 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Physical Understanding in Video Generation: A 3D Point Regularization Approach
Feb 05, 2025We present a novel video generation framework that integrates 3-dimensional geometry and dynamic awareness. To achieve this, we augment 2D videos with 3D point trajectories and align them in pixel space. The resulting 3D-aware video dataset, PointVid, is then used to fine-tune a latent diffusion model, enabling it to track 2D objects with 3D Cartesian coordinates. Building on this, we regularize the shape and motion of objects in the video to eliminate undesired artifacts, \eg, nonphysical deformation. Consequently, we enhance the quality of generated RGB videos and alleviate common issues like object morphing, which are prevalent in current video models due to a lack of shape awareness. With our 3D augmentation and regularization, our model is capable of handling contact-rich scenarios such as task-oriented videos. These videos involve complex interactions of solids, where 3D information is essential for perceiving deformation and contact. Furthermore, our model improves the overall quality of video generation by promoting the 3D consistency of moving objects and reducing abrupt changes in shape and motion.
Wonderland: Navigating 3D Scenes from a Single Image
Dec 16, 2024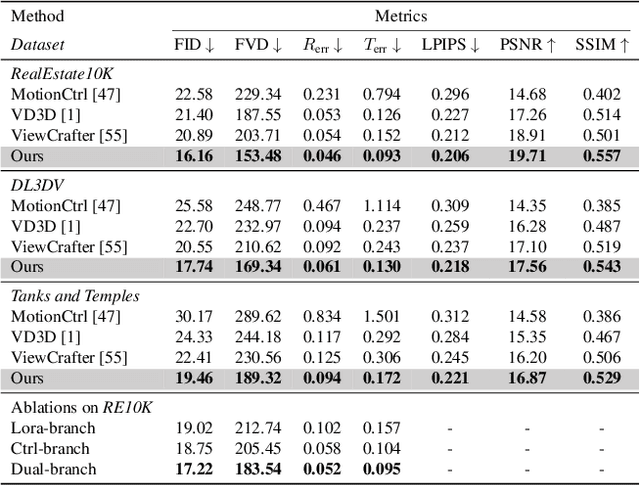
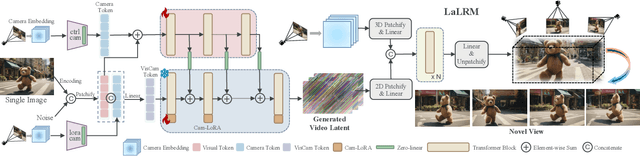
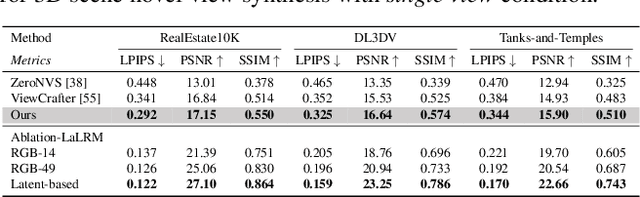

This paper addresses a challenging question: How can we efficiently create high-quality, wide-scope 3D scenes from a single arbitrary image? Existing methods face several constraints, such as requiring multi-view data, time-consuming per-scene optimization, low visual quality in backgrounds, and distorted reconstructions in unseen areas. We propose a novel pipeline to overcome these limitations. Specifically, we introduce a large-scale reconstruction model that uses latents from a video diffusion model to predict 3D Gaussian Splattings for the scenes in a feed-forward manner. The video diffusion model is designed to create videos precisely following specified camera trajectories, allowing it to generate compressed video latents that contain multi-view information while maintaining 3D consistency. We train the 3D reconstruction model to operate on the video latent space with a progressive training strategy, enabling the efficient generation of high-quality, wide-scope, and generic 3D scenes. Extensive evaluations across various datasets demonstrate that our model significantly outperforms existing methods for single-view 3D scene generation, particularly with out-of-domain images. For the first time, we demonstrate that a 3D reconstruction model can be effectively built upon the latent space of a diffusion model to realize efficient 3D scene generation.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
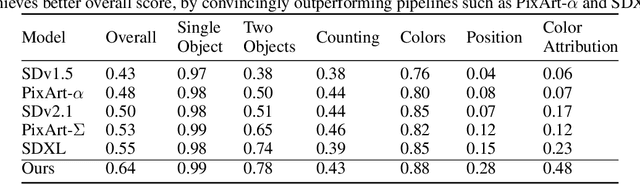
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
AsCAN: Asymmetric Convolution-Attention Networks for Efficient Recognition and Generation
Nov 07, 2024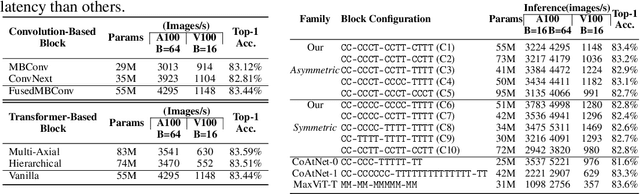
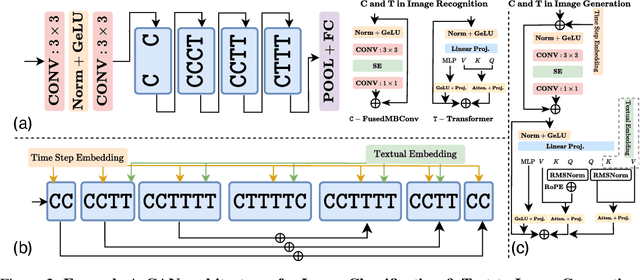
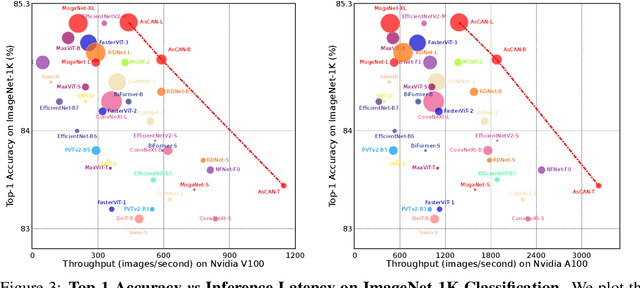
Neural network architecture design requires making many crucial decisions. The common desiderata is that similar decisions, with little modifications, can be reused in a variety of tasks and applications. To satisfy that, architectures must provide promising latency and performance trade-offs, support a variety of tasks, scale efficiently with respect to the amounts of data and compute, leverage available data from other tasks, and efficiently support various hardware. To this end, we introduce AsCAN -- a hybrid architecture, combining both convolutional and transformer blocks. We revisit the key design principles of hybrid architectures and propose a simple and effective \emph{asymmetric} architecture, where the distribution of convolutional and transformer blocks is \emph{asymmetric}, containing more convolutional blocks in the earlier stages, followed by more transformer blocks in later stages. AsCAN supports a variety of tasks: recognition, segmentation, class-conditional image generation, and features a superior trade-off between performance and latency. We then scale the same architecture to solve a large-scale text-to-image task and show state-of-the-art performance compared to the most recent public and commercial models. Notably, even without any computation optimization for transformer blocks, our models still yield faster inference speed than existing works featuring efficient attention mechanisms, highlighting the advantages and the value of our approach.
ControlMM: Controllable Masked Motion Generation
Oct 14, 2024Recent advances in motion diffusion models have enabled spatially controllable text-to-motion generation. However, despite achieving acceptable control precision, these models suffer from generation speed and fidelity limitations. To address these challenges, we propose ControlMM, a novel approach incorporating spatial control signals into the generative masked motion model. ControlMM achieves real-time, high-fidelity, and high-precision controllable motion generation simultaneously. Our approach introduces two key innovations. First, we propose masked consistency modeling, which ensures high-fidelity motion generation via random masking and reconstruction, while minimizing the inconsistency between the input control signals and the extracted control signals from the generated motion. To further enhance control precision, we introduce inference-time logit editing, which manipulates the predicted conditional motion distribution so that the generated motion, sampled from the adjusted distribution, closely adheres to the input control signals. During inference, ControlMM enables parallel and iterative decoding of multiple motion tokens, allowing for high-speed motion generation. Extensive experiments show that, compared to the state of the art, ControlMM delivers superior results in motion quality, with better FID scores (0.061 vs 0.271), and higher control precision (average error 0.0091 vs 0.0108). ControlMM generates motions 20 times faster than diffusion-based methods. Additionally, ControlMM unlocks diverse applications such as any joint any frame control, body part timeline control, and obstacle avoidance. Video visualization can be found at https://exitudio.github.io/ControlMM-page
Lightweight Predictive 3D Gaussian Splats
Jun 27, 2024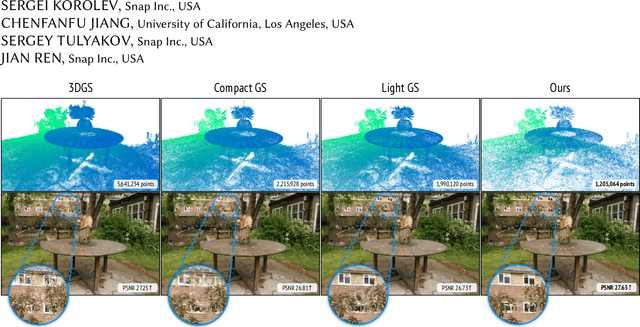
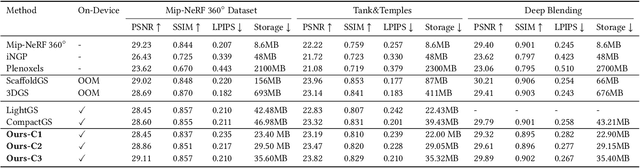
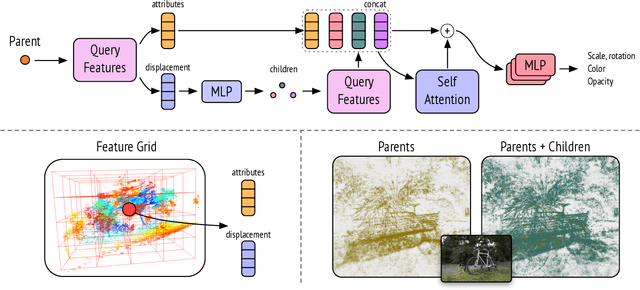

Recent approaches representing 3D objects and scenes using Gaussian splats show increased rendering speed across a variety of platforms and devices. While rendering such representations is indeed extremely efficient, storing and transmitting them is often prohibitively expensive. To represent large-scale scenes, one often needs to store millions of 3D Gaussians, occupying gigabytes of disk space. This poses a very practical limitation, prohibiting widespread adoption.Several solutions have been proposed to strike a balance between disk size and rendering quality, noticeably reducing the visual quality. In this work, we propose a new representation that dramatically reduces the hard drive footprint while featuring similar or improved quality when compared to the standard 3D Gaussian splats. When compared to other compact solutions, ours offers higher quality renderings with significantly reduced storage, being able to efficiently run on a mobile device in real-time. Our key observation is that nearby points in the scene can share similar representations. Hence, only a small ratio of 3D points needs to be stored. We introduce an approach to identify such points which are called parent points. The discarded points called children points along with attributes can be efficiently predicted by tiny MLPs.
4Real: Towards Photorealistic 4D Scene Generation via Video Diffusion Models
Jun 11, 2024



Existing dynamic scene generation methods mostly rely on distilling knowledge from pre-trained 3D generative models, which are typically fine-tuned on synthetic object datasets. As a result, the generated scenes are often object-centric and lack photorealism. To address these limitations, we introduce a novel pipeline designed for photorealistic text-to-4D scene generation, discarding the dependency on multi-view generative models and instead fully utilizing video generative models trained on diverse real-world datasets. Our method begins by generating a reference video using the video generation model. We then learn the canonical 3D representation of the video using a freeze-time video, delicately generated from the reference video. To handle inconsistencies in the freeze-time video, we jointly learn a per-frame deformation to model these imperfections. We then learn the temporal deformation based on the canonical representation to capture dynamic interactions in the reference video. The pipeline facilitates the generation of dynamic scenes with enhanced photorealism and structural integrity, viewable from multiple perspectives, thereby setting a new standard in 4D scene generation.
SF-V: Single Forward Video Generation Model
Jun 06, 2024Diffusion-based video generation models have demonstrated remarkable success in obtaining high-fidelity videos through the iterative denoising process. However, these models require multiple denoising steps during sampling, resulting in high computational costs. In this work, we propose a novel approach to obtain single-step video generation models by leveraging adversarial training to fine-tune pre-trained video diffusion models. We show that, through the adversarial training, the multi-steps video diffusion model, i.e., Stable Video Diffusion (SVD), can be trained to perform single forward pass to synthesize high-quality videos, capturing both temporal and spatial dependencies in the video data. Extensive experiments demonstrate that our method achieves competitive generation quality of synthesized videos with significantly reduced computational overhead for the denoising process (i.e., around $23\times$ speedup compared with SVD and $6\times$ speedup compared with existing works, with even better generation quality), paving the way for real-time video synthesis and editing. More visualization results are made publicly available at https://snap-research.github.io/SF-V.
BitsFusion: 1.99 bits Weight Quantization of Diffusion Model
Jun 06, 2024
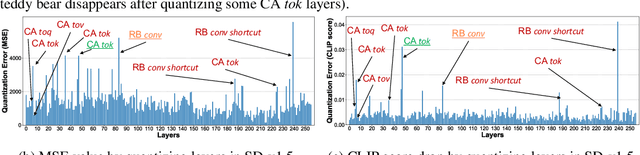
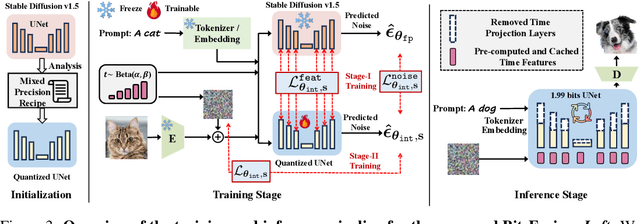
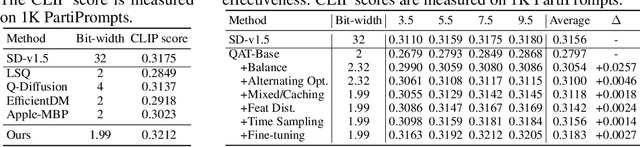
Diffusion-based image generation models have achieved great success in recent years by showing the capability of synthesizing high-quality content. However, these models contain a huge number of parameters, resulting in a significantly large model size. Saving and transferring them is a major bottleneck for various applications, especially those running on resource-constrained devices. In this work, we develop a novel weight quantization method that quantizes the UNet from Stable Diffusion v1.5 to 1.99 bits, achieving a model with 7.9X smaller size while exhibiting even better generation quality than the original one. Our approach includes several novel techniques, such as assigning optimal bits to each layer, initializing the quantized model for better performance, and improving the training strategy to dramatically reduce quantization error. Furthermore, we extensively evaluate our quantized model across various benchmark datasets and through human evaluation to demonstrate its superior generation quality.
AToM: Amortized Text-to-Mesh using 2D Diffusion
Feb 01, 2024



We introduce Amortized Text-to-Mesh (AToM), a feed-forward text-to-mesh framework optimized across multiple text prompts simultaneously. In contrast to existing text-to-3D methods that often entail time-consuming per-prompt optimization and commonly output representations other than polygonal meshes, AToM directly generates high-quality textured meshes in less than 1 second with around 10 times reduction in the training cost, and generalizes to unseen prompts. Our key idea is a novel triplane-based text-to-mesh architecture with a two-stage amortized optimization strategy that ensures stable training and enables scalability. Through extensive experiments on various prompt benchmarks, AToM significantly outperforms state-of-the-art amortized approaches with over 4 times higher accuracy (in DF415 dataset) and produces more distinguishable and higher-quality 3D outputs. AToM demonstrates strong generalizability, offering finegrained 3D assets for unseen interpolated prompts without further optimization during inference, unlike per-prompt solutions.