 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
VAE-REPA: Variational Autoencoder Representation Alignment for Efficient Diffusion Training
Jan 25, 2026Denoising-based diffusion transformers, despite their strong generation performance, suffer from inefficient training convergence. Existing methods addressing this issue, such as REPA (relying on external representation encoders) or SRA (requiring dual-model setups), inevitably incur heavy computational overhead during training due to external dependencies. To tackle these challenges, this paper proposes \textbf{\namex}, a lightweight intrinsic guidance framework for efficient diffusion training. \name leverages off-the-shelf pre-trained Variational Autoencoder (VAE) features: their reconstruction property ensures inherent encoding of visual priors like rich texture details, structural patterns, and basic semantic information. Specifically, \name aligns the intermediate latent features of diffusion transformers with VAE features via a lightweight projection layer, supervised by a feature alignment loss. This design accelerates training without extra representation encoders or dual-model maintenance, resulting in a simple yet effective pipeline. Extensive experiments demonstrate that \name improves both generation quality and training convergence speed compared to vanilla diffusion transformers, matches or outperforms state-of-the-art acceleration methods, and incurs merely 4\% extra GFLOPs with zero additional cost for external guidance models.
MixFlow Training: Alleviating Exposure Bias with Slowed Interpolation Mixture
Dec 22, 2025This paper studies the training-testing discrepancy (a.k.a. exposure bias) problem for improving the diffusion models. During training, the input of a prediction network at one training timestep is the corresponding ground-truth noisy data that is an interpolation of the noise and the data, and during testing, the input is the generated noisy data. We present a novel training approach, named MixFlow, for improving the performance. Our approach is motivated by the Slow Flow phenomenon: the ground-truth interpolation that is the nearest to the generated noisy data at a given sampling timestep is observed to correspond to a higher-noise timestep (termed slowed timestep), i.e., the corresponding ground-truth timestep is slower than the sampling timestep. MixFlow leverages the interpolations at the slowed timesteps, named slowed interpolation mixture, for post-training the prediction network for each training timestep. Experiments over class-conditional image generation (including SiT, REPA, and RAE) and text-to-image generation validate the effectiveness of our approach. Our approach MixFlow over the RAE models achieve strong generation results on ImageNet: 1.43 FID (without guidance) and 1.10 (with guidance) at 256 x 256, and 1.55 FID (without guidance) and 1.10 (with guidance) at 512 x 512.
GeoLoom: High-quality Geometric Diagram Generation from Textual Input
Dec 09, 2025High-quality geometric diagram generation presents both a challenge and an opportunity: it demands strict spatial accuracy while offering well-defined constraints to guide generation. Inspired by recent advances in geometry problem solving that employ formal languages and symbolic solvers for enhanced correctness and interpretability, we propose GeoLoom, a novel framework for text-to-diagram generation in geometric domains. GeoLoom comprises two core components: an autoformalization module that translates natural language into a specifically designed generation-oriented formal language GeoLingua, and a coordinate solver that maps formal constraints to precise coordinates using the efficient Monte Carlo optimization. To support this framework, we introduce GeoNF, a dataset aligning natural language geometric descriptions with formal GeoLingua descriptions. We further propose a constraint-based evaluation metric that quantifies structural deviation, offering mathematically grounded supervision for iterative refinement. Empirical results demonstrate that GeoLoom significantly outperforms state-of-the-art baselines in structural fidelity, providing a principled foundation for interpretable and scalable diagram generation.
Query-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025
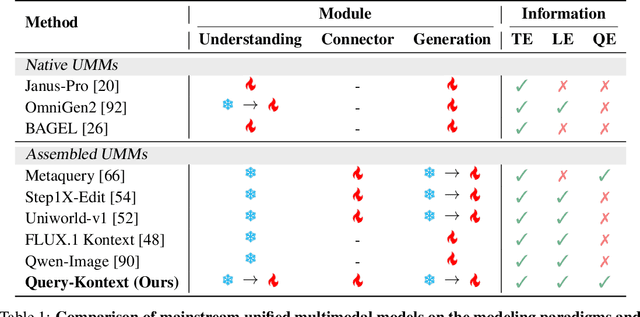
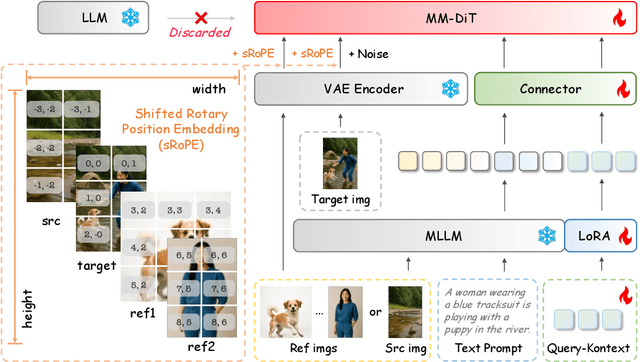
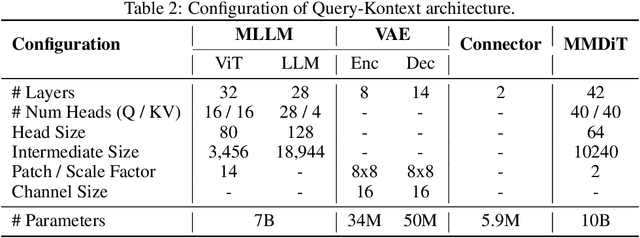
Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
Perception Before Reasoning: Two-Stage Reinforcement Learning for Visual Reasoning in Vision-Language Models
Sep 16, 2025Reinforcement learning (RL) has proven highly effective in eliciting the reasoning capabilities of large language models (LLMs). Inspired by this success, recent studies have explored applying similar techniques to vision-language models (VLMs), aiming to enhance their reasoning performance. However, directly transplanting RL methods from LLMs to VLMs is suboptimal, as the tasks faced by VLMs are inherently more complex. Specifically, VLMs must first accurately perceive and understand visual inputs before reasoning can be effectively performed. To address this challenge, we propose a two-stage reinforcement learning framework designed to jointly enhance both the perceptual and reasoning capabilities of VLMs. To mitigate the vanishing advantage issue commonly observed in RL training, we first perform dataset-level sampling to selectively strengthen specific capabilities using distinct data sources. During training, the first stage focuses on improving the model's visual perception through coarse- and fine-grained visual understanding, while the second stage targets the enhancement of reasoning abilities. After the proposed two-stage reinforcement learning process, we obtain PeBR-R1, a vision-language model with significantly enhanced perceptual and reasoning capabilities. Experimental results on seven benchmark datasets demonstrate the effectiveness of our approach and validate the superior performance of PeBR-R1 across diverse visual reasoning tasks.
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025



In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
iDiT-HOI: Inpainting-based Hand Object Interaction Reenactment via Video Diffusion Transformer
Jun 15, 2025Digital human video generation is gaining traction in fields like education and e-commerce, driven by advancements in head-body animation and lip-syncing technologies. However, realistic Hand-Object Interaction (HOI) - the complex dynamics between human hands and objects - continues to pose challenges. Generating natural and believable HOI reenactments is difficult due to issues such as occlusion between hands and objects, variations in object shapes and orientations, and the necessity for precise physical interactions, and importantly, the ability to generalize to unseen humans and objects. This paper presents a novel framework iDiT-HOI that enables in-the-wild HOI reenactment generation. Specifically, we propose a unified inpainting-based token process method, called Inp-TPU, with a two-stage video diffusion transformer (DiT) model. The first stage generates a key frame by inserting the designated object into the hand region, providing a reference for subsequent frames. The second stage ensures temporal coherence and fluidity in hand-object interactions. The key contribution of our method is to reuse the pretrained model's context perception capabilities without introducing additional parameters, enabling strong generalization to unseen objects and scenarios, and our proposed paradigm naturally supports long video generation. Comprehensive evaluations demonstrate that our approach outperforms existing methods, particularly in challenging real-world scenes, offering enhanced realism and more seamless hand-object interactions.
VoxelSplat: Dynamic Gaussian Splatting as an Effective Loss for Occupancy and Flow Prediction
Jun 05, 2025Recent advancements in camera-based occupancy prediction have focused on the simultaneous prediction of 3D semantics and scene flow, a task that presents significant challenges due to specific difficulties, e.g., occlusions and unbalanced dynamic environments. In this paper, we analyze these challenges and their underlying causes. To address them, we propose a novel regularization framework called VoxelSplat. This framework leverages recent developments in 3D Gaussian Splatting to enhance model performance in two key ways: (i) Enhanced Semantics Supervision through 2D Projection: During training, our method decodes sparse semantic 3D Gaussians from 3D representations and projects them onto the 2D camera view. This provides additional supervision signals in the camera-visible space, allowing 2D labels to improve the learning of 3D semantics. (ii) Scene Flow Learning: Our framework uses the predicted scene flow to model the motion of Gaussians, and is thus able to learn the scene flow of moving objects in a self-supervised manner using the labels of adjacent frames. Our method can be seamlessly integrated into various existing occupancy models, enhancing performance without increasing inference time. Extensive experiments on benchmark datasets demonstrate the effectiveness of VoxelSplat in improving the accuracy of both semantic occupancy and scene flow estimation. The project page and codes are available at https://zzy816.github.io/VoxelSplat-Demo/.
Vision Remember: Alleviating Visual Forgetting in Efficient MLLM with Vision Feature Resample
Jun 04, 2025In this work, we study the Efficient Multimodal Large Language Model. Redundant vision tokens consume a significant amount of computational memory and resources. Therefore, many previous works compress them in the Vision Projector to reduce the number of vision tokens. However, simply compressing in the Vision Projector can lead to the loss of visual information, especially for tasks that rely on fine-grained spatial relationships, such as OCR and Chart \& Table Understanding. To address this problem, we propose Vision Remember, which is inserted between the LLM decoder layers to allow vision tokens to re-memorize vision features. Specifically, we retain multi-level vision features and resample them with the vision tokens that have interacted with the text token. During the resampling process, each vision token only attends to a local region in vision features, which is referred to as saliency-enhancing local attention. Saliency-enhancing local attention not only improves computational efficiency but also captures more fine-grained contextual information and spatial relationships within the region. Comprehensive experiments on multiple visual understanding benchmarks validate the effectiveness of our method when combined with various Efficient Vision Projectors, showing performance gains without sacrificing efficiency. Based on Vision Remember, LLaVA-VR with only 2B parameters is also superior to previous representative MLLMs such as Tokenpacker-HD-7B and DeepSeek-VL-7B.