 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Omni: Reinforcement Learning Makes Discrete Autoregressive Image Generative Models Great Again
Jul 29, 2025Numerous efforts have been made to extend the ``next token prediction'' paradigm to visual contents, aiming to create a unified approach for both image generation and understanding. Nevertheless, attempts to generate images through autoregressive modeling with discrete tokens have been plagued by issues such as low visual fidelity, distorted outputs, and failure to adhere to complex instructions when rendering intricate details. These shortcomings are likely attributed to cumulative errors during autoregressive inference or information loss incurred during the discretization process. Probably due to this challenge, recent research has increasingly shifted toward jointly training image generation with diffusion objectives and language generation with autoregressive objectives, moving away from unified modeling approaches. In this work, we demonstrate that reinforcement learning can effectively mitigate artifacts and largely enhance the generation quality of a discrete autoregressive modeling method, thereby enabling seamless integration of image and language generation. Our framework comprises a semantic image tokenizer, a unified autoregressive model for both language and images, and an offline diffusion decoder for image generation, termed X-Omni. X-Omni achieves state-of-the-art performance in image generation tasks using a 7B language model, producing images with high aesthetic quality while exhibiting strong capabilities in following instructions and rendering long texts.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Equivariant Image Modeling
Mar 24, 2025Current generative models, such as autoregressive and diffusion approaches, decompose high-dimensional data distribution learning into a series of simpler subtasks. However, inherent conflicts arise during the joint optimization of these subtasks, and existing solutions fail to resolve such conflicts without sacrificing efficiency or scalability. We propose a novel equivariant image modeling framework that inherently aligns optimization targets across subtasks by leveraging the translation invariance of natural visual signals. Our method introduces (1) column-wise tokenization which enhances translational symmetry along the horizontal axis, and (2) windowed causal attention which enforces consistent contextual relationships across positions. Evaluated on class-conditioned ImageNet generation at 256x256 resolution, our approach achieves performance comparable to state-of-the-art AR models while using fewer computational resources. Systematic analysis demonstrates that enhanced equivariance reduces inter-task conflicts, significantly improving zero-shot generalization and enabling ultra-long image synthesis. This work establishes the first framework for task-aligned decomposition in generative modeling, offering insights into efficient parameter sharing and conflict-free optimization. The code and models are publicly available at https://github.com/drx-code/EquivariantModeling.
Tokenize Image as a Set
Mar 20, 2025This paper proposes a fundamentally new paradigm for image generation through set-based tokenization and distribution modeling. Unlike conventional methods that serialize images into fixed-position latent codes with a uniform compression ratio, we introduce an unordered token set representation to dynamically allocate coding capacity based on regional semantic complexity. This TokenSet enhances global context aggregation and improves robustness against local perturbations. To address the critical challenge of modeling discrete sets, we devise a dual transformation mechanism that bijectively converts sets into fixed-length integer sequences with summation constraints. Further, we propose Fixed-Sum Discrete Diffusion--the first framework to simultaneously handle discrete values, fixed sequence length, and summation invariance--enabling effective set distribution modeling. Experiments demonstrate our method's superiority in semantic-aware representation and generation quality. Our innovations, spanning novel representation and modeling strategies, advance visual generation beyond traditional sequential token paradigms. Our code and models are publicly available at https://github.com/Gengzigang/TokenSet.
InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
Sep 07, 2023We present InstructDiffusion, a unifying and generic framework for aligning computer vision tasks with human instructions. Unlike existing approaches that integrate prior knowledge and pre-define the output space (e.g., categories and coordinates) for each vision task, we cast diverse vision tasks into a human-intuitive image-manipulating process whose output space is a flexible and interactive pixel space. Concretely, the model is built upon the diffusion process and is trained to predict pixels according to user instructions, such as encircling the man's left shoulder in red or applying a blue mask to the left car. InstructDiffusion could handle a variety of vision tasks, including understanding tasks (such as segmentation and keypoint detection) and generative tasks (such as editing and enhancement). It even exhibits the ability to handle unseen tasks and outperforms prior methods on novel datasets. This represents a significant step towards a generalist modeling interface for vision tasks, advancing artificial general intelligence in the field of computer vision.
V-DETR: DETR with Vertex Relative Position Encoding for 3D Object Detection
Aug 08, 2023



We introduce a highly performant 3D object detector for point clouds using the DETR framework. The prior attempts all end up with suboptimal results because they fail to learn accurate inductive biases from the limited scale of training data. In particular, the queries often attend to points that are far away from the target objects, violating the locality principle in object detection. To address the limitation, we introduce a novel 3D Vertex Relative Position Encoding (3DV-RPE) method which computes position encoding for each point based on its relative position to the 3D boxes predicted by the queries in each decoder layer, thus providing clear information to guide the model to focus on points near the objects, in accordance with the principle of locality. In addition, we systematically improve the pipeline from various aspects such as data normalization based on our understanding of the task. We show exceptional results on the challenging ScanNetV2 benchmark, achieving significant improvements over the previous 3DETR in $\rm{AP}_{25}$/$\rm{AP}_{50}$ from 65.0\%/47.0\% to 77.8\%/66.0\%, respectively. In addition, our method sets a new record on ScanNetV2 and SUN RGB-D datasets.Code will be released at http://github.com/yichaoshen-MS/V-DETR.
Human Pose as Compositional Tokens
Mar 21, 2023


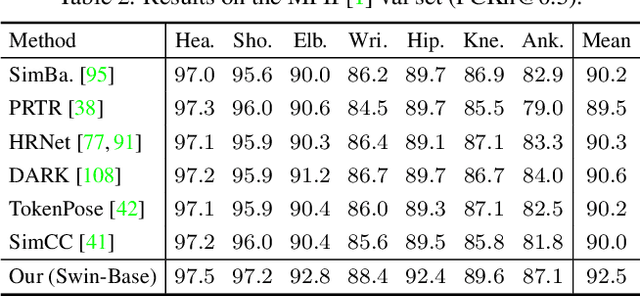
Human pose is typically represented by a coordinate vector of body joints or their heatmap embeddings. While easy for data processing, unrealistic pose estimates are admitted due to the lack of dependency modeling between the body joints. In this paper, we present a structured representation, named Pose as Compositional Tokens (PCT), to explore the joint dependency. It represents a pose by M discrete tokens with each characterizing a sub-structure with several interdependent joints. The compositional design enables it to achieve a small reconstruction error at a low cost. Then we cast pose estimation as a classification task. In particular, we learn a classifier to predict the categories of the M tokens from an image. A pre-learned decoder network is used to recover the pose from the tokens without further post-processing. We show that it achieves better or comparable pose estimation results as the existing methods in general scenarios, yet continues to work well when occlusion occurs, which is ubiquitous in practice. The code and models are publicly available at https://github.com/Gengzigang/PCT.
All in Tokens: Unifying Output Space of Visual Tasks via Soft Token
Jan 05, 2023



Unlike language tasks, where the output space is usually limited to a set of tokens, the output space of visual tasks is more complicated, making it difficult to build a unified visual model for various visual tasks. In this paper, we seek to unify the output space of visual tasks, so that we can also build a unified model for visual tasks. To this end, we demonstrate a single unified model that simultaneously handles two typical visual tasks of instance segmentation and depth estimation, which have discrete/fixed-length and continuous/varied-length outputs, respectively. We propose several new techniques that take into account the particularity of visual tasks: 1) Soft token. We employ soft token to represent the task output. Unlike hard tokens in the common VQ-VAE which are assigned one-hot to discrete codebooks/vocabularies, the soft token is assigned softly to the codebook embeddings. Soft token can improve the accuracy of both the next token inference and decoding of the task output; 2) Mask augmentation. Many visual tasks have corruption, undefined or invalid values in label annotations, i.e., occluded area of depth maps. We show that a mask augmentation technique can greatly benefit these tasks. With these new techniques and other designs, we show that the proposed general-purpose task-solver can perform both instance segmentation and depth estimation well. Particularly, we achieve 0.279 RMSE on the specific task of NYUv2 depth estimation, setting a new record on this benchmark. The general-purpose task-solver, dubbed AiT, is available at \url{https://github.com/SwinTransformer/AiT}.
Revealing the Dark Secrets of Masked Image Modeling
May 27, 2022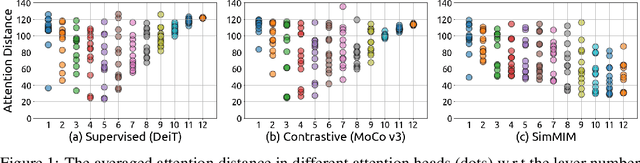

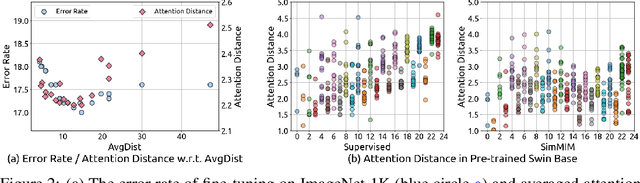
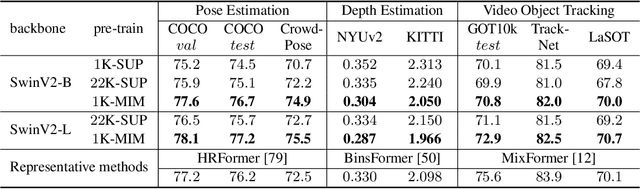
Masked image modeling (MIM) as pre-training is shown to be effective for numerous vision downstream tasks, but how and where MIM works remain unclear. In this paper, we compare MIM with the long-dominant supervised pre-trained models from two perspectives, the visualizations and the experiments, to uncover their key representational differences. From the visualizations, we find that MIM brings locality inductive bias to all layers of the trained models, but supervised models tend to focus locally at lower layers but more globally at higher layers. That may be the reason why MIM helps Vision Transformers that have a very large receptive field to optimize. Using MIM, the model can maintain a large diversity on attention heads in all layers. But for supervised models, the diversity on attention heads almost disappears from the last three layers and less diversity harms the fine-tuning performance. From the experiments, we find that MIM models can perform significantly better on geometric and motion tasks with weak semantics or fine-grained classification tasks, than their supervised counterparts. Without bells and whistles, a standard MIM pre-trained SwinV2-L could achieve state-of-the-art performance on pose estimation (78.9 AP on COCO test-dev and 78.0 AP on CrowdPose), depth estimation (0.287 RMSE on NYUv2 and 1.966 RMSE on KITTI), and video object tracking (70.7 SUC on LaSOT). For the semantic understanding datasets where the categories are sufficiently covered by the supervised pre-training, MIM models can still achieve highly competitive transfer performance. With a deeper understanding of MIM, we hope that our work can inspire new and solid research in this direction.
Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
Apr 06, 2021
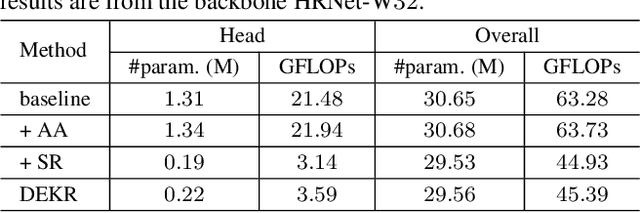


In this paper, we are interested in the bottom-up paradigm of estimating human poses from an image. We study the dense keypoint regression framework that is previously inferior to the keypoint detection and grouping framework. Our motivation is that regressing keypoint positions accurately needs to learn representations that focus on the keypoint regions. We present a simple yet effective approach, named disentangled keypoint regression (DEKR). We adopt adaptive convolutions through pixel-wise spatial transformer to activate the pixels in the keypoint regions and accordingly learn representations from them. We use a multi-branch structure for separate regression: each branch learns a representation with dedicated adaptive convolutions and regresses one keypoint. The resulting disentangled representations are able to attend to the keypoint regions, respectively, and thus the keypoint regression is spatially more accurate. We empirically show that the proposed direct regression method outperforms keypoint detection and grouping methods and achieves superior bottom-up pose estimation results on two benchmark datasets, COCO and CrowdPose. The code and models are available at https://github.com/HRNet/DEKR.