 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Pre-trained Diffusion Models in Solving the Schrödinger Bridge Problem
Aug 25, 2025
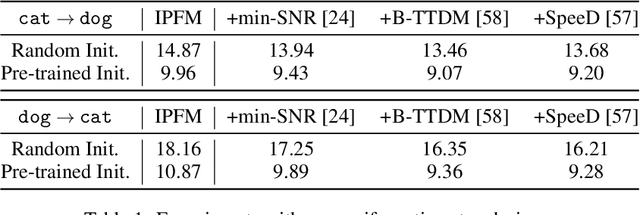

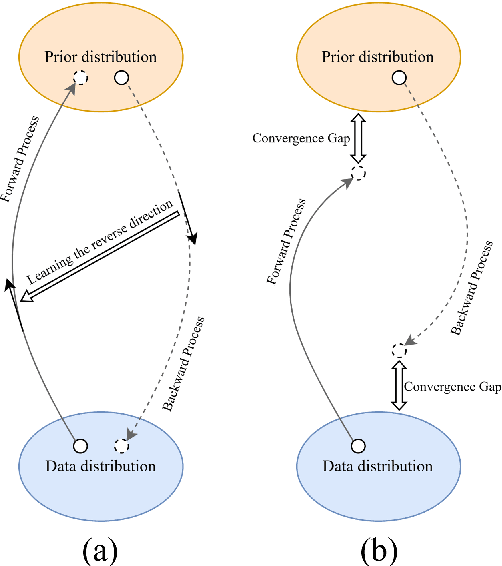
This paper aims to unify Score-based Generative Models (SGMs), also known as Diffusion models, and the Schr\"odinger Bridge (SB) problem through three reparameterization techniques: Iterative Proportional Mean-Matching (IPMM), Iterative Proportional Terminus-Matching (IPTM), and Iterative Proportional Flow-Matching (IPFM). These techniques significantly accelerate and stabilize the training of SB-based models. Furthermore, the paper introduces novel initialization strategies that use pre-trained SGMs to effectively train SB-based models. By using SGMs as initialization, we leverage the advantages of both SB-based models and SGMs, ensuring efficient training of SB-based models and further improving the performance of SGMs. Extensive experiments demonstrate the significant effectiveness and improvements of the proposed methods. We believe this work contributes to and paves the way for future research on generative models.
ART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation
Feb 25, 2025Multi-layer image generation is a fundamental task that enables users to isolate, select, and edit specific image layers, thereby revolutionizing interactions with generative models. In this paper, we introduce the Anonymous Region Transformer (ART), which facilitates the direct generation of variable multi-layer transparent images based on a global text prompt and an anonymous region layout. Inspired by Schema theory suggests that knowledge is organized in frameworks (schemas) that enable people to interpret and learn from new information by linking it to prior knowledge.}, this anonymous region layout allows the generative model to autonomously determine which set of visual tokens should align with which text tokens, which is in contrast to the previously dominant semantic layout for the image generation task. In addition, the layer-wise region crop mechanism, which only selects the visual tokens belonging to each anonymous region, significantly reduces attention computation costs and enables the efficient generation of images with numerous distinct layers (e.g., 50+). When compared to the full attention approach, our method is over 12 times faster and exhibits fewer layer conflicts. Furthermore, we propose a high-quality multi-layer transparent image autoencoder that supports the direct encoding and decoding of the transparency of variable multi-layer images in a joint manner. By enabling precise control and scalable layer generation, ART establishes a new paradigm for interactive content creation.
Diffusion Models without Classifier-free Guidance
Feb 17, 2025This paper presents Model-guidance (MG), a novel objective for training diffusion model that addresses and removes of the commonly used Classifier-free guidance (CFG). Our innovative approach transcends the standard modeling of solely data distribution to incorporating the posterior probability of conditions. The proposed technique originates from the idea of CFG and is easy yet effective, making it a plug-and-play module for existing models. Our method significantly accelerates the training process, doubles the inference speed, and achieve exceptional quality that parallel and even surpass concurrent diffusion models with CFG. Extensive experiments demonstrate the effectiveness, efficiency, scalability on different models and datasets. Finally, we establish state-of-the-art performance on ImageNet 256 benchmarks with an FID of 1.34. Our code is available at https://github.com/tzco/Diffusion-wo-CFG.
Simplified Diffusion Schrödinger Bridge
Mar 27, 2024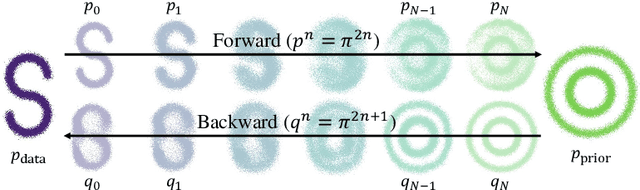


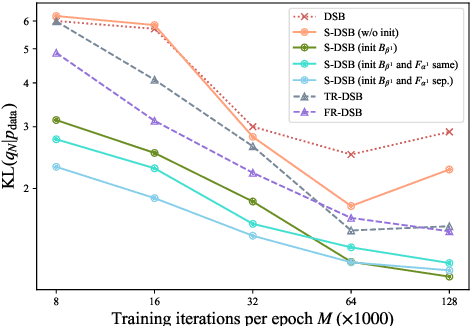
This paper introduces a novel theoretical simplification of the Diffusion Schr\"odinger Bridge (DSB) that facilitates its unification with Score-based Generative Models (SGMs), addressing the limitations of DSB in complex data generation and enabling faster convergence and enhanced performance. By employing SGMs as an initial solution for DSB, our approach capitalizes on the strengths of both frameworks, ensuring a more efficient training process and improving the performance of SGM. We also propose a reparameterization technique that, despite theoretical approximations, practically improves the network's fitting capabilities. Our extensive experimental evaluations confirm the effectiveness of the simplified DSB, demonstrating its significant improvements. We believe the contributions of this work pave the way for advanced generative modeling. The code is available at https://github.com/checkcrab/SDSB.
VolumeDiffusion: Flexible Text-to-3D Generation with Efficient Volumetric Encoder
Dec 18, 2023



This paper introduces a pioneering 3D volumetric encoder designed for text-to-3D generation. To scale up the training data for the diffusion model, a lightweight network is developed to efficiently acquire feature volumes from multi-view images. The 3D volumes are then trained on a diffusion model for text-to-3D generation using a 3D U-Net. This research further addresses the challenges of inaccurate object captions and high-dimensional feature volumes. The proposed model, trained on the public Objaverse dataset, demonstrates promising outcomes in producing diverse and recognizable samples from text prompts. Notably, it empowers finer control over object part characteristics through textual cues, fostering model creativity by seamlessly combining multiple concepts within a single object. This research significantly contributes to the progress of 3D generation by introducing an efficient, flexible, and scalable representation methodology. Code is available at https://github.com/tzco/VolumeDiffusion.
Improved Vector Quantized Diffusion Models
May 31, 2022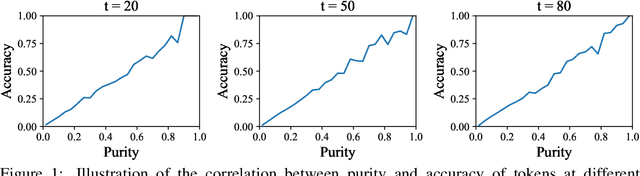
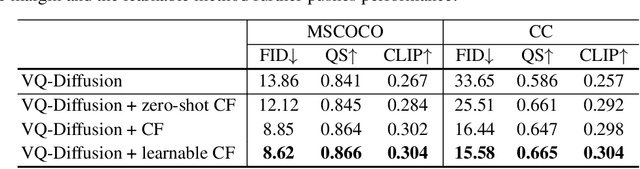
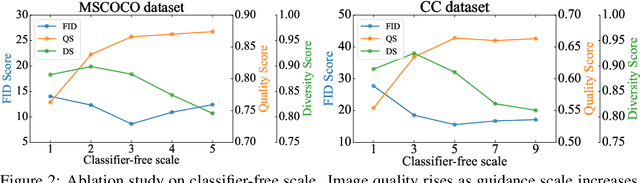
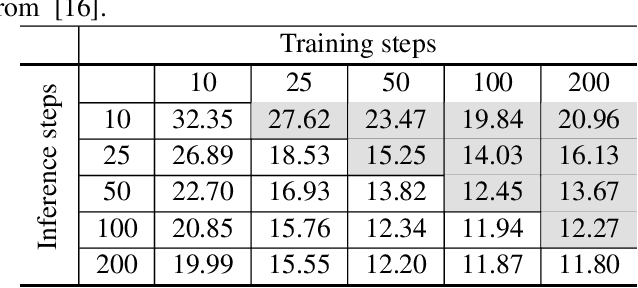
Vector quantized diffusion (VQ-Diffusion) is a powerful generative model for text-to-image synthesis, but sometimes can still generate low-quality samples or weakly correlated images with text input. We find these issues are mainly due to the flawed sampling strategy. In this paper, we propose two important techniques to further improve the sample quality of VQ-Diffusion. 1) We explore classifier-free guidance sampling for discrete denoising diffusion model and propose a more general and effective implementation of classifier-free guidance. 2) We present a high-quality inference strategy to alleviate the joint distribution issue in VQ-Diffusion. Finally, we conduct experiments on various datasets to validate their effectiveness and show that the improved VQ-Diffusion suppresses the vanilla version by large margins. We achieve an 8.44 FID score on MSCOCO, surpassing VQ-Diffusion by 5.42 FID score. When trained on ImageNet, we dramatically improve the FID score from 11.89 to 4.83, demonstrating the superiority of our proposed techniques.