 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the impact of publicly available news and information transfer to financial markets
Paper and Code
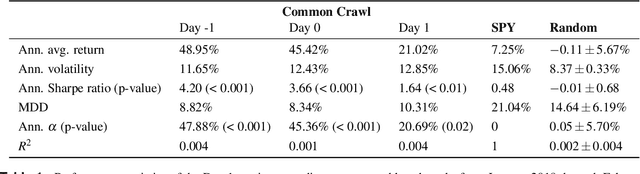
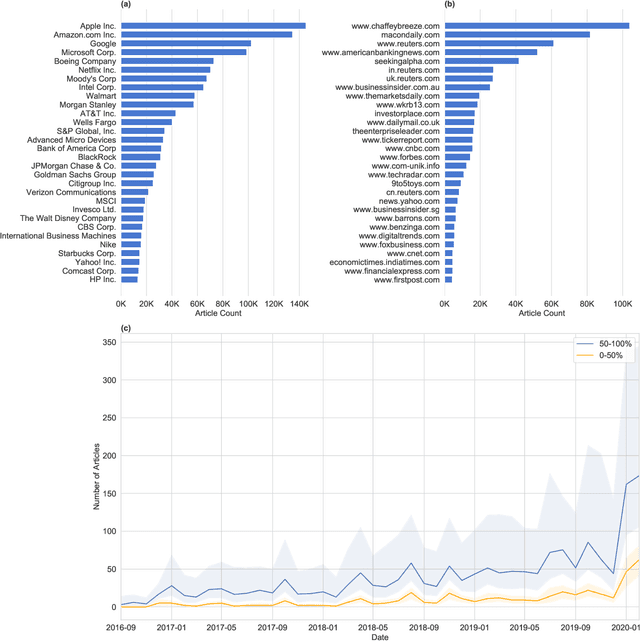
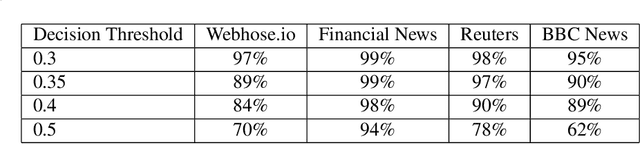
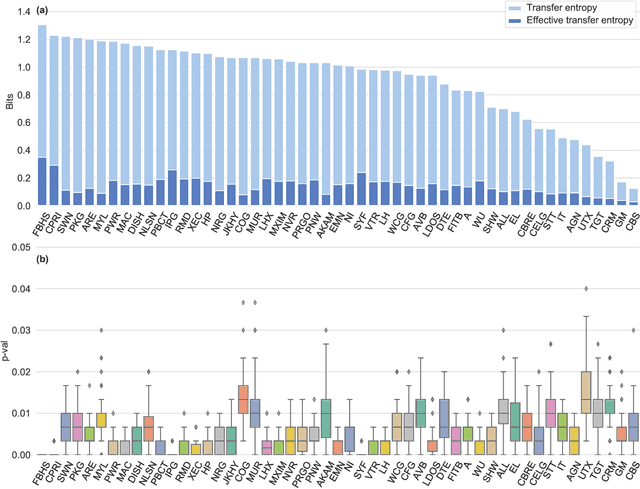
We quantify the propagation and absorption of large-scale publicly available news articles from the World Wide Web to financial markets. To extract publicly available information, we use the news archives from the Common Crawl, a nonprofit organization that crawls a large part of the web. We develop a processing pipeline to identify news articles associated with the constituent companies in the S\&P 500 index, an equity market index that measures the stock performance of U.S. companies. Using machine learning techniques, we extract sentiment scores from the Common Crawl News data and employ tools from information theory to quantify the information transfer from public news articles to the U.S. stock market. Furthermore, we analyze and quantify the economic significance of the news-based information with a simple sentiment-based portfolio trading strategy. Our findings provides support for that information in publicly available news on the World Wide Web has a statistically and economically significant impact on events in financial markets.