 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCTdiff: Intriguing Properties of Image Generative Modeling in the DCT Space
Dec 19, 2024This paper explores image modeling from the frequency space and introduces DCTdiff, an end-to-end diffusion generative paradigm that efficiently models images in the discrete cosine transform (DCT) space. We investigate the design space of DCTdiff and reveal the key design factors. Experiments on different frameworks (UViT, DiT), generation tasks, and various diffusion samplers demonstrate that DCTdiff outperforms pixel-based diffusion models regarding generative quality and training efficiency. Remarkably, DCTdiff can seamlessly scale up to high-resolution generation without using the latent diffusion paradigm. Finally, we illustrate several intriguing properties of DCT image modeling. For example, we provide a theoretical proof of why `image diffusion can be seen as spectral autoregression', bridging the gap between diffusion and autoregressive models. The effectiveness of DCTdiff and the introduced properties suggest a promising direction for image modeling in the frequency space. The code is at \url{https://github.com/forever208/DCTdiff}.
Representation Learning and Identity Adversarial Training for Facial Behavior Understanding
Jul 15, 2024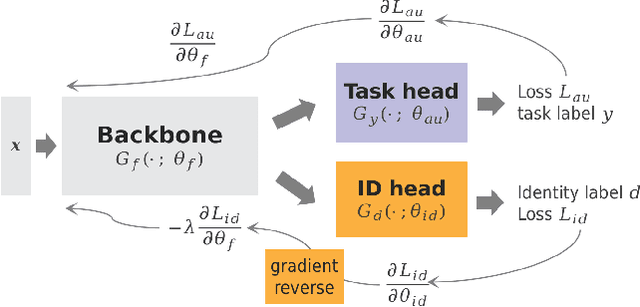
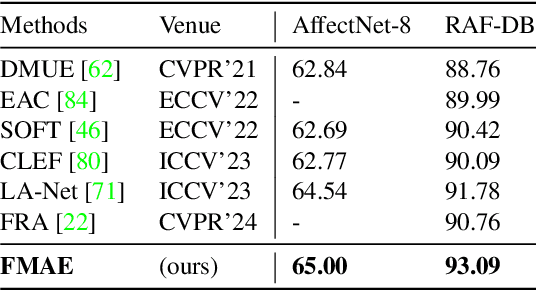
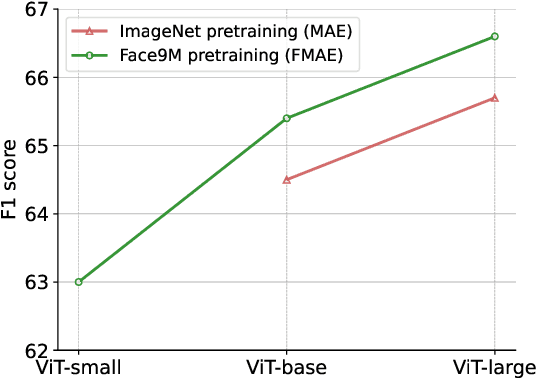
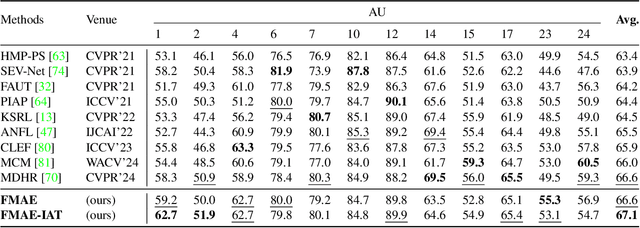
Facial Action Unit (AU) detection has gained significant research attention as AUs contain complex expression information. In this paper, we unpack two fundamental factors in AU detection: data and subject identity regularization, respectively. Motivated by recent advances in foundation models, we highlight the importance of data and collect a diverse dataset Face9M, comprising 9 million facial images, from multiple public resources. Pretraining a masked autoencoder on Face9M yields strong performance in AU detection and facial expression tasks. We then show that subject identity in AU datasets provides a shortcut learning for the model and leads to sub-optimal solutions to AU predictions. To tackle this generic issue of AU tasks, we propose Identity Adversarial Training (IAT) and demonstrate that a strong IAT regularization is necessary to learn identity-invariant features. Furthermore, we elucidate the design space of IAT and empirically show that IAT circumvents the identity shortcut learning and results in a better solution. Our proposed methods, Facial Masked Autoencoder (FMAE) and IAT, are simple, generic and effective. Remarkably, the proposed FMAE-IAT approach achieves new state-of-the-art F1 scores on BP4D (67.1\%), BP4D+ (66.8\%), and DISFA (70.1\%) databases, significantly outperforming previous work. We release the code and model at https://github.com/forever208/FMAE-IAT, the first open-sourced facial model pretrained on 9 million diverse images.
Elucidating the Exposure Bias in Diffusion Models
Sep 12, 2023Diffusion models have demonstrated impressive generative capabilities, but their 'exposure bias' problem, described as the input mismatch between training and sampling, lacks in-depth exploration. In this paper, we systematically investigate the exposure bias problem in diffusion models by first analytically modelling the sampling distribution, based on which we then attribute the prediction error at each sampling step as the root cause of the exposure bias issue. Furthermore, we discuss potential solutions to this issue and propose an intuitive metric for it. Along with the elucidation of exposure bias, we propose a simple, yet effective, training-free method called Epsilon Scaling to alleviate the exposure bias. We show that Epsilon Scaling explicitly moves the sampling trajectory closer to the vector field learned in the training phase by scaling down the network output (Epsilon), mitigating the input mismatch between training and sampling. Experiments on various diffusion frameworks (ADM, DDPM/DDIM, EDM, LDM), unconditional and conditional settings, and deterministic vs. stochastic sampling verify the effectiveness of our method. The code is available at https://github.com/forever208/ADM-ES; https://github.com/forever208/EDM-ES
Fully-attentive and interpretable: vision and video vision transformers for pain detection
Oct 27, 2022



Pain is a serious and costly issue globally, but to be treated, it must first be detected. Vision transformers are a top-performing architecture in computer vision, with little research on their use for pain detection. In this paper, we propose the first fully-attentive automated pain detection pipeline that achieves state-of-the-art performance on binary pain detection from facial expressions. The model is trained on the UNBC-McMaster dataset, after faces are 3D-registered and rotated to the canonical frontal view. In our experiments we identify important areas of the hyperparameter space and their interaction with vision and video vision transformers, obtaining 3 noteworthy models. We analyse the attention maps of one of our models, finding reasonable interpretations for its predictions. We also evaluate Mixup, an augmentation technique, and Sharpness-Aware Minimization, an optimizer, with no success. Our presented models, ViT-1 (F1 score 0.55 +- 0.15), ViViT-1 (F1 score 0.55 +- 0.13), and ViViT-2 (F1 score 0.49 +- 0.04), all outperform earlier works, showing the potential of vision transformers for pain detection. Code is available at https://github.com/IPDTFE/ViT-McMaster
Synthetic Expressions are Better Than Real for Learning to Detect Facial Actions
Oct 21, 2020
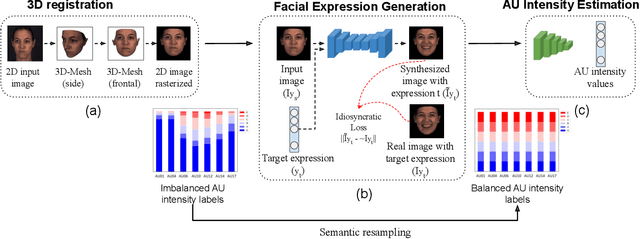

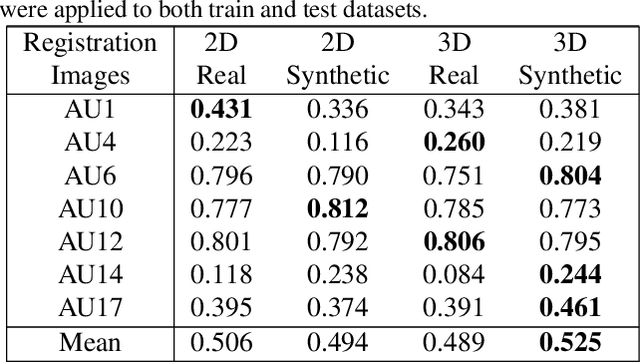
Critical obstacles in training classifiers to detect facial actions are the limited sizes of annotated video databases and the relatively low frequencies of occurrence of many actions. To address these problems, we propose an approach that makes use of facial expression generation. Our approach reconstructs the 3D shape of the face from each video frame, aligns the 3D mesh to a canonical view, and then trains a GAN-based network to synthesize novel images with facial action units of interest. To evaluate this approach, a deep neural network was trained on two separate datasets: One network was trained on video of synthesized facial expressions generated from FERA17; the other network was trained on unaltered video from the same database. Both networks used the same train and validation partitions and were tested on the test partition of actual video from FERA17. The network trained on synthesized facial expressions outperformed the one trained on actual facial expressions and surpassed current state-of-the-art approaches.
Modeling Brain Networks with Artificial Neural Networks
Jul 22, 2018
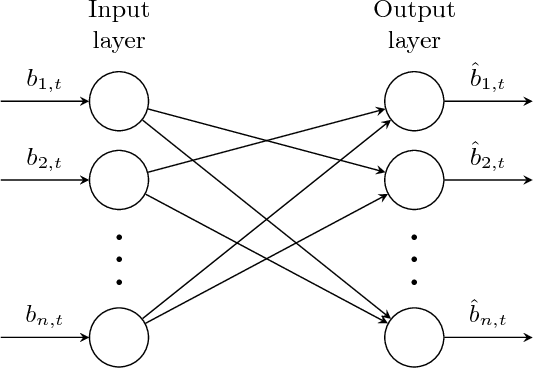
In this study, we propose a neural network approach to capture the functional connectivities among anatomic brain regions. The suggested approach estimates a set of brain networks, each of which represents the connectivity patterns of a cognitive process. We employ two different architectures of neural networks to extract directed and undirected brain networks from functional Magnetic Resonance Imaging (fMRI) data. Then, we use the edge weights of the estimated brain networks to train a classifier, namely, Support Vector Machines(SVM) to label the underlying cognitive process. We compare our brain network models with popular models, which generate similar functional brain networks. We observe that both undirected and directed brain networks surpass the performances of the network models used in the fMRI literature. We also observe that directed brain networks offer more discriminative features compared to the undirected ones for recognizing the cognitive processes. The representation power of the suggested brain networks are tested in a task-fMRI dataset of Human Connectome Project and a Complex Problem Solving dataset.
Hierarchical Multi-resolution Mesh Networks for Brain Decoding
Jan 11, 2017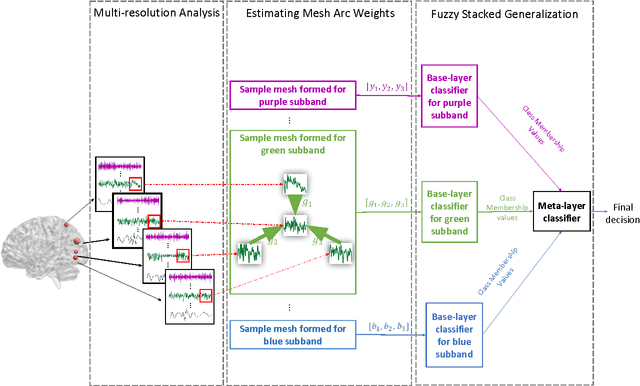

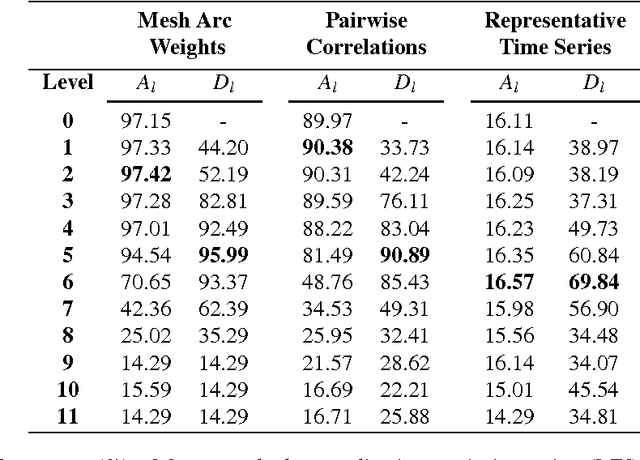
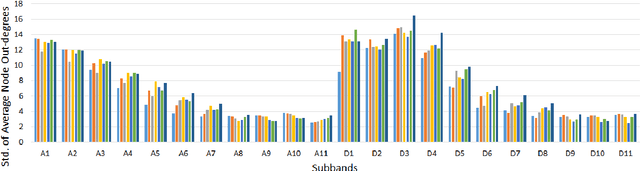
We propose a new framework, called Hierarchical Multi-resolution Mesh Networks (HMMNs), which establishes a set of brain networks at multiple time resolutions of fMRI signal to represent the underlying cognitive process. The suggested framework, first, decomposes the fMRI signal into various frequency subbands using wavelet transforms. Then, a brain network, called mesh network, is formed at each subband by ensembling a set of local meshes. The locality around each anatomic region is defined with respect to a neighborhood system based on functional connectivity. The arc weights of a mesh are estimated by ridge regression formed among the average region time series. In the final step, the adjacency matrices of mesh networks obtained at different subbands are ensembled for brain decoding under a hierarchical learning architecture, called, fuzzy stacked generalization (FSG). Our results on Human Connectome Project task-fMRI dataset reflect that the suggested HMMN model can successfully discriminate tasks by extracting complementary information obtained from mesh arc weights of multiple subbands. We study the topological properties of the mesh networks at different resolutions using the network measures, namely, node degree, node strength, betweenness centrality and global efficiency; and investigate the connectivity of anatomic regions, during a cognitive task. We observe significant variations among the network topologies obtained for different subbands. We, also, analyze the diversity properties of classifier ensemble, trained by the mesh networks in multiple subbands and observe that the classifiers in the ensemble collaborate with each other to fuse the complementary information freed at each subband. We conclude that the fMRI data, recorded during a cognitive task, embed diverse information across the anatomic regions at each resolution.
Encoding the Local Connectivity Patterns of fMRI for Cognitive State Classification
Oct 17, 2016
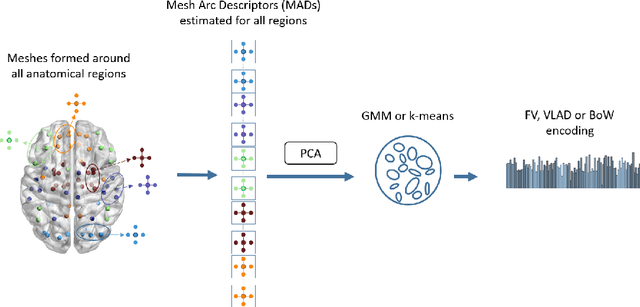

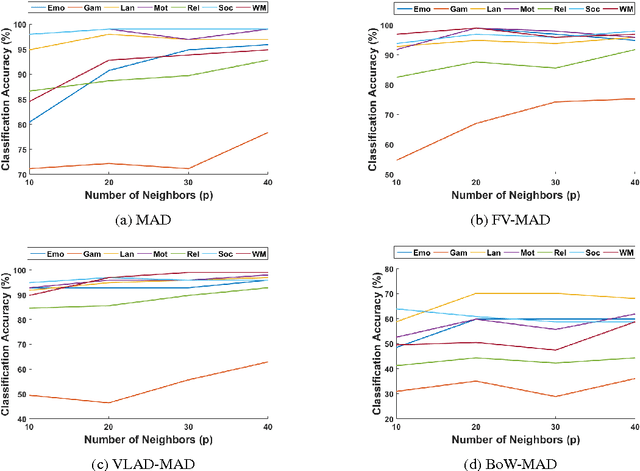
In this work, we propose a novel framework to encode the local connectivity patterns of brain, using Fisher Vectors (FV), Vector of Locally Aggregated Descriptors (VLAD) and Bag-of-Words (BoW) methods. We first obtain local descriptors, called Mesh Arc Descriptors (MADs) from fMRI data, by forming local meshes around anatomical regions, and estimating their relationship within a neighborhood. Then, we extract a dictionary of relationships, called \textit{brain connectivity dictionary} by fitting a generative Gaussian mixture model (GMM) to a set of MADs, and selecting the codewords at the mean of each component of the mixture. Codewords represent the connectivity patterns among anatomical regions. We also encode MADs by VLAD and BoW methods using the k-Means clustering. We classify the cognitive states of Human Connectome Project (HCP) task fMRI dataset, where we train support vector machines (SVM) by the encoded MADs. Results demonstrate that, FV encoding of MADs can be successfully employed for classification of cognitive tasks, and outperform the VLAD and BoW representations. Moreover, we identify the significant Gaussians in mixture models by computing energy of their corresponding FV parts, and analyze their effect on classification accuracy. Finally, we suggest a new method to visualize the codewords of brain connectivity dictionary.