 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMay the Forgetting Be with You: Alternate Replay for Learning with Noisy Labels
Aug 26, 2024Forgetting presents a significant challenge during incremental training, making it particularly demanding for contemporary AI systems to assimilate new knowledge in streaming data environments. To address this issue, most approaches in Continual Learning (CL) rely on the replay of a restricted buffer of past data. However, the presence of noise in real-world scenarios, where human annotation is constrained by time limitations or where data is automatically gathered from the web, frequently renders these strategies vulnerable. In this study, we address the problem of CL under Noisy Labels (CLN) by introducing Alternate Experience Replay (AER), which takes advantage of forgetting to maintain a clear distinction between clean, complex, and noisy samples in the memory buffer. The idea is that complex or mislabeled examples, which hardly fit the previously learned data distribution, are most likely to be forgotten. To grasp the benefits of such a separation, we equip AER with Asymmetric Balanced Sampling (ABS): a new sample selection strategy that prioritizes purity on the current task while retaining relevant samples from the past. Through extensive computational comparisons, we demonstrate the effectiveness of our approach in terms of both accuracy and purity of the obtained buffer, resulting in a remarkable average gain of 4.71% points in accuracy with respect to existing loss-based purification strategies. Code is available at https://github.com/aimagelab/mammoth.
On the impact of publicly available news and information transfer to financial markets
Oct 22, 2020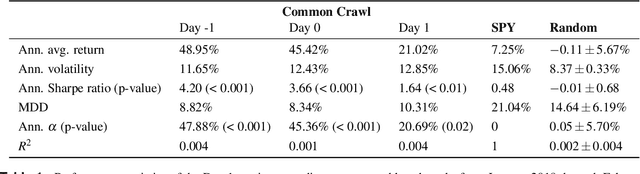
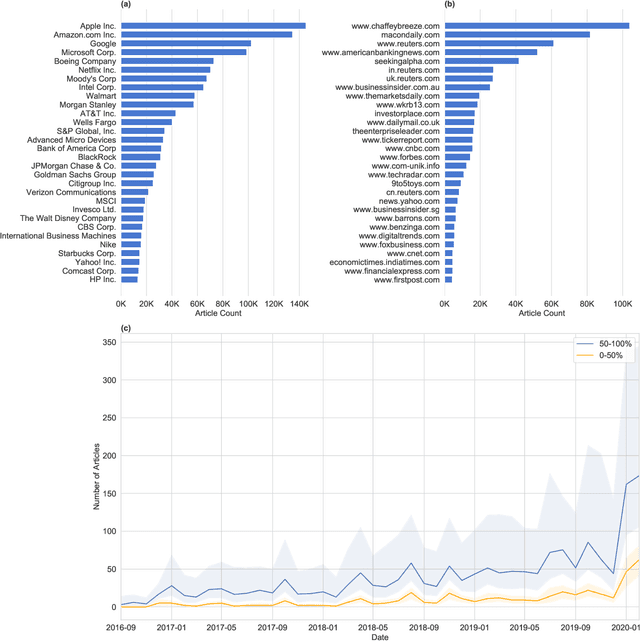
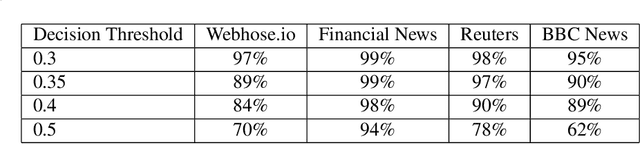
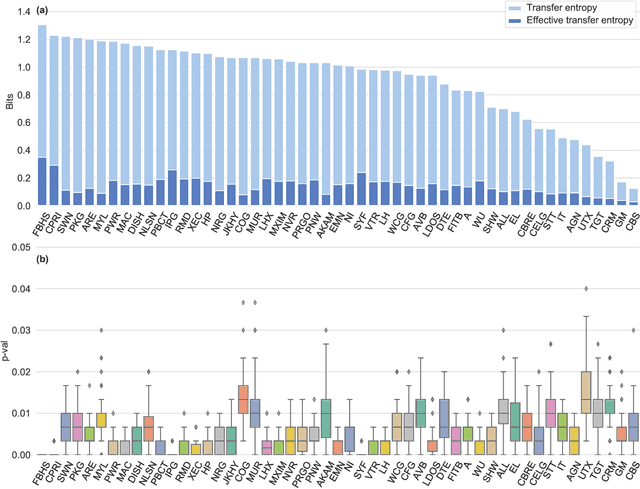
We quantify the propagation and absorption of large-scale publicly available news articles from the World Wide Web to financial markets. To extract publicly available information, we use the news archives from the Common Crawl, a nonprofit organization that crawls a large part of the web. We develop a processing pipeline to identify news articles associated with the constituent companies in the S\&P 500 index, an equity market index that measures the stock performance of U.S. companies. Using machine learning techniques, we extract sentiment scores from the Common Crawl News data and employ tools from information theory to quantify the information transfer from public news articles to the U.S. stock market. Furthermore, we analyze and quantify the economic significance of the news-based information with a simple sentiment-based portfolio trading strategy. Our findings provides support for that information in publicly available news on the World Wide Web has a statistically and economically significant impact on events in financial markets.