 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrafast On-chip Online Learning via Spline Locality in Kolmogorov-Arnold Networks
Feb 02, 2026Ultrafast online learning is essential for high-frequency systems, such as controls for quantum computing and nuclear fusion, where adaptation must occur on sub-microsecond timescales. Meeting these requirements demands low-latency, fixed-precision computation under strict memory constraints, a regime in which conventional Multi-Layer Perceptrons (MLPs) are both inefficient and numerically unstable. We identify key properties of Kolmogorov-Arnold Networks (KANs) that align with these constraints. Specifically, we show that: (i) KAN updates exploiting B-spline locality are sparse, enabling superior on-chip resource scaling, and (ii) KANs are inherently robust to fixed-point quantization. By implementing fixed-point online training on Field-Programmable Gate Arrays (FPGAs), a representative platform for on-chip computation, we demonstrate that KAN-based online learners are significantly more efficient and expressive than MLPs across a range of low-latency and resource-constrained tasks. To our knowledge, this work is the first to demonstrate model-free online learning at sub-microsecond latencies.
SnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices
Jan 13, 2026Recent advances in diffusion transformers (DiTs) have set new standards in image generation, yet remain impractical for on-device deployment due to their high computational and memory costs. In this work, we present an efficient DiT framework tailored for mobile and edge devices that achieves transformer-level generation quality under strict resource constraints. Our design combines three key components. First, we propose a compact DiT architecture with an adaptive global-local sparse attention mechanism that balances global context modeling and local detail preservation. Second, we propose an elastic training framework that jointly optimizes sub-DiTs of varying capacities within a unified supernetwork, allowing a single model to dynamically adjust for efficient inference across different hardware. Finally, we develop Knowledge-Guided Distribution Matching Distillation, a step-distillation pipeline that integrates the DMD objective with knowledge transfer from few-step teacher models, producing high-fidelity and low-latency generation (e.g., 4-step) suitable for real-time on-device use. Together, these contributions enable scalable, efficient, and high-quality diffusion models for deployment on diverse hardware.
KANELÉ: Kolmogorov-Arnold Networks for Efficient LUT-based Evaluation
Dec 14, 2025Low-latency, resource-efficient neural network inference on FPGAs is essential for applications demanding real-time capability and low power. Lookup table (LUT)-based neural networks are a common solution, combining strong representational power with efficient FPGA implementation. In this work, we introduce KANELÉ, a framework that exploits the unique properties of Kolmogorov-Arnold Networks (KANs) for FPGA deployment. Unlike traditional multilayer perceptrons (MLPs), KANs employ learnable one-dimensional splines with fixed domains as edge activations, a structure naturally suited to discretization and efficient LUT mapping. We present the first systematic design flow for implementing KANs on FPGAs, co-optimizing training with quantization and pruning to enable compact, high-throughput, and low-latency KAN architectures. Our results demonstrate up to a 2700x speedup and orders of magnitude resource savings compared to prior KAN-on-FPGA approaches. Moreover, KANELÉ matches or surpasses other LUT-based architectures on widely used benchmarks, particularly for tasks involving symbolic or physical formulas, while balancing resource usage across FPGA hardware. Finally, we showcase the versatility of the framework by extending it to real-time, power-efficient control systems.
Languages are Modalities: Cross-Lingual Alignment via Encoder Injection
Oct 31, 2025Instruction-tuned Large Language Models (LLMs) underperform on low resource, non-Latin scripts due to tokenizer fragmentation and weak cross-lingual coupling. We present LLINK (Latent Language Injection for Non-English Knowledge), a compute efficient language-as-modality method that conditions an instruction-tuned decoder without changing the tokenizer or retraining the decoder. First, we align sentence embeddings from a frozen multilingual encoder to the decoder's latent embedding space at a reserved position via a lightweight contrastive projector. Second, the vector is expanded into K soft slots and trained with minimal adapters so the frozen decoder consumes the signal. LLINK substantially improves bilingual retrieval and achieves 81.3% preference over the base model and 63.6% over direct fine-tuning in LLM-judged Q&A evaluations. We further find that improvements can be attributed to reduced tokenization inflation and a stronger cross lingual alignment, despite the model having residual weaknesses in numeric fidelity. Treating low resource languages as a modality offers a practical path to stronger cross-lingual alignment in lightweight LLMs.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
LightSpeed: Light and Fast Neural Light Fields on Mobile Devices
Oct 26, 2023Real-time novel-view image synthesis on mobile devices is prohibitive due to the limited computational power and storage. Using volumetric rendering methods, such as NeRF and its derivatives, on mobile devices is not suitable due to the high computational cost of volumetric rendering. On the other hand, recent advances in neural light field representations have shown promising real-time view synthesis results on mobile devices. Neural light field methods learn a direct mapping from a ray representation to the pixel color. The current choice of ray representation is either stratified ray sampling or Plucker coordinates, overlooking the classic light slab (two-plane) representation, the preferred representation to interpolate between light field views. In this work, we find that using the light slab representation is an efficient representation for learning a neural light field. More importantly, it is a lower-dimensional ray representation enabling us to learn the 4D ray space using feature grids which are significantly faster to train and render. Although mostly designed for frontal views, we show that the light-slab representation can be further extended to non-frontal scenes using a divide-and-conquer strategy. Our method offers superior rendering quality compared to previous light field methods and achieves a significantly improved trade-off between rendering quality and speed.
* Project Page: http://lightspeed-r2l.github.io/ . Add camera ready version
Structure-Preserving Instance Segmentation via Skeleton-Aware Distance Transform
Oct 08, 2023Objects with complex structures pose significant challenges to existing instance segmentation methods that rely on boundary or affinity maps, which are vulnerable to small errors around contacting pixels that cause noticeable connectivity change. While the distance transform (DT) makes instance interiors and boundaries more distinguishable, it tends to overlook the intra-object connectivity for instances with varying width and result in over-segmentation. To address these challenges, we propose a skeleton-aware distance transform (SDT) that combines the merits of object skeleton in preserving connectivity and DT in modeling geometric arrangement to represent instances with arbitrary structures. Comprehensive experiments on histopathology image segmentation demonstrate that SDT achieves state-of-the-art performance.
Parametric Variational Linear Units (PVLUs) in Deep Convolutional Networks
Nov 02, 2021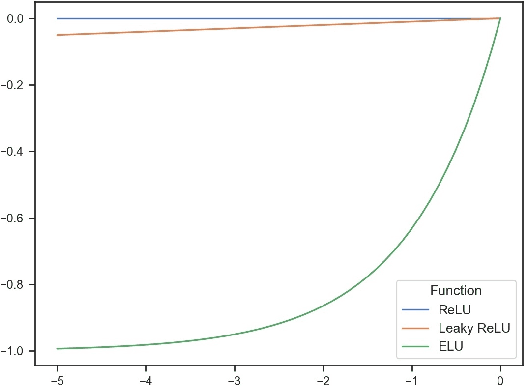
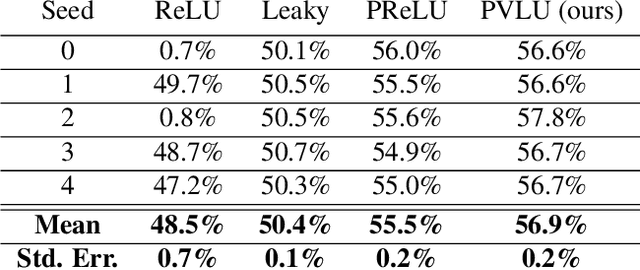
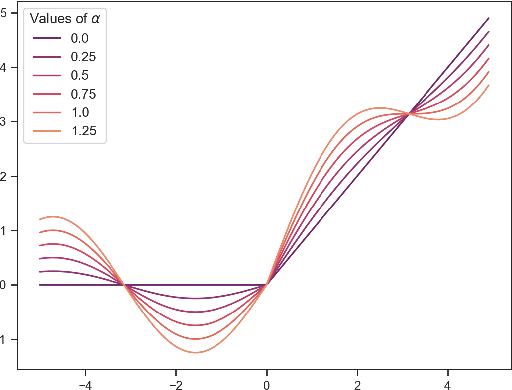

The Rectified Linear Unit is currently a state-of-the-art activation function in deep convolutional neural networks. To combat ReLU's dying neuron problem, we propose the Parametric Variational Linear Unit (PVLU), which adds a sinusoidal function with trainable coefficients to ReLU. Along with introducing nonlinearity and non-zero gradients across the entire real domain, PVLU acts as a mechanism of fine-tuning when implemented in the context of transfer learning. On a simple, non-transfer sequential CNN, PVLU substitution allowed for relative error decreases of 16.3% and 11.3% (without and with data augmentation) on CIFAR-100. PVLU is also tested on transfer learning models. The VGG-16 and VGG-19 models experience relative error reductions of 9.5% and 10.7% on CIFAR-10, respectively, after the substitution of ReLU with PVLU. When training on Gaussian-filtered CIFAR-10 images, similar improvements are noted for the VGG models. Most notably, fine-tuning using PVLU allows for relative error reductions up to and exceeding 10% for near state-of-the-art residual neural network architectures on the CIFAR datasets.
An Attention Model for group-level emotion recognition
Jul 09, 2018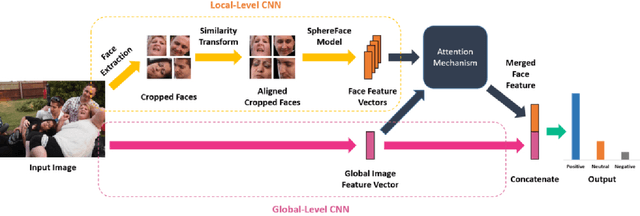
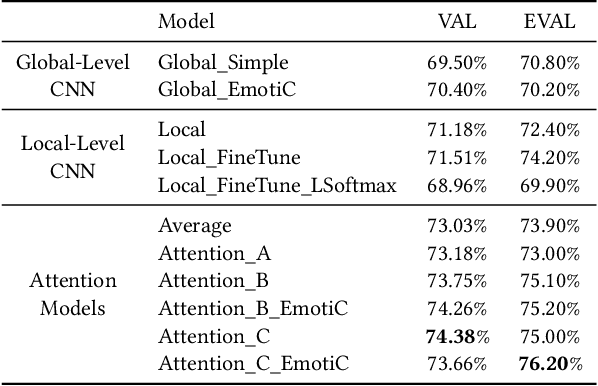
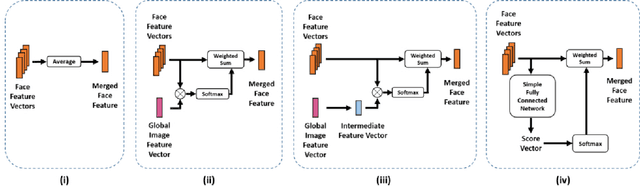
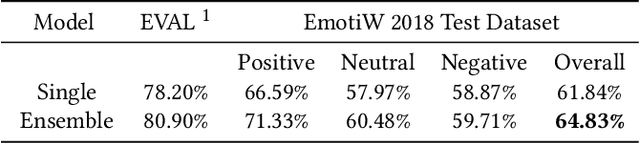
In this paper we propose a new approach for classifying the global emotion of images containing groups of people. To achieve this task, we consider two different and complementary sources of information: i) a global representation of the entire image (ii) a local representation where only faces are considered. While the global representation of the image is learned with a convolutional neural network (CNN), the local representation is obtained by merging face features through an attention mechanism. The two representations are first learned independently with two separate CNN branches and then fused through concatenation in order to obtain the final group-emotion classifier. For our submission to the EmotiW 2018 group-level emotion recognition challenge, we combine several variations of the proposed model into an ensemble, obtaining a final accuracy of 64.83% on the test set and ranking 4th among all challenge participants.