 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAER: Temporal Aligned Rehearsal for Continual Spiking Neural Network
Jan 16, 2026Spiking Neural Networks (SNNs) are inherently suited for continuous learning due to their event-driven temporal dynamics; however, their application to Class-Incremental Learning (CIL) has been hindered by catastrophic forgetting and the temporal misalignment of spike patterns. In this work, we introduce Spiking Temporal Alignment with Experience Replay (STAER), a novel framework that explicitly preserves temporal structure to bridge the performance gap between SNNs and ANNs. Our approach integrates a differentiable Soft-DTW alignment loss to maintain spike timing fidelity and employs a temporal expansion and contraction mechanism on output logits to enforce robust representation learning. Implemented on a deep ResNet19 spiking backbone, STAER achieves state-of-the-art performance on Sequential-MNIST and Sequential-CIFAR10. Empirical results demonstrate that our method matches or outperforms strong ANN baselines (ER, DER++) while preserving biologically plausible dynamics. Ablation studies further confirm that explicit temporal alignment is critical for representational stability, positioning STAER as a scalable solution for spike-native lifelong learning. Code is available at https://github.com/matteogianferrari/staer.
Intrinsic Training Signals for Federated Learning Aggregation
Jul 09, 2025Federated Learning (FL) enables collaborative model training across distributed clients while preserving data privacy. While existing approaches for aggregating client-specific classification heads and adapted backbone parameters require architectural modifications or loss function changes, our method uniquely leverages intrinsic training signals already available during standard optimization. We present LIVAR (Layer Importance and VARiance-based merging), which introduces: i) a variance-weighted classifier aggregation scheme using naturally emergent feature statistics, and ii) an explainability-driven LoRA merging technique based on SHAP analysis of existing update parameter patterns. Without any architectural overhead, LIVAR achieves state-of-the-art performance on multiple benchmarks while maintaining seamless integration with existing FL methods. This work demonstrates that effective model merging can be achieved solely through existing training signals, establishing a new paradigm for efficient federated model aggregation. The code will be made publicly available upon acceptance.
Update Your Transformer to the Latest Release: Re-Basin of Task Vectors
May 28, 2025Foundation models serve as the backbone for numerous specialized models developed through fine-tuning. However, when the underlying pretrained model is updated or retrained (e.g., on larger and more curated datasets), the fine-tuned model becomes obsolete, losing its utility and requiring retraining. This raises the question: is it possible to transfer fine-tuning to a new release of the model? In this work, we investigate how to transfer fine-tuning to a new checkpoint without having to re-train, in a data-free manner. To do so, we draw principles from model re-basin and provide a recipe based on weight permutations to re-base the modifications made to the original base model, often called task vector. In particular, our approach tailors model re-basin for Transformer models, taking into account the challenges of residual connections and multi-head attention layers. Specifically, we propose a two-level method rooted in spectral theory, initially permuting the attention heads and subsequently adjusting parameters within select pairs of heads. Through extensive experiments on visual and textual tasks, we achieve the seamless transfer of fine-tuned knowledge to new pre-trained backbones without relying on a single training step or datapoint. Code is available at https://github.com/aimagelab/TransFusion.
How to Train Your Metamorphic Deep Neural Network
May 07, 2025



Neural Metamorphosis (NeuMeta) is a recent paradigm for generating neural networks of varying width and depth. Based on Implicit Neural Representation (INR), NeuMeta learns a continuous weight manifold, enabling the direct generation of compressed models, including those with configurations not seen during training. While promising, the original formulation of NeuMeta proves effective only for the final layers of the undelying model, limiting its broader applicability. In this work, we propose a training algorithm that extends the capabilities of NeuMeta to enable full-network metamorphosis with minimal accuracy degradation. Our approach follows a structured recipe comprising block-wise incremental training, INR initialization, and strategies for replacing batch normalization. The resulting metamorphic networks maintain competitive accuracy across a wide range of compression ratios, offering a scalable solution for adaptable and efficient deployment of deep models. The code is available at: https://github.com/TSommariva/HTTY_NeuMeta.
DitHub: A Modular Framework for Incremental Open-Vocabulary Object Detection
Mar 12, 2025Open-Vocabulary object detectors can recognize a wide range of categories using simple textual prompts. However, improving their ability to detect rare classes or specialize in certain domains remains a challenge. While most recent methods rely on a single set of model weights for adaptation, we take a different approach by using modular deep learning. We introduce DitHub, a framework designed to create and manage a library of efficient adaptation modules. Inspired by Version Control Systems, DitHub organizes expert modules like branches that can be fetched and merged as needed. This modular approach enables a detailed study of how adaptation modules combine, making it the first method to explore this aspect in Object Detection. Our approach achieves state-of-the-art performance on the ODinW-13 benchmark and ODinW-O, a newly introduced benchmark designed to evaluate how well models adapt when previously seen classes reappear. For more details, visit our project page: https://aimagelab.github.io/DitHub/
Is Multiple Object Tracking a Matter of Specialization?
Nov 01, 2024



End-to-end transformer-based trackers have achieved remarkable performance on most human-related datasets. However, training these trackers in heterogeneous scenarios poses significant challenges, including negative interference - where the model learns conflicting scene-specific parameters - and limited domain generalization, which often necessitates expensive fine-tuning to adapt the models to new domains. In response to these challenges, we introduce Parameter-efficient Scenario-specific Tracking Architecture (PASTA), a novel framework that combines Parameter-Efficient Fine-Tuning (PEFT) and Modular Deep Learning (MDL). Specifically, we define key scenario attributes (e.g, camera-viewpoint, lighting condition) and train specialized PEFT modules for each attribute. These expert modules are combined in parameter space, enabling systematic generalization to new domains without increasing inference time. Extensive experiments on MOTSynth, along with zero-shot evaluations on MOT17 and PersonPath22 demonstrate that a neural tracker built from carefully selected modules surpasses its monolithic counterpart. We release models and code.
Closed-form merging of parameter-efficient modules for Federated Continual Learning
Oct 23, 2024



Model merging has emerged as a crucial technique in Deep Learning, enabling the integration of multiple models into a unified system while preserving performance and scalability. In this respect, the compositional properties of low-rank adaptation techniques (e.g., LoRA) have proven beneficial, as simple averaging LoRA modules yields a single model that mostly integrates the capabilities of all individual modules. Building on LoRA, we take a step further by imposing that the merged model matches the responses of all learned modules. Solving this objective in closed form yields an indeterminate system with A and B as unknown variables, indicating the existence of infinitely many closed-form solutions. To address this challenge, we introduce LoRM, an alternating optimization strategy that trains one LoRA matrix at a time. This allows solving for each unknown variable individually, thus finding a unique solution. We apply our proposed methodology to Federated Class-Incremental Learning (FCIL), ensuring alignment of model responses both between clients and across tasks. Our method demonstrates state-of-the-art performance across a range of FCIL scenarios.
May the Forgetting Be with You: Alternate Replay for Learning with Noisy Labels
Aug 26, 2024Forgetting presents a significant challenge during incremental training, making it particularly demanding for contemporary AI systems to assimilate new knowledge in streaming data environments. To address this issue, most approaches in Continual Learning (CL) rely on the replay of a restricted buffer of past data. However, the presence of noise in real-world scenarios, where human annotation is constrained by time limitations or where data is automatically gathered from the web, frequently renders these strategies vulnerable. In this study, we address the problem of CL under Noisy Labels (CLN) by introducing Alternate Experience Replay (AER), which takes advantage of forgetting to maintain a clear distinction between clean, complex, and noisy samples in the memory buffer. The idea is that complex or mislabeled examples, which hardly fit the previously learned data distribution, are most likely to be forgotten. To grasp the benefits of such a separation, we equip AER with Asymmetric Balanced Sampling (ABS): a new sample selection strategy that prioritizes purity on the current task while retaining relevant samples from the past. Through extensive computational comparisons, we demonstrate the effectiveness of our approach in terms of both accuracy and purity of the obtained buffer, resulting in a remarkable average gain of 4.71% points in accuracy with respect to existing loss-based purification strategies. Code is available at https://github.com/aimagelab/mammoth.
CLIP with Generative Latent Replay: a Strong Baseline for Incremental Learning
Jul 22, 2024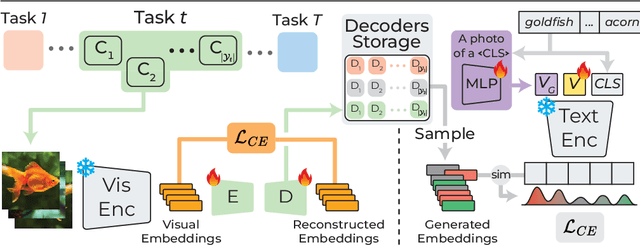
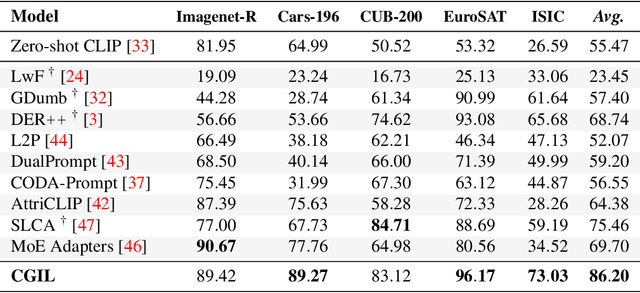
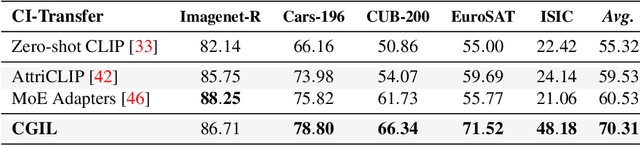
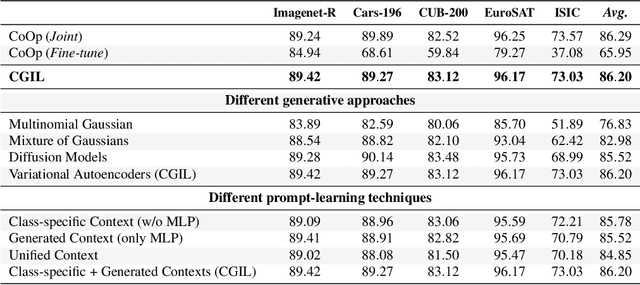
With the emergence of Transformers and Vision-Language Models (VLMs) such as CLIP, large pre-trained models have become a common strategy to enhance performance in Continual Learning scenarios. This led to the development of numerous prompting strategies to effectively fine-tune transformer-based models without succumbing to catastrophic forgetting. However, these methods struggle to specialize the model on domains significantly deviating from the pre-training and preserving its zero-shot capabilities. In this work, we propose Continual Generative training for Incremental prompt-Learning, a novel approach to mitigate forgetting while adapting a VLM, which exploits generative replay to align prompts to tasks. We also introduce a new metric to evaluate zero-shot capabilities within CL benchmarks. Through extensive experiments on different domains, we demonstrate the effectiveness of our framework in adapting to new tasks while improving zero-shot capabilities. Further analysis reveals that our approach can bridge the gap with joint prompt tuning. The codebase is available at https://github.com/aimagelab/mammoth.
An Attention-based Representation Distillation Baseline for Multi-Label Continual Learning
Jul 19, 2024


The field of Continual Learning (CL) has inspired numerous researchers over the years, leading to increasingly advanced countermeasures to the issue of catastrophic forgetting. Most studies have focused on the single-class scenario, where each example comes with a single label. The recent literature has successfully tackled such a setting, with impressive results. Differently, we shift our attention to the multi-label scenario, as we feel it to be more representative of real-world open problems. In our work, we show that existing state-of-the-art CL methods fail to achieve satisfactory performance, thus questioning the real advance claimed in recent years. Therefore, we assess both old-style and novel strategies and propose, on top of them, an approach called Selective Class Attention Distillation (SCAD). It relies on a knowledge transfer technique that seeks to align the representations of the student network -- which trains continuously and is subject to forgetting -- with the teacher ones, which is pretrained and kept frozen. Importantly, our method is able to selectively transfer the relevant information from the teacher to the student, thereby preventing irrelevant information from harming the student's performance during online training. To demonstrate the merits of our approach, we conduct experiments on two different multi-label datasets, showing that our method outperforms the current state-of-the-art Continual Learning methods. Our findings highlight the importance of addressing the unique challenges posed by multi-label environments in the field of Continual Learning. The code of SCAD is available at https://github.com/aimagelab/SCAD-LOD-2024.