 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViBES: A Conversational Agent with Behaviorally-Intelligent 3D Virtual Body
Dec 16, 2025



Human communication is inherently multimodal and social: words, prosody, and body language jointly carry intent. Yet most prior systems model human behavior as a translation task co-speech gesture or text-to-motion that maps a fixed utterance to motion clips-without requiring agentic decision-making about when to move, what to do, or how to adapt across multi-turn dialogue. This leads to brittle timing, weak social grounding, and fragmented stacks where speech, text, and motion are trained or inferred in isolation. We introduce ViBES (Voice in Behavioral Expression and Synchrony), a conversational 3D agent that jointly plans language and movement and executes dialogue-conditioned body actions. Concretely, ViBES is a speech-language-behavior (SLB) model with a mixture-of-modality-experts (MoME) backbone: modality-partitioned transformer experts for speech, facial expression, and body motion. The model processes interleaved multimodal token streams with hard routing by modality (parameters are split per expert), while sharing information through cross-expert attention. By leveraging strong pretrained speech-language models, the agent supports mixed-initiative interaction: users can speak, type, or issue body-action directives mid-conversation, and the system exposes controllable behavior hooks for streaming responses. We further benchmark on multi-turn conversation with automatic metrics of dialogue-motion alignment and behavior quality, and observe consistent gains over strong co-speech and text-to-motion baselines. ViBES goes beyond "speech-conditioned motion generation" toward agentic virtual bodies where language, prosody, and movement are jointly generated, enabling controllable, socially competent 3D interaction. Code and data will be made available at: ai.stanford.edu/~juze/ViBES/
SocialGen: Modeling Multi-Human Social Interaction with Language Models
Mar 28, 2025Human interactions in everyday life are inherently social, involving engagements with diverse individuals across various contexts. Modeling these social interactions is fundamental to a wide range of real-world applications. In this paper, we introduce SocialGen, the first unified motion-language model capable of modeling interaction behaviors among varying numbers of individuals, to address this crucial yet challenging problem. Unlike prior methods that are limited to two-person interactions, we propose a novel social motion representation that supports tokenizing the motions of an arbitrary number of individuals and aligning them with the language space. This alignment enables the model to leverage rich, pretrained linguistic knowledge to better understand and reason about human social behaviors. To tackle the challenges of data scarcity, we curate a comprehensive multi-human interaction dataset, SocialX, enriched with textual annotations. Leveraging this dataset, we establish the first comprehensive benchmark for multi-human interaction tasks. Our method achieves state-of-the-art performance across motion-language tasks, setting a new standard for multi-human interaction modeling.
MagicGeo: Training-Free Text-Guided Geometric Diagram Generation
Feb 19, 2025Geometric diagrams are critical in conveying mathematical and scientific concepts, yet traditional diagram generation methods are often manual and resource-intensive. While text-to-image generation has made strides in photorealistic imagery, creating accurate geometric diagrams remains a challenge due to the need for precise spatial relationships and the scarcity of geometry-specific datasets. This paper presents MagicGeo, a training-free framework for generating geometric diagrams from textual descriptions. MagicGeo formulates the diagram generation process as a coordinate optimization problem, ensuring geometric correctness through a formal language solver, and then employs coordinate-aware generation. The framework leverages the strong language translation capability of large language models, while formal mathematical solving ensures geometric correctness. We further introduce MagicGeoBench, a benchmark dataset of 220 geometric diagram descriptions, and demonstrate that MagicGeo outperforms current methods in both qualitative and quantitative evaluations. This work provides a scalable, accurate solution for automated diagram generation, with significant implications for educational and academic applications.
DOTA-ME-CS: Daily Oriented Text Audio-Mandarin English-Code Switching Dataset
Jan 21, 2025



Code-switching, the alternation between two or more languages within communication, poses great challenges for Automatic Speech Recognition (ASR) systems. Existing models and datasets are limited in their ability to effectively handle these challenges. To address this gap and foster progress in code-switching ASR research, we introduce the DOTA-ME-CS: Daily oriented text audio Mandarin-English code-switching dataset, which consists of 18.54 hours of audio data, including 9,300 recordings from 34 participants. To enhance the dataset's diversity, we apply artificial intelligence (AI) techniques such as AI timbre synthesis, speed variation, and noise addition, thereby increasing the complexity and scalability of the task. The dataset is carefully curated to ensure both diversity and quality, providing a robust resource for researchers addressing the intricacies of bilingual speech recognition with detailed data analysis. We further demonstrate the dataset's potential in future research. The DOTA-ME-CS dataset, along with accompanying code, will be made publicly available.
End-to-end Generative Spatial-Temporal Ultrasonic Odometry and Mapping Framework
Dec 23, 2024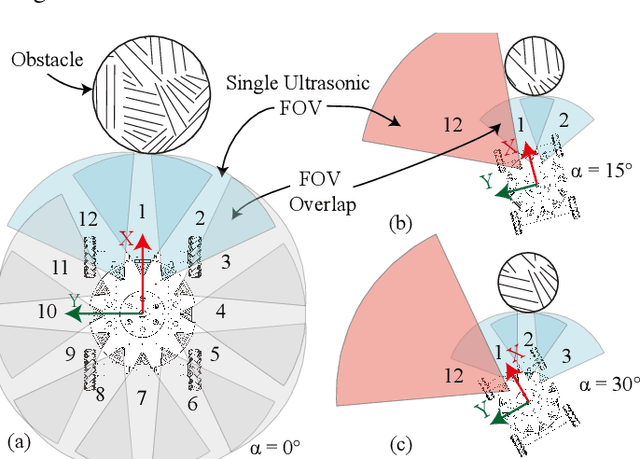
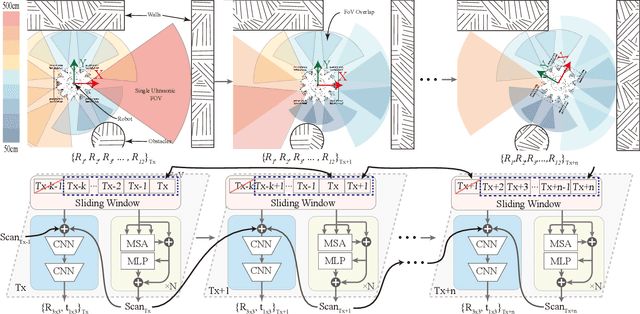
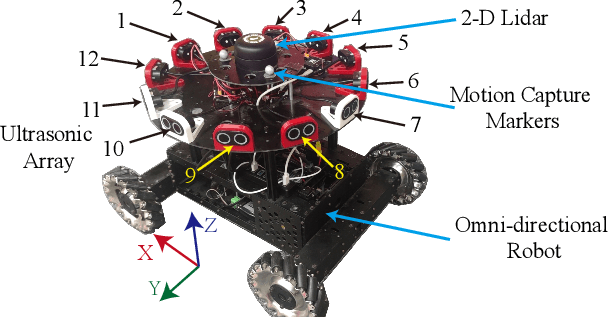

Performing simultaneous localization and mapping (SLAM) in low-visibility conditions, such as environments filled with smoke, dust and transparent objets, has long been a challenging task. Sensors like cameras and Light Detection and Ranging (LiDAR) are significantly limited under these conditions, whereas ultrasonic sensors offer a more robust alternative. However, the low angular resolution, slow update frequency, and limited detection accuracy of ultrasonic sensors present barriers for SLAM. In this work, we propose a novel end-to-end generative ultrasonic SLAM framework. This framework employs a sensor array with overlapping fields of view, leveraging the inherently low angular resolution of ultrasonic sensors to implicitly encode spatial features in conjunction with the robot's motion. Consecutive time frame data is processed through a sliding window mechanism to capture temporal features. The spatiotemporally encoded sensor data is passed through multiple modules to generate dense scan point clouds and robot pose transformations for map construction and odometry. The main contributions of this work include a novel ultrasonic sensor array that spatiotemporally encodes the surrounding environment, and an end-to-end generative SLAM framework that overcomes the inherent defects of ultrasonic sensors. Several real-world experiments demonstrate the feasibility and robustness of the proposed framework.
4Real: Towards Photorealistic 4D Scene Generation via Video Diffusion Models
Jun 11, 2024



Existing dynamic scene generation methods mostly rely on distilling knowledge from pre-trained 3D generative models, which are typically fine-tuned on synthetic object datasets. As a result, the generated scenes are often object-centric and lack photorealism. To address these limitations, we introduce a novel pipeline designed for photorealistic text-to-4D scene generation, discarding the dependency on multi-view generative models and instead fully utilizing video generative models trained on diverse real-world datasets. Our method begins by generating a reference video using the video generation model. We then learn the canonical 3D representation of the video using a freeze-time video, delicately generated from the reference video. To handle inconsistencies in the freeze-time video, we jointly learn a per-frame deformation to model these imperfections. We then learn the temporal deformation based on the canonical representation to capture dynamic interactions in the reference video. The pipeline facilitates the generation of dynamic scenes with enhanced photorealism and structural integrity, viewable from multiple perspectives, thereby setting a new standard in 4D scene generation.
WeightedPose: Generalizable Cross-Pose Estimation via Weighted SVD
May 03, 2024


We present a novel method for robotic manipulation tasks in human environments that require reasoning about the 3D geometric relationship between a pair of objects. Traditional end-to-end trained policies, which map from pixel observations to low-level robot actions, struggle to reason about complex pose relationships and have difficulty generalizing to unseen object configurations. To address these challenges, we propose a method that learns to reason about the 3D geometric relationship between objects, focusing on the relationship between key parts on one object with respect to key parts on another object. Our standalone model utilizes Weighted SVD to reason about both pose relationships between articulated parts and between free-floating objects. This approach allows the robot to understand the relationship between the oven door and the oven body, as well as the relationship between the lasagna plate and the oven, for example. By considering the 3D geometric relationship between objects, our method enables robots to perform complex manipulation tasks that reason about object-centric representations. We open source the code and demonstrate the results here
CoGS: Controllable Gaussian Splatting
Dec 09, 2023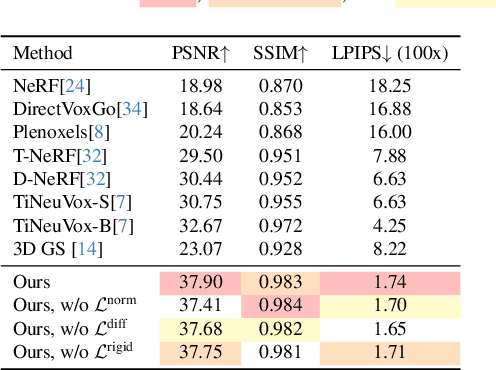
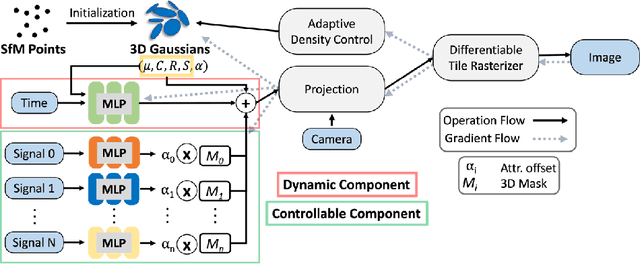
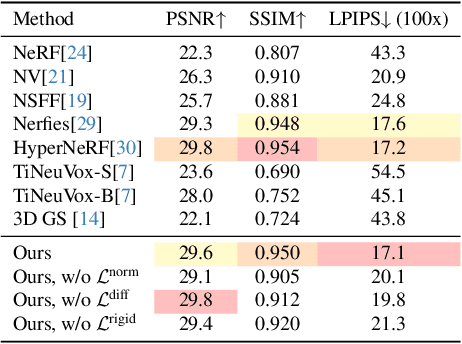
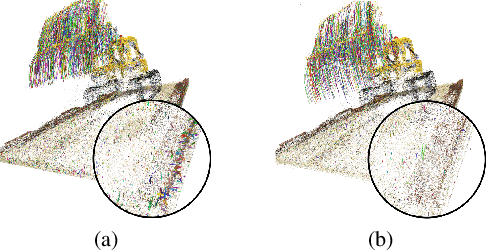
Capturing and re-animating the 3D structure of articulated objects present significant barriers. On one hand, methods requiring extensively calibrated multi-view setups are prohibitively complex and resource-intensive, limiting their practical applicability. On the other hand, while single-camera Neural Radiance Fields (NeRFs) offer a more streamlined approach, they have excessive training and rendering costs. 3D Gaussian Splatting would be a suitable alternative but for two reasons. Firstly, existing methods for 3D dynamic Gaussians require synchronized multi-view cameras, and secondly, the lack of controllability in dynamic scenarios. We present CoGS, a method for Controllable Gaussian Splatting, that enables the direct manipulation of scene elements, offering real-time control of dynamic scenes without the prerequisite of pre-computing control signals. We evaluated CoGS using both synthetic and real-world datasets that include dynamic objects that differ in degree of difficulty. In our evaluations, CoGS consistently outperformed existing dynamic and controllable neural representations in terms of visual fidelity.
SubZero: Subspace Zero-Shot MRI Reconstruction
Nov 28, 2023Recently introduced zero-shot self-supervised learning (ZS-SSL) has shown potential in accelerated MRI in a scan-specific scenario, which enabled high-quality reconstructions without access to a large training dataset. ZS-SSL has been further combined with the subspace model to accelerate 2D T2-shuffling acquisitions. In this work, we propose a parallel network framework and introduce an attention mechanism to improve subspace-based zero-shot self-supervised learning and enable higher acceleration factors. We name our method SubZero and demonstrate that it can achieve improved performance compared with current methods in T1 and T2 mapping acquisitions.
Instruct2Attack: Language-Guided Semantic Adversarial Attacks
Nov 27, 2023We propose Instruct2Attack (I2A), a language-guided semantic attack that generates semantically meaningful perturbations according to free-form language instructions. We make use of state-of-the-art latent diffusion models, where we adversarially guide the reverse diffusion process to search for an adversarial latent code conditioned on the input image and text instruction. Compared to existing noise-based and semantic attacks, I2A generates more natural and diverse adversarial examples while providing better controllability and interpretability. We further automate the attack process with GPT-4 to generate diverse image-specific text instructions. We show that I2A can successfully break state-of-the-art deep neural networks even under strong adversarial defenses, and demonstrate great transferability among a variety of network architectures.