 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Matching Variational AutoEncoder
Dec 08, 2025Most visual generative models compress images into a latent space before applying diffusion or autoregressive modelling. Yet, existing approaches such as VAEs and foundation model aligned encoders implicitly constrain the latent space without explicitly shaping its distribution, making it unclear which types of distributions are optimal for modeling. We introduce \textbf{Distribution-Matching VAE} (\textbf{DMVAE}), which explicitly aligns the encoder's latent distribution with an arbitrary reference distribution via a distribution matching constraint. This generalizes beyond the Gaussian prior of conventional VAEs, enabling alignment with distributions derived from self-supervised features, diffusion noise, or other prior distributions. With DMVAE, we can systematically investigate which latent distributions are more conducive to modeling, and we find that SSL-derived distributions provide an excellent balance between reconstruction fidelity and modeling efficiency, reaching gFID equals 3.2 on ImageNet with only 64 training epochs. Our results suggest that choosing a suitable latent distribution structure (achieved via distribution-level alignment), rather than relying on fixed priors, is key to bridging the gap between easy-to-model latents and high-fidelity image synthesis. Code is avaliable at https://github.com/sen-ye/dmvae.
Incorporating Pre-trained Diffusion Models in Solving the Schrödinger Bridge Problem
Aug 25, 2025
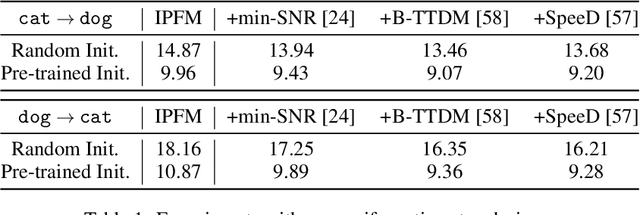

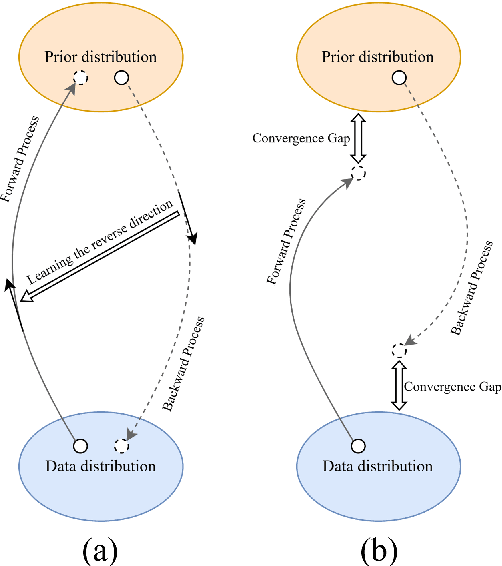
This paper aims to unify Score-based Generative Models (SGMs), also known as Diffusion models, and the Schr\"odinger Bridge (SB) problem through three reparameterization techniques: Iterative Proportional Mean-Matching (IPMM), Iterative Proportional Terminus-Matching (IPTM), and Iterative Proportional Flow-Matching (IPFM). These techniques significantly accelerate and stabilize the training of SB-based models. Furthermore, the paper introduces novel initialization strategies that use pre-trained SGMs to effectively train SB-based models. By using SGMs as initialization, we leverage the advantages of both SB-based models and SGMs, ensuring efficient training of SB-based models and further improving the performance of SGMs. Extensive experiments demonstrate the significant effectiveness and improvements of the proposed methods. We believe this work contributes to and paves the way for future research on generative models.
X-Omni: Reinforcement Learning Makes Discrete Autoregressive Image Generative Models Great Again
Jul 29, 2025Numerous efforts have been made to extend the ``next token prediction'' paradigm to visual contents, aiming to create a unified approach for both image generation and understanding. Nevertheless, attempts to generate images through autoregressive modeling with discrete tokens have been plagued by issues such as low visual fidelity, distorted outputs, and failure to adhere to complex instructions when rendering intricate details. These shortcomings are likely attributed to cumulative errors during autoregressive inference or information loss incurred during the discretization process. Probably due to this challenge, recent research has increasingly shifted toward jointly training image generation with diffusion objectives and language generation with autoregressive objectives, moving away from unified modeling approaches. In this work, we demonstrate that reinforcement learning can effectively mitigate artifacts and largely enhance the generation quality of a discrete autoregressive modeling method, thereby enabling seamless integration of image and language generation. Our framework comprises a semantic image tokenizer, a unified autoregressive model for both language and images, and an offline diffusion decoder for image generation, termed X-Omni. X-Omni achieves state-of-the-art performance in image generation tasks using a 7B language model, producing images with high aesthetic quality while exhibiting strong capabilities in following instructions and rendering long texts.
Optimal Stepsize for Diffusion Sampling
Mar 27, 2025Diffusion models achieve remarkable generation quality but suffer from computational intensive sampling due to suboptimal step discretization. While existing works focus on optimizing denoising directions, we address the principled design of stepsize schedules. This paper proposes Optimal Stepsize Distillation, a dynamic programming framework that extracts theoretically optimal schedules by distilling knowledge from reference trajectories. By reformulating stepsize optimization as recursive error minimization, our method guarantees global discretization bounds through optimal substructure exploitation. Crucially, the distilled schedules demonstrate strong robustness across architectures, ODE solvers, and noise schedules. Experiments show 10x accelerated text-to-image generation while preserving 99.4% performance on GenEval. Our code is available at https://github.com/bebebe666/OptimalSteps.
Equivariant Image Modeling
Mar 24, 2025Current generative models, such as autoregressive and diffusion approaches, decompose high-dimensional data distribution learning into a series of simpler subtasks. However, inherent conflicts arise during the joint optimization of these subtasks, and existing solutions fail to resolve such conflicts without sacrificing efficiency or scalability. We propose a novel equivariant image modeling framework that inherently aligns optimization targets across subtasks by leveraging the translation invariance of natural visual signals. Our method introduces (1) column-wise tokenization which enhances translational symmetry along the horizontal axis, and (2) windowed causal attention which enforces consistent contextual relationships across positions. Evaluated on class-conditioned ImageNet generation at 256x256 resolution, our approach achieves performance comparable to state-of-the-art AR models while using fewer computational resources. Systematic analysis demonstrates that enhanced equivariance reduces inter-task conflicts, significantly improving zero-shot generalization and enabling ultra-long image synthesis. This work establishes the first framework for task-aligned decomposition in generative modeling, offering insights into efficient parameter sharing and conflict-free optimization. The code and models are publicly available at https://github.com/drx-code/EquivariantModeling.
Tokenize Image as a Set
Mar 20, 2025This paper proposes a fundamentally new paradigm for image generation through set-based tokenization and distribution modeling. Unlike conventional methods that serialize images into fixed-position latent codes with a uniform compression ratio, we introduce an unordered token set representation to dynamically allocate coding capacity based on regional semantic complexity. This TokenSet enhances global context aggregation and improves robustness against local perturbations. To address the critical challenge of modeling discrete sets, we devise a dual transformation mechanism that bijectively converts sets into fixed-length integer sequences with summation constraints. Further, we propose Fixed-Sum Discrete Diffusion--the first framework to simultaneously handle discrete values, fixed sequence length, and summation invariance--enabling effective set distribution modeling. Experiments demonstrate our method's superiority in semantic-aware representation and generation quality. Our innovations, spanning novel representation and modeling strategies, advance visual generation beyond traditional sequential token paradigms. Our code and models are publicly available at https://github.com/Gengzigang/TokenSet.
DesignDiffusion: High-Quality Text-to-Design Image Generation with Diffusion Models
Mar 03, 2025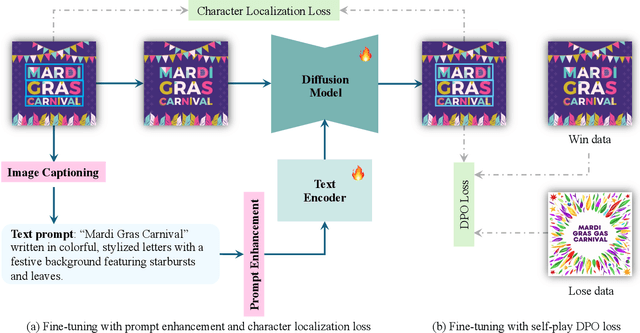



In this paper, we present DesignDiffusion, a simple yet effective framework for the novel task of synthesizing design images from textual descriptions. A primary challenge lies in generating accurate and style-consistent textual and visual content. Existing works in a related task of visual text generation often focus on generating text within given specific regions, which limits the creativity of generation models, resulting in style or color inconsistencies between textual and visual elements if applied to design image generation. To address this issue, we propose an end-to-end, one-stage diffusion-based framework that avoids intricate components like position and layout modeling. Specifically, the proposed framework directly synthesizes textual and visual design elements from user prompts. It utilizes a distinctive character embedding derived from the visual text to enhance the input prompt, along with a character localization loss for enhanced supervision during text generation. Furthermore, we employ a self-play Direct Preference Optimization fine-tuning strategy to improve the quality and accuracy of the synthesized visual text. Extensive experiments demonstrate that DesignDiffusion achieves state-of-the-art performance in design image generation.
Improved Noise Schedule for Diffusion Training
Jul 03, 2024Diffusion models have emerged as the de facto choice for generating visual signals. However, training a single model to predict noise across various levels poses significant challenges, necessitating numerous iterations and incurring significant computational costs. Various approaches, such as loss weighting strategy design and architectural refinements, have been introduced to expedite convergence. In this study, we propose a novel approach to design the noise schedule for enhancing the training of diffusion models. Our key insight is that the importance sampling of the logarithm of the Signal-to-Noise ratio (logSNR), theoretically equivalent to a modified noise schedule, is particularly beneficial for training efficiency when increasing the sample frequency around $\log \text{SNR}=0$. We empirically demonstrate the superiority of our noise schedule over the standard cosine schedule. Furthermore, we highlight the advantages of our noise schedule design on the ImageNet benchmark, showing that the designed schedule consistently benefits different prediction targets.
FontStudio: Shape-Adaptive Diffusion Model for Coherent and Consistent Font Effect Generation
Jun 12, 2024



Recently, the application of modern diffusion-based text-to-image generation models for creating artistic fonts, traditionally the domain of professional designers, has garnered significant interest. Diverging from the majority of existing studies that concentrate on generating artistic typography, our research aims to tackle a novel and more demanding challenge: the generation of text effects for multilingual fonts. This task essentially requires generating coherent and consistent visual content within the confines of a font-shaped canvas, as opposed to a traditional rectangular canvas. To address this task, we introduce a novel shape-adaptive diffusion model capable of interpreting the given shape and strategically planning pixel distributions within the irregular canvas. To achieve this, we curate a high-quality shape-adaptive image-text dataset and incorporate the segmentation mask as a visual condition to steer the image generation process within the irregular-canvas. This approach enables the traditionally rectangle canvas-based diffusion model to produce the desired concepts in accordance with the provided geometric shapes. Second, to maintain consistency across multiple letters, we also present a training-free, shape-adaptive effect transfer method for transferring textures from a generated reference letter to others. The key insights are building a font effect noise prior and propagating the font effect information in a concatenated latent space. The efficacy of our FontStudio system is confirmed through user preference studies, which show a marked preference (78% win-rates on aesthetics) for our system even when compared to the latest unrivaled commercial product, Adobe Firefly.
Step-aware Preference Optimization: Aligning Preference with Denoising Performance at Each Step
Jun 06, 2024



Recently, Direct Preference Optimization (DPO) has extended its success from aligning large language models (LLMs) to aligning text-to-image diffusion models with human preferences. Unlike most existing DPO methods that assume all diffusion steps share a consistent preference order with the final generated images, we argue that this assumption neglects step-specific denoising performance and that preference labels should be tailored to each step's contribution. To address this limitation, we propose Step-aware Preference Optimization (SPO), a novel post-training approach that independently evaluates and adjusts the denoising performance at each step, using a step-aware preference model and a step-wise resampler to ensure accurate step-aware supervision. Specifically, at each denoising step, we sample a pool of images, find a suitable win-lose pair, and, most importantly, randomly select a single image from the pool to initialize the next denoising step. This step-wise resampler process ensures the next win-lose image pair comes from the same image, making the win-lose comparison independent of the previous step. To assess the preferences at each step, we train a separate step-aware preference model that can be applied to both noisy and clean images. Our experiments with Stable Diffusion v1.5 and SDXL demonstrate that SPO significantly outperforms the latest Diffusion-DPO in aligning generated images with complex, detailed prompts and enhancing aesthetics, while also achieving more than 20x times faster in training efficiency. Code and model: https://rockeycoss.github.io/spo.github.io/