 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightSpeed: Light and Fast Neural Light Fields on Mobile Devices
Oct 26, 2023Real-time novel-view image synthesis on mobile devices is prohibitive due to the limited computational power and storage. Using volumetric rendering methods, such as NeRF and its derivatives, on mobile devices is not suitable due to the high computational cost of volumetric rendering. On the other hand, recent advances in neural light field representations have shown promising real-time view synthesis results on mobile devices. Neural light field methods learn a direct mapping from a ray representation to the pixel color. The current choice of ray representation is either stratified ray sampling or Plucker coordinates, overlooking the classic light slab (two-plane) representation, the preferred representation to interpolate between light field views. In this work, we find that using the light slab representation is an efficient representation for learning a neural light field. More importantly, it is a lower-dimensional ray representation enabling us to learn the 4D ray space using feature grids which are significantly faster to train and render. Although mostly designed for frontal views, we show that the light-slab representation can be further extended to non-frontal scenes using a divide-and-conquer strategy. Our method offers superior rendering quality compared to previous light field methods and achieves a significantly improved trade-off between rendering quality and speed.
* Project Page: http://lightspeed-r2l.github.io/ . Add camera ready version
Synthetic Expressions are Better Than Real for Learning to Detect Facial Actions
Oct 21, 2020
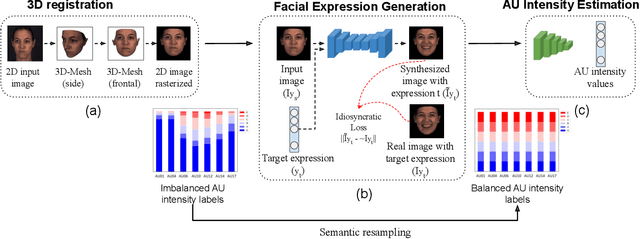

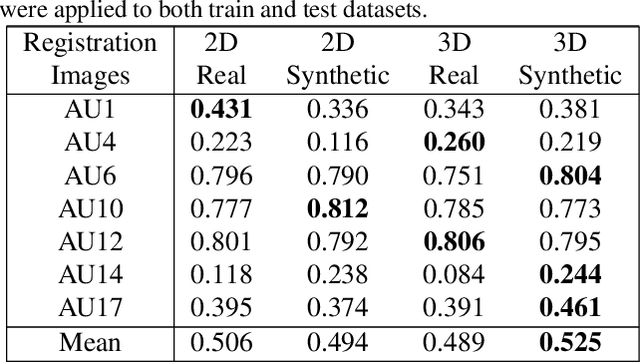
Critical obstacles in training classifiers to detect facial actions are the limited sizes of annotated video databases and the relatively low frequencies of occurrence of many actions. To address these problems, we propose an approach that makes use of facial expression generation. Our approach reconstructs the 3D shape of the face from each video frame, aligns the 3D mesh to a canonical view, and then trains a GAN-based network to synthesize novel images with facial action units of interest. To evaluate this approach, a deep neural network was trained on two separate datasets: One network was trained on video of synthesized facial expressions generated from FERA17; the other network was trained on unaltered video from the same database. Both networks used the same train and validation partitions and were tested on the test partition of actual video from FERA17. The network trained on synthesized facial expressions outperformed the one trained on actual facial expressions and surpassed current state-of-the-art approaches.