 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum Matching: a Unified Perspective for Superior Diffusability in Latent Diffusion
Mar 15, 2026In this paper, we study the diffusability (learnability) of variational autoencoders (VAE) in latent diffusion. First, we show that pixel-space diffusion trained with an MSE objective is inherently biased toward learning low and mid spatial frequencies, and that the power-law power spectral density (PSD) of natural images makes this bias perceptually beneficial. Motivated by this result, we propose the \emph{Spectrum Matching Hypothesis}: latents with superior diffusability should (i) follow a flattened power-law PSD (\emph{Encoding Spectrum Matching}, ESM) and (ii) preserve frequency-to-frequency semantic correspondence through the decoder (\emph{Decoding Spectrum Matching}, DSM). In practice, we apply ESM by matching the PSD between images and latents, and DSM via shared spectral masking with frequency-aligned reconstruction. Importantly, Spectrum Matching provides a unified view that clarifies prior observations of over-noisy or over-smoothed latents, and interprets several recent methods as special cases (e.g., VA-VAE, EQ-VAE). Experiments suggest that Spectrum Matching yields superior diffusion generation on CelebA and ImageNet datasets, and outperforms prior approaches. Finally, we extend the spectral view to representation alignment (REPA): we show that the directional spectral energy of the target representation is crucial for REPA, and propose a DoG-based method to further improve the performance of REPA. Our code is available https://github.com/forever208/SpectrumMatching.
Consistent Story Generation with Asymmetry Zigzag Sampling
Jun 12, 2025Text-to-image generation models have made significant progress in producing high-quality images from textual descriptions, yet they continue to struggle with maintaining subject consistency across multiple images, a fundamental requirement for visual storytelling. Existing methods attempt to address this by either fine-tuning models on large-scale story visualization datasets, which is resource-intensive, or by using training-free techniques that share information across generations, which still yield limited success. In this paper, we introduce a novel training-free sampling strategy called Zigzag Sampling with Asymmetric Prompts and Visual Sharing to enhance subject consistency in visual story generation. Our approach proposes a zigzag sampling mechanism that alternates between asymmetric prompting to retain subject characteristics, while a visual sharing module transfers visual cues across generated images to %further enforce consistency. Experimental results, based on both quantitative metrics and qualitative evaluations, demonstrate that our method significantly outperforms previous approaches in generating coherent and consistent visual stories. The code is available at https://github.com/Mingxiao-Li/Asymmetry-Zigzag-StoryDiffusion.
DCTdiff: Intriguing Properties of Image Generative Modeling in the DCT Space
Dec 19, 2024This paper explores image modeling from the frequency space and introduces DCTdiff, an end-to-end diffusion generative paradigm that efficiently models images in the discrete cosine transform (DCT) space. We investigate the design space of DCTdiff and reveal the key design factors. Experiments on different frameworks (UViT, DiT), generation tasks, and various diffusion samplers demonstrate that DCTdiff outperforms pixel-based diffusion models regarding generative quality and training efficiency. Remarkably, DCTdiff can seamlessly scale up to high-resolution generation without using the latent diffusion paradigm. Finally, we illustrate several intriguing properties of DCT image modeling. For example, we provide a theoretical proof of why `image diffusion can be seen as spectral autoregression', bridging the gap between diffusion and autoregressive models. The effectiveness of DCTdiff and the introduced properties suggest a promising direction for image modeling in the frequency space. The code is at \url{https://github.com/forever208/DCTdiff}.
Representation Learning and Identity Adversarial Training for Facial Behavior Understanding
Jul 15, 2024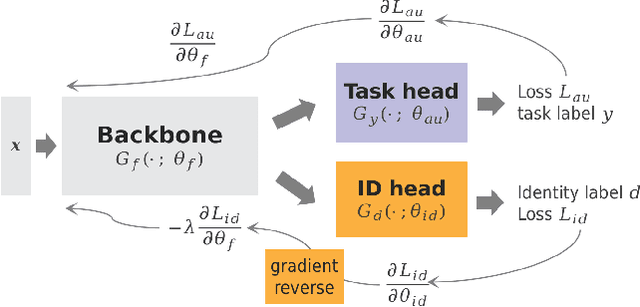
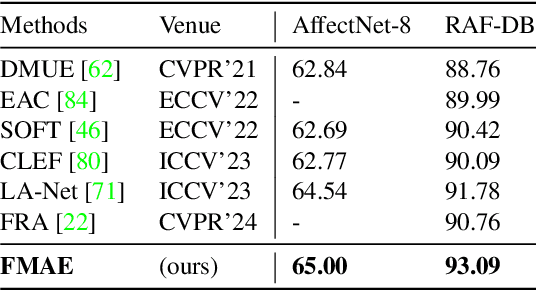
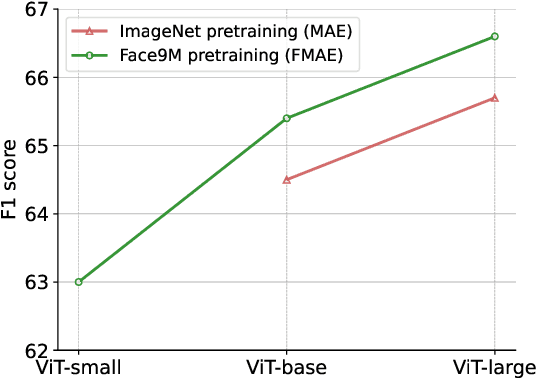
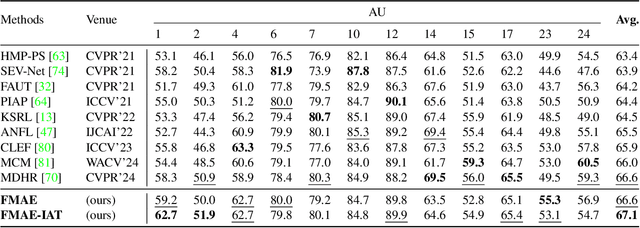
Facial Action Unit (AU) detection has gained significant research attention as AUs contain complex expression information. In this paper, we unpack two fundamental factors in AU detection: data and subject identity regularization, respectively. Motivated by recent advances in foundation models, we highlight the importance of data and collect a diverse dataset Face9M, comprising 9 million facial images, from multiple public resources. Pretraining a masked autoencoder on Face9M yields strong performance in AU detection and facial expression tasks. We then show that subject identity in AU datasets provides a shortcut learning for the model and leads to sub-optimal solutions to AU predictions. To tackle this generic issue of AU tasks, we propose Identity Adversarial Training (IAT) and demonstrate that a strong IAT regularization is necessary to learn identity-invariant features. Furthermore, we elucidate the design space of IAT and empirically show that IAT circumvents the identity shortcut learning and results in a better solution. Our proposed methods, Facial Masked Autoencoder (FMAE) and IAT, are simple, generic and effective. Remarkably, the proposed FMAE-IAT approach achieves new state-of-the-art F1 scores on BP4D (67.1\%), BP4D+ (66.8\%), and DISFA (70.1\%) databases, significantly outperforming previous work. We release the code and model at https://github.com/forever208/FMAE-IAT, the first open-sourced facial model pretrained on 9 million diverse images.
Elucidating the Exposure Bias in Diffusion Models
Sep 12, 2023Diffusion models have demonstrated impressive generative capabilities, but their 'exposure bias' problem, described as the input mismatch between training and sampling, lacks in-depth exploration. In this paper, we systematically investigate the exposure bias problem in diffusion models by first analytically modelling the sampling distribution, based on which we then attribute the prediction error at each sampling step as the root cause of the exposure bias issue. Furthermore, we discuss potential solutions to this issue and propose an intuitive metric for it. Along with the elucidation of exposure bias, we propose a simple, yet effective, training-free method called Epsilon Scaling to alleviate the exposure bias. We show that Epsilon Scaling explicitly moves the sampling trajectory closer to the vector field learned in the training phase by scaling down the network output (Epsilon), mitigating the input mismatch between training and sampling. Experiments on various diffusion frameworks (ADM, DDPM/DDIM, EDM, LDM), unconditional and conditional settings, and deterministic vs. stochastic sampling verify the effectiveness of our method. The code is available at https://github.com/forever208/ADM-ES; https://github.com/forever208/EDM-ES
Input Perturbation Reduces Exposure Bias in Diffusion Models
Jan 27, 2023Denoising Diffusion Probabilistic Models have shown an impressive generation quality, although their long sampling chain leads to high computational costs. In this paper, we observe that a long sampling chain also leads to an error accumulation phenomenon, which is similar to the \textbf{exposure bias} problem in autoregressive text generation. Specifically, we note that there is a discrepancy between training and testing, since the former is conditioned on the ground truth samples, while the latter is conditioned on the previously generated results. To alleviate this problem, we propose a very simple but effective training regularization, consisting in perturbing the ground truth samples to simulate the inference time prediction errors. We empirically show that the proposed input perturbation leads to a significant improvement of the sample quality while reducing both the training and the inference times. For instance, on CelebA 64$\times$64, we achieve a new state-of-the-art FID score of 1.27, while saving 37.5% of the training time.