 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
Paper and Code

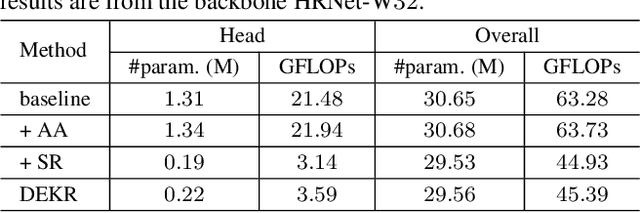


In this paper, we are interested in the bottom-up paradigm of estimating human poses from an image. We study the dense keypoint regression framework that is previously inferior to the keypoint detection and grouping framework. Our motivation is that regressing keypoint positions accurately needs to learn representations that focus on the keypoint regions. We present a simple yet effective approach, named disentangled keypoint regression (DEKR). We adopt adaptive convolutions through pixel-wise spatial transformer to activate the pixels in the keypoint regions and accordingly learn representations from them. We use a multi-branch structure for separate regression: each branch learns a representation with dedicated adaptive convolutions and regresses one keypoint. The resulting disentangled representations are able to attend to the keypoint regions, respectively, and thus the keypoint regression is spatially more accurate. We empirically show that the proposed direct regression method outperforms keypoint detection and grouping methods and achieves superior bottom-up pose estimation results on two benchmark datasets, COCO and CrowdPose. The code and models are available at https://github.com/HRNet/DEKR.