensive evaluations on benchmark datasets demonstrate improved reconstruction quality and more natural motion compared to prior methods. Our demo page is https://yuemingpan.github.io/GlobalPaint/
ReasonGen-R1: CoT for Autoregressive Image generation models through SFT and RL
May 30, 2025Although chain-of-thought reasoning and reinforcement learning (RL) have driven breakthroughs in NLP, their integration into generative vision models remains underexplored. We introduce ReasonGen-R1, a two-stage framework that first imbues an autoregressive image generator with explicit text-based "thinking" skills via supervised fine-tuning on a newly generated reasoning dataset of written rationales, and then refines its outputs using Group Relative Policy Optimization. To enable the model to reason through text before generating images, We automatically generate and release a corpus of model crafted rationales paired with visual prompts, enabling controlled planning of object layouts, styles, and scene compositions. Our GRPO algorithm uses reward signals from a pretrained vision language model to assess overall visual quality, optimizing the policy in each update. Evaluations on GenEval, DPG, and the T2I benchmark demonstrate that ReasonGen-R1 consistently outperforms strong baselines and prior state-of-the-art models. More: aka.ms/reasongen.
Fast Autoregressive Models for Continuous Latent Generation
Apr 24, 2025Autoregressive models have demonstrated remarkable success in sequential data generation, particularly in NLP, but their extension to continuous-domain image generation presents significant challenges. Recent work, the masked autoregressive model (MAR), bypasses quantization by modeling per-token distributions in continuous spaces using a diffusion head but suffers from slow inference due to the high computational cost of the iterative denoising process. To address this, we propose the Fast AutoRegressive model (FAR), a novel framework that replaces MAR's diffusion head with a lightweight shortcut head, enabling efficient few-step sampling while preserving autoregressive principles. Additionally, FAR seamlessly integrates with causal Transformers, extending them from discrete to continuous token generation without requiring architectural modifications. Experiments demonstrate that FAR achieves $2.3\times$ faster inference than MAR while maintaining competitive FID and IS scores. This work establishes the first efficient autoregressive paradigm for high-fidelity continuous-space image generation, bridging the critical gap between quality and scalability in visual autoregressive modeling.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
DesignDiffusion: High-Quality Text-to-Design Image Generation with Diffusion Models
Mar 03, 2025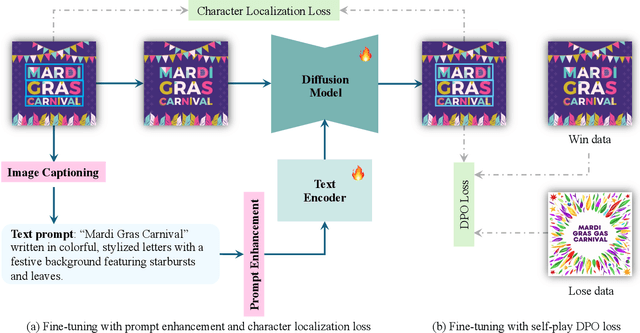



In this paper, we present DesignDiffusion, a simple yet effective framework for the novel task of synthesizing design images from textual descriptions. A primary challenge lies in generating accurate and style-consistent textual and visual content. Existing works in a related task of visual text generation often focus on generating text within given specific regions, which limits the creativity of generation models, resulting in style or color inconsistencies between textual and visual elements if applied to design image generation. To address this issue, we propose an end-to-end, one-stage diffusion-based framework that avoids intricate components like position and layout modeling. Specifically, the proposed framework directly synthesizes textual and visual design elements from user prompts. It utilizes a distinctive character embedding derived from the visual text to enhance the input prompt, along with a character localization loss for enhanced supervision during text generation. Furthermore, we employ a self-play Direct Preference Optimization fine-tuning strategy to improve the quality and accuracy of the synthesized visual text. Extensive experiments demonstrate that DesignDiffusion achieves state-of-the-art performance in design image generation.
ART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation
Feb 25, 2025Multi-layer image generation is a fundamental task that enables users to isolate, select, and edit specific image layers, thereby revolutionizing interactions with generative models. In this paper, we introduce the Anonymous Region Transformer (ART), which facilitates the direct generation of variable multi-layer transparent images based on a global text prompt and an anonymous region layout. Inspired by Schema theory suggests that knowledge is organized in frameworks (schemas) that enable people to interpret and learn from new information by linking it to prior knowledge.}, this anonymous region layout allows the generative model to autonomously determine which set of visual tokens should align with which text tokens, which is in contrast to the previously dominant semantic layout for the image generation task. In addition, the layer-wise region crop mechanism, which only selects the visual tokens belonging to each anonymous region, significantly reduces attention computation costs and enables the efficient generation of images with numerous distinct layers (e.g., 50+). When compared to the full attention approach, our method is over 12 times faster and exhibits fewer layer conflicts. Furthermore, we propose a high-quality multi-layer transparent image autoencoder that supports the direct encoding and decoding of the transparency of variable multi-layer images in a joint manner. By enabling precise control and scalable layer generation, ART establishes a new paradigm for interactive content creation.
Diffusion Models without Classifier-free Guidance
Feb 17, 2025This paper presents Model-guidance (MG), a novel objective for training diffusion model that addresses and removes of the commonly used Classifier-free guidance (CFG). Our innovative approach transcends the standard modeling of solely data distribution to incorporating the posterior probability of conditions. The proposed technique originates from the idea of CFG and is easy yet effective, making it a plug-and-play module for existing models. Our method significantly accelerates the training process, doubles the inference speed, and achieve exceptional quality that parallel and even surpass concurrent diffusion models with CFG. Extensive experiments demonstrate the effectiveness, efficiency, scalability on different models and datasets. Finally, we establish state-of-the-art performance on ImageNet 256 benchmarks with an FID of 1.34. Our code is available at https://github.com/tzco/Diffusion-wo-CFG.
SmartEraser: Remove Anything from Images using Masked-Region Guidance
Jan 14, 2025



Object removal has so far been dominated by the mask-and-inpaint paradigm, where the masked region is excluded from the input, leaving models relying on unmasked areas to inpaint the missing region. However, this approach lacks contextual information for the masked area, often resulting in unstable performance. In this work, we introduce SmartEraser, built with a new removing paradigm called Masked-Region Guidance. This paradigm retains the masked region in the input, using it as guidance for the removal process. It offers several distinct advantages: (a) it guides the model to accurately identify the object to be removed, preventing its regeneration in the output; (b) since the user mask often extends beyond the object itself, it aids in preserving the surrounding context in the final result. Leveraging this new paradigm, we present Syn4Removal, a large-scale object removal dataset, where instance segmentation data is used to copy and paste objects onto images as removal targets, with the original images serving as ground truths. Experimental results demonstrate that SmartEraser significantly outperforms existing methods, achieving superior performance in object removal, especially in complex scenes with intricate compositions.
MageBench: Bridging Large Multimodal Models to Agents
Dec 05, 2024LMMs have shown impressive visual understanding capabilities, with the potential to be applied in agents, which demand strong reasoning and planning abilities. Nevertheless, existing benchmarks mostly assess their reasoning abilities in language part, where the chain-of-thought is entirely composed of text.We consider the scenario where visual signals are continuously updated and required along the decision making process. Such vision-in-the-chain reasoning paradigm is more aligned with the needs of multimodal agents, while being rarely evaluated. In this paper, we introduce MageBench, a reasoning capability oriented multimodal agent benchmark that, while having light-weight environments, poses significant reasoning challenges and holds substantial practical value. This benchmark currently includes three types of environments: WebUI, Sokoban, and Football, comprising a total of 483 different scenarios. It thoroughly validates the agent's knowledge and engineering capabilities, visual intelligence, and interaction skills. The results show that only a few product-level models are better than random acting, and all of them are far inferior to human-level. More specifically, we found current models severely lack the ability to modify their planning based on visual feedback, as well as visual imagination, interleaved image-text long context handling, and other abilities. We hope that our work will provide optimization directions for LMM from the perspective of being an agent. We release our code and data at https://github.com/microsoft/MageBench.
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
Nov 29, 2024



The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation. Code and models can be found on our project page (https://cogact.github.io/).