 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataless Weight Disentanglement in Task Arithmetic via Kronecker-Factored Approximate Curvature
Feb 19, 2026Task Arithmetic yields a modular, scalable way to adapt foundation models. Combining multiple task vectors, however, can lead to cross-task interference, causing representation drift and degraded performance. Representation drift regularization provides a natural remedy to disentangle task vectors; however, existing approaches typically require external task data, conflicting with modularity and data availability constraints (e.g., privacy requirements). We propose a dataless approach by framing regularization against representation drift as a curvature matrix approximation problem. This allows us to leverage well-established techniques; in particular, we adopt Kronecker-Factored Approximate Curvature and obtain a practical regularizer that achieves state-of-the-art results in task addition and negation. Our method has constant complexity in the number of tasks and promotes robustness to task vector rescaling, eliminating the need for held-out tuning.
Update Your Transformer to the Latest Release: Re-Basin of Task Vectors
May 28, 2025Foundation models serve as the backbone for numerous specialized models developed through fine-tuning. However, when the underlying pretrained model is updated or retrained (e.g., on larger and more curated datasets), the fine-tuned model becomes obsolete, losing its utility and requiring retraining. This raises the question: is it possible to transfer fine-tuning to a new release of the model? In this work, we investigate how to transfer fine-tuning to a new checkpoint without having to re-train, in a data-free manner. To do so, we draw principles from model re-basin and provide a recipe based on weight permutations to re-base the modifications made to the original base model, often called task vector. In particular, our approach tailors model re-basin for Transformer models, taking into account the challenges of residual connections and multi-head attention layers. Specifically, we propose a two-level method rooted in spectral theory, initially permuting the attention heads and subsequently adjusting parameters within select pairs of heads. Through extensive experiments on visual and textual tasks, we achieve the seamless transfer of fine-tuned knowledge to new pre-trained backbones without relying on a single training step or datapoint. Code is available at https://github.com/aimagelab/TransFusion.
May the Forgetting Be with You: Alternate Replay for Learning with Noisy Labels
Aug 26, 2024Forgetting presents a significant challenge during incremental training, making it particularly demanding for contemporary AI systems to assimilate new knowledge in streaming data environments. To address this issue, most approaches in Continual Learning (CL) rely on the replay of a restricted buffer of past data. However, the presence of noise in real-world scenarios, where human annotation is constrained by time limitations or where data is automatically gathered from the web, frequently renders these strategies vulnerable. In this study, we address the problem of CL under Noisy Labels (CLN) by introducing Alternate Experience Replay (AER), which takes advantage of forgetting to maintain a clear distinction between clean, complex, and noisy samples in the memory buffer. The idea is that complex or mislabeled examples, which hardly fit the previously learned data distribution, are most likely to be forgotten. To grasp the benefits of such a separation, we equip AER with Asymmetric Balanced Sampling (ABS): a new sample selection strategy that prioritizes purity on the current task while retaining relevant samples from the past. Through extensive computational comparisons, we demonstrate the effectiveness of our approach in terms of both accuracy and purity of the obtained buffer, resulting in a remarkable average gain of 4.71% points in accuracy with respect to existing loss-based purification strategies. Code is available at https://github.com/aimagelab/mammoth.
CLIP with Generative Latent Replay: a Strong Baseline for Incremental Learning
Jul 22, 2024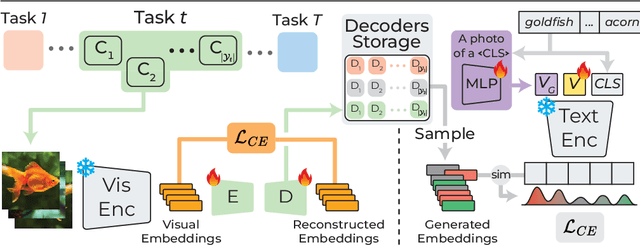
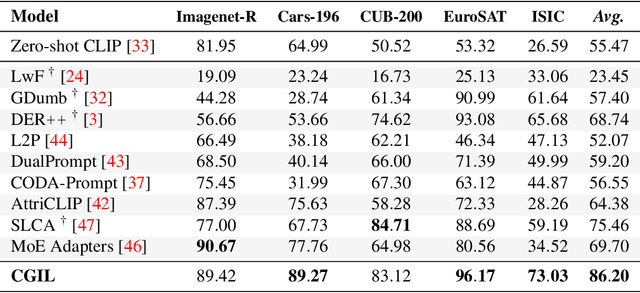
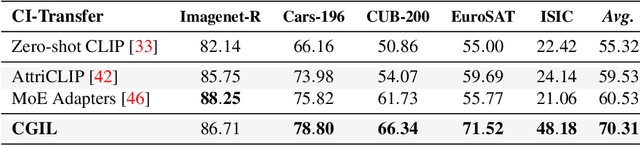
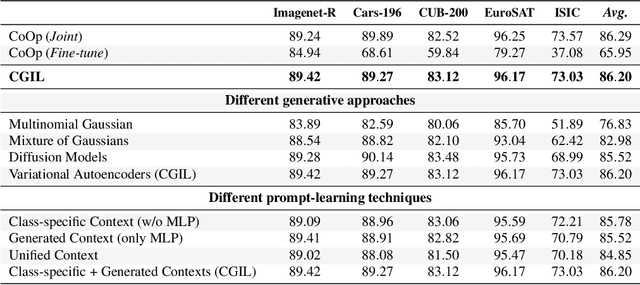
With the emergence of Transformers and Vision-Language Models (VLMs) such as CLIP, large pre-trained models have become a common strategy to enhance performance in Continual Learning scenarios. This led to the development of numerous prompting strategies to effectively fine-tune transformer-based models without succumbing to catastrophic forgetting. However, these methods struggle to specialize the model on domains significantly deviating from the pre-training and preserving its zero-shot capabilities. In this work, we propose Continual Generative training for Incremental prompt-Learning, a novel approach to mitigate forgetting while adapting a VLM, which exploits generative replay to align prompts to tasks. We also introduce a new metric to evaluate zero-shot capabilities within CL benchmarks. Through extensive experiments on different domains, we demonstrate the effectiveness of our framework in adapting to new tasks while improving zero-shot capabilities. Further analysis reveals that our approach can bridge the gap with joint prompt tuning. The codebase is available at https://github.com/aimagelab/mammoth.
An Attention-based Representation Distillation Baseline for Multi-Label Continual Learning
Jul 19, 2024


The field of Continual Learning (CL) has inspired numerous researchers over the years, leading to increasingly advanced countermeasures to the issue of catastrophic forgetting. Most studies have focused on the single-class scenario, where each example comes with a single label. The recent literature has successfully tackled such a setting, with impressive results. Differently, we shift our attention to the multi-label scenario, as we feel it to be more representative of real-world open problems. In our work, we show that existing state-of-the-art CL methods fail to achieve satisfactory performance, thus questioning the real advance claimed in recent years. Therefore, we assess both old-style and novel strategies and propose, on top of them, an approach called Selective Class Attention Distillation (SCAD). It relies on a knowledge transfer technique that seeks to align the representations of the student network -- which trains continuously and is subject to forgetting -- with the teacher ones, which is pretrained and kept frozen. Importantly, our method is able to selectively transfer the relevant information from the teacher to the student, thereby preventing irrelevant information from harming the student's performance during online training. To demonstrate the merits of our approach, we conduct experiments on two different multi-label datasets, showing that our method outperforms the current state-of-the-art Continual Learning methods. Our findings highlight the importance of addressing the unique challenges posed by multi-label environments in the field of Continual Learning. The code of SCAD is available at https://github.com/aimagelab/SCAD-LOD-2024.
A Second-Order perspective on Compositionality and Incremental Learning
May 25, 2024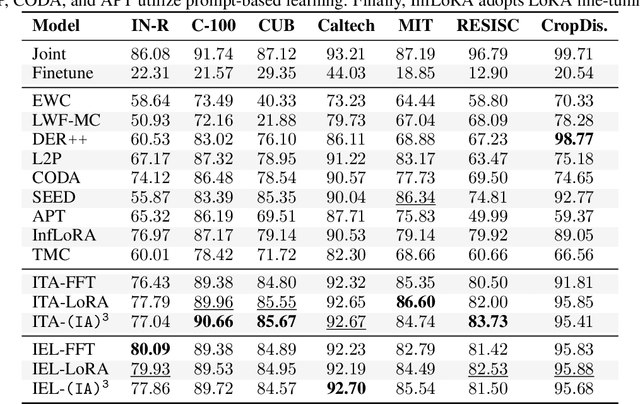
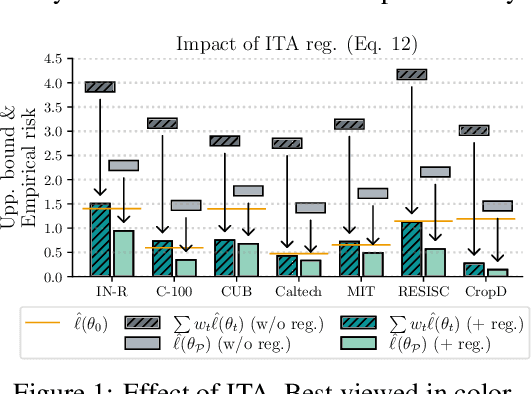
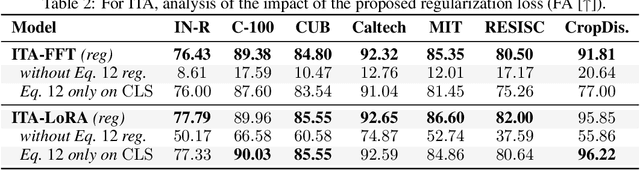
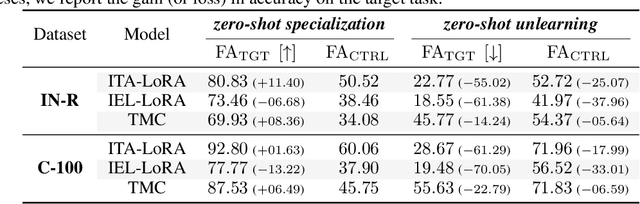
The fine-tuning of deep pre-trained models has recently revealed compositional properties. This enables the arbitrary composition of multiple specialized modules into a single, multi-task model. However, identifying the conditions that promote compositionality remains an open issue, with recent efforts concentrating mainly on linearized networks. We conduct a theoretical study that attempts to demystify compositionality in standard non-linear networks through the second-order Taylor approximation of the loss function. The proposed formulation highlights the importance of staying within the pre-training basin for achieving composable modules. Moreover, it provides the basis for two dual incremental training algorithms: the one from the perspective of multiple models trained individually, while the other aims to optimize the composed model as a whole. We probe their application in incremental classification tasks and highlight some valuable skills. In fact, the pool of incrementally learned modules not only supports the creation of an effective multi-task model but also enables unlearning and specialization in specific tasks.
Semantic Residual Prompts for Continual Learning
Mar 14, 2024Prompt-tuning methods for Continual Learning (CL) freeze a large pre-trained model and focus training on a few parameter vectors termed prompts. Most of these methods organize these vectors in a pool of key-value pairs, and use the input image as query to retrieve the prompts (values). However, as keys are learned while tasks progress, the prompting selection strategy is itself subject to catastrophic forgetting, an issue often overlooked by existing approaches. For instance, prompts introduced to accommodate new tasks might end up interfering with previously learned prompts. To make the selection strategy more stable, we ask a foundational model (CLIP) to select our prompt within a two-level adaptation mechanism. Specifically, the first level leverages standard textual prompts for the CLIP textual encoder, leading to stable class prototypes. The second level, instead, uses these prototypes along with the query image as keys to index a second pool. The retrieved prompts serve to adapt a pre-trained ViT, granting plasticity. In doing so, we also propose a novel residual mechanism to transfer CLIP semantics to the ViT layers. Through extensive analysis on established CL benchmarks, we show that our method significantly outperforms both state-of-the-art CL approaches and the zero-shot CLIP test. Notably, our findings hold true even for datasets with a substantial domain gap w.r.t. the pre-training knowledge of the backbone model, as showcased by experiments on satellite imagery and medical datasets.
On the Effectiveness of Equivariant Regularization for Robust Online Continual Learning
May 05, 2023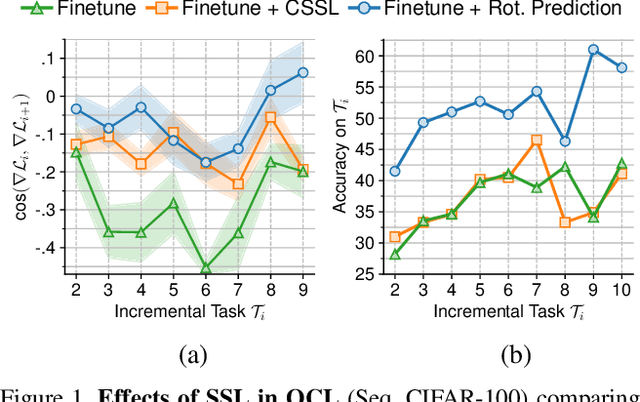
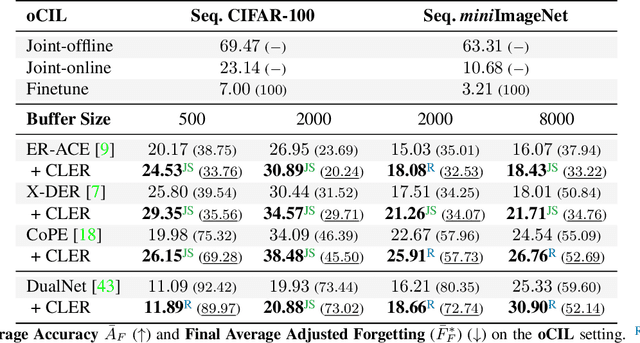
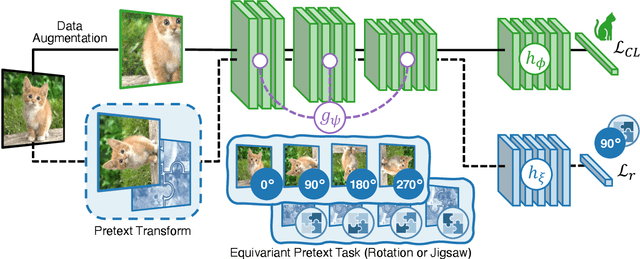
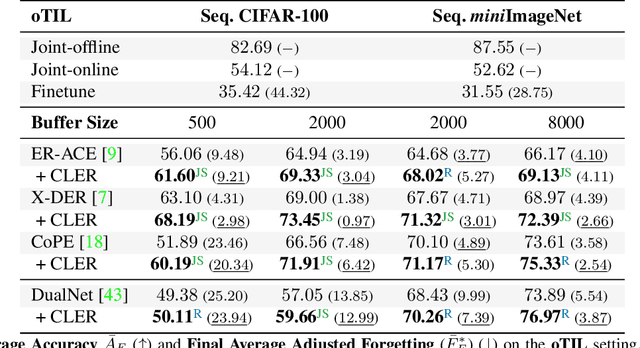
Humans can learn incrementally, whereas neural networks forget previously acquired information catastrophically. Continual Learning (CL) approaches seek to bridge this gap by facilitating the transfer of knowledge to both previous tasks (backward transfer) and future ones (forward transfer) during training. Recent research has shown that self-supervision can produce versatile models that can generalize well to diverse downstream tasks. However, contrastive self-supervised learning (CSSL), a popular self-supervision technique, has limited effectiveness in online CL (OCL). OCL only permits one iteration of the input dataset, and CSSL's low sample efficiency hinders its use on the input data-stream. In this work, we propose Continual Learning via Equivariant Regularization (CLER), an OCL approach that leverages equivariant tasks for self-supervision, avoiding CSSL's limitations. Our method represents the first attempt at combining equivariant knowledge with CL and can be easily integrated with existing OCL methods. Extensive ablations shed light on how equivariant pretext tasks affect the network's information flow and its impact on CL dynamics.
On the Effectiveness of Lipschitz-Driven Rehearsal in Continual Learning
Oct 16, 2022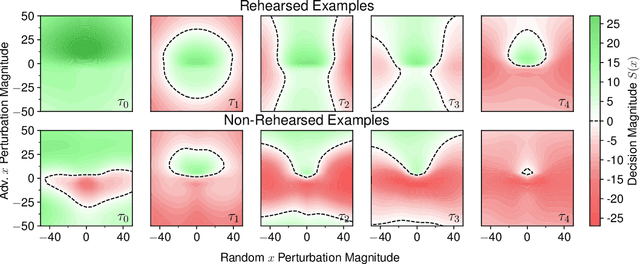
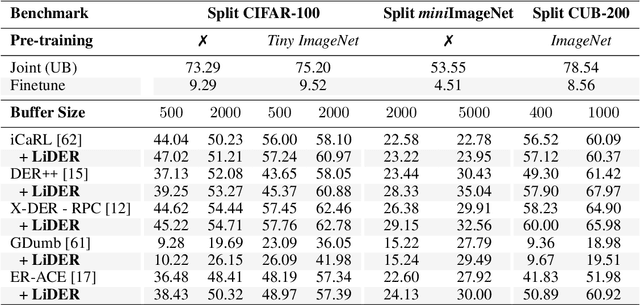
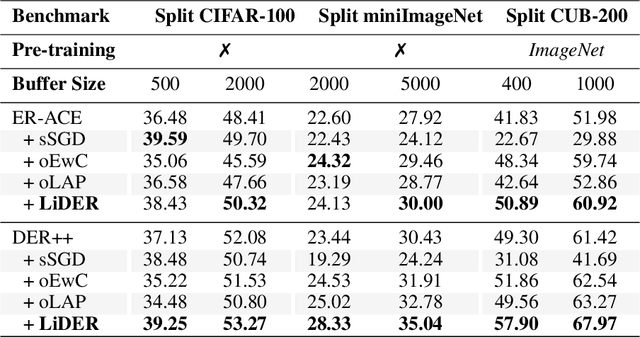
Rehearsal approaches enjoy immense popularity with Continual Learning (CL) practitioners. These methods collect samples from previously encountered data distributions in a small memory buffer; subsequently, they repeatedly optimize on the latter to prevent catastrophic forgetting. This work draws attention to a hidden pitfall of this widespread practice: repeated optimization on a small pool of data inevitably leads to tight and unstable decision boundaries, which are a major hindrance to generalization. To address this issue, we propose Lipschitz-DrivEn Rehearsal (LiDER), a surrogate objective that induces smoothness in the backbone network by constraining its layer-wise Lipschitz constants w.r.t. replay examples. By means of extensive experiments, we show that applying LiDER delivers a stable performance gain to several state-of-the-art rehearsal CL methods across multiple datasets, both in the presence and absence of pre-training. Through additional ablative experiments, we highlight peculiar aspects of buffer overfitting in CL and better characterize the effect produced by LiDER. Code is available at https://github.com/aimagelab/LiDER
Spotting Virus from Satellites: Modeling the Circulation of West Nile Virus Through Graph Neural Networks
Sep 07, 2022
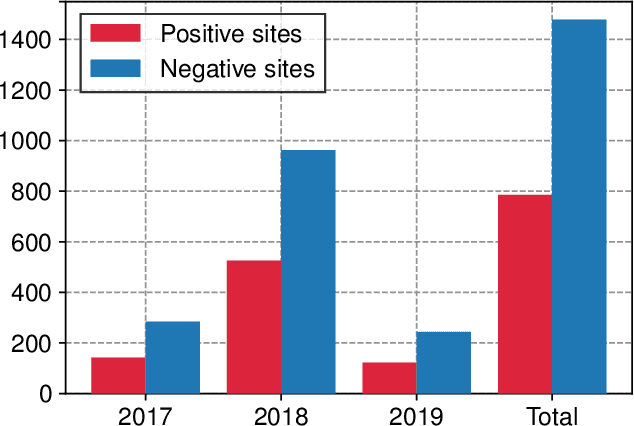
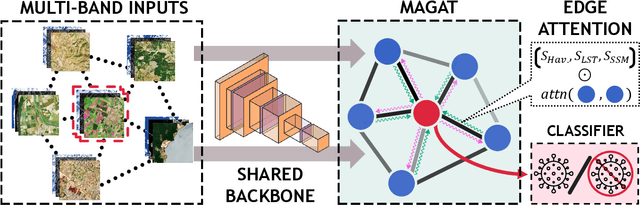
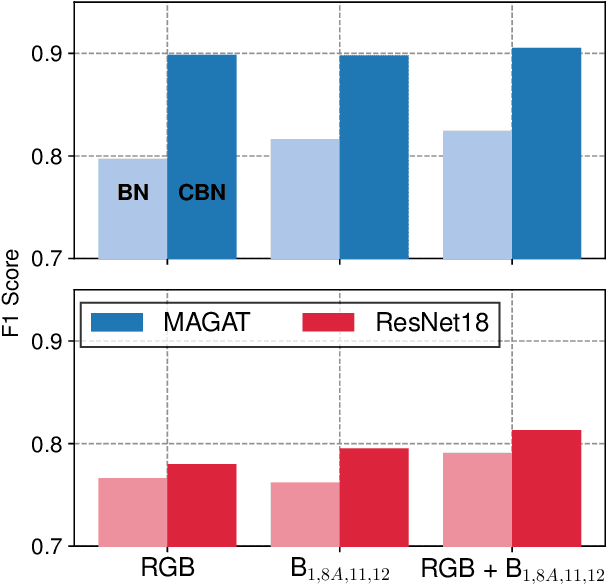
The occurrence of West Nile Virus (WNV) represents one of the most common mosquito-borne zoonosis viral infections. Its circulation is usually associated with climatic and environmental conditions suitable for vector proliferation and virus replication. On top of that, several statistical models have been developed to shape and forecast WNV circulation: in particular, the recent massive availability of Earth Observation (EO) data, coupled with the continuous advances in the field of Artificial Intelligence, offer valuable opportunities. In this paper, we seek to predict WNV circulation by feeding Deep Neural Networks (DNNs) with satellite images, which have been extensively shown to hold environmental and climatic features. Notably, while previous approaches analyze each geographical site independently, we propose a spatial-aware approach that considers also the characteristics of close sites. Specifically, we build upon Graph Neural Networks (GNN) to aggregate features from neighbouring places, and further extend these modules to consider multiple relations, such as the difference in temperature and soil moisture between two sites, as well as the geographical distance. Moreover, we inject time-related information directly into the model to take into account the seasonality of virus spread. We design an experimental setting that combines satellite images - from Landsat and Sentinel missions - with ground truth observations of WNV circulation in Italy. We show that our proposed Multi-Adjacency Graph Attention Network (MAGAT) consistently leads to higher performance when paired with an appropriate pre-training stage. Finally, we assess the importance of each component of MAGAT in our ablation studies.