 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Unmasking Policies for Diffusion Language Models
Dec 12, 2025Diffusion (Large) Language Models (dLLMs) now match the downstream performance of their autoregressive counterparts on many tasks, while holding the promise of being more efficient during inference. One particularly successful variant is masked discrete diffusion, in which a buffer filled with special mask tokens is progressively replaced with tokens sampled from the model's vocabulary. Efficiency can be gained by unmasking several tokens in parallel, but doing too many at once risks degrading the generation quality. Thus, one critical design aspect of dLLMs is the sampling procedure that selects, at each step of the diffusion process, which tokens to replace. Indeed, recent work has found that heuristic strategies such as confidence thresholding lead to both higher quality and token throughput compared to random unmasking. However, such heuristics have downsides: they require manual tuning, and we observe that their performance degrades with larger buffer sizes. In this work, we instead propose to train sampling procedures using reinforcement learning. Specifically, we formalize masked diffusion sampling as a Markov decision process in which the dLLM serves as the environment, and propose a lightweight policy architecture based on a single-layer transformer that maps dLLM token confidences to unmasking decisions. Our experiments show that these trained policies match the performance of state-of-the-art heuristics when combined with semi-autoregressive generation, while outperforming them in the full diffusion setting. We also examine the transferability of these policies, finding that they can generalize to new underlying dLLMs and longer sequence lengths. However, we also observe that their performance degrades when applied to out-of-domain data, and that fine-grained tuning of the accuracy-efficiency trade-off can be challenging with our approach.
Generative Uncertainty in Diffusion Models
Feb 28, 2025



Diffusion models have recently driven significant breakthroughs in generative modeling. While state-of-the-art models produce high-quality samples on average, individual samples can still be low quality. Detecting such samples without human inspection remains a challenging task. To address this, we propose a Bayesian framework for estimating generative uncertainty of synthetic samples. We outline how to make Bayesian inference practical for large, modern generative models and introduce a new semantic likelihood (evaluated in the latent space of a feature extractor) to address the challenges posed by high-dimensional sample spaces. Through our experiments, we demonstrate that the proposed generative uncertainty effectively identifies poor-quality samples and significantly outperforms existing uncertainty-based methods. Notably, our Bayesian framework can be applied post-hoc to any pretrained diffusion or flow matching model (via the Laplace approximation), and we propose simple yet effective techniques to minimize its computational overhead during sampling.
Dynamic Vocabulary Pruning in Early-Exit LLMs
Oct 24, 2024



Increasing the size of large language models (LLMs) has been shown to lead to better performance. However, this comes at the cost of slower and more expensive inference. Early-exiting is a promising approach for improving the efficiency of LLM inference by enabling next token prediction at intermediate layers. Yet, the large vocabulary size in modern LLMs makes the confidence estimation required for exit decisions computationally expensive, diminishing the efficiency gains. To address this, we propose dynamically pruning the vocabulary at test time for each token. Specifically, the vocabulary is pruned at one of the initial layers, and the smaller vocabulary is then used throughout the rest of the forward pass. Our experiments demonstrate that such post-hoc dynamic vocabulary pruning improves the efficiency of confidence estimation in early-exit LLMs while maintaining competitive performance.
DuoDiff: Accelerating Diffusion Models with a Dual-Backbone Approach
Oct 12, 2024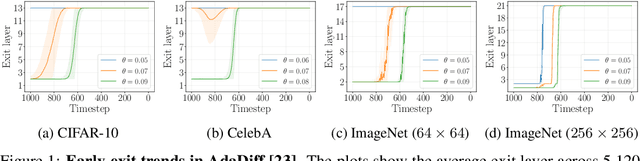
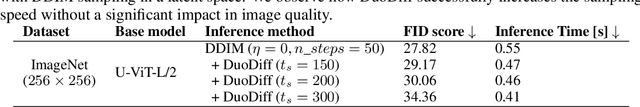
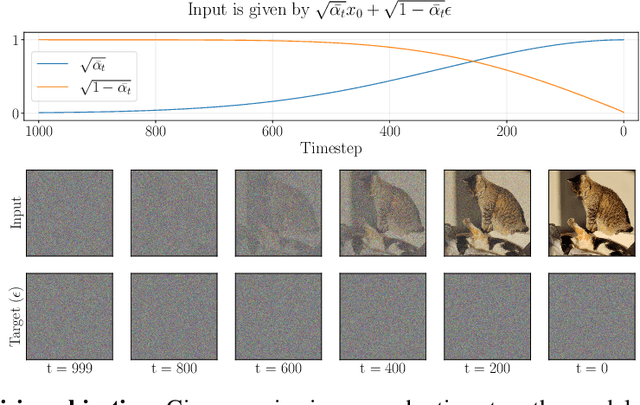
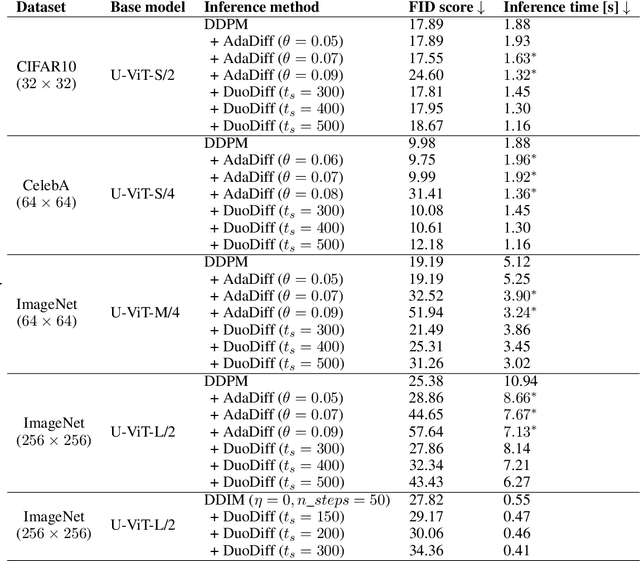
Diffusion models have achieved unprecedented performance in image generation, yet they suffer from slow inference due to their iterative sampling process. To address this, early-exiting has recently been proposed, where the depth of the denoising network is made adaptive based on the (estimated) difficulty of each sampling step. Here, we discover an interesting "phase transition" in the sampling process of current adaptive diffusion models: the denoising network consistently exits early during the initial sampling steps, until it suddenly switches to utilizing the full network. Based on this, we propose accelerating generation by employing a shallower denoising network in the initial sampling steps and a deeper network in the later steps. We demonstrate empirically that our dual-backbone approach, DuoDiff, outperforms existing early-exit diffusion methods in both inference speed and generation quality. Importantly, DuoDiff is easy to implement and complementary to existing approaches for accelerating diffusion.
Fast yet Safe: Early-Exiting with Risk Control
May 31, 2024



Scaling machine learning models significantly improves their performance. However, such gains come at the cost of inference being slow and resource-intensive. Early-exit neural networks (EENNs) offer a promising solution: they accelerate inference by allowing intermediate layers to exit and produce a prediction early. Yet a fundamental issue with EENNs is how to determine when to exit without severely degrading performance. In other words, when is it 'safe' for an EENN to go 'fast'? To address this issue, we investigate how to adapt frameworks of risk control to EENNs. Risk control offers a distribution-free, post-hoc solution that tunes the EENN's exiting mechanism so that exits only occur when the output is of sufficient quality. We empirically validate our insights on a range of vision and language tasks, demonstrating that risk control can produce substantial computational savings, all the while preserving user-specified performance goals.
Anytime-Valid Confidence Sequences for Consistent Uncertainty Estimation in Early-Exit Neural Networks
Nov 10, 2023Early-exit neural networks (EENNs) facilitate adaptive inference by producing predictions at multiple stages of the forward pass. In safety-critical applications, these predictions are only meaningful when complemented with reliable uncertainty estimates. Yet, due to their sequential structure, an EENN's uncertainty estimates should also be consistent: labels that are deemed improbable at one exit should not reappear within the confidence interval / set of later exits. We show that standard uncertainty quantification techniques, like Bayesian methods or conformal prediction, can lead to inconsistency across exits. We address this problem by applying anytime-valid confidence sequences (AVCSs) to the exits of EENNs. By design, AVCSs maintain consistency across exits. We examine the theoretical and practical challenges of applying AVCSs to EENNs and empirically validate our approach on both regression and classification tasks.
Towards Anytime Classification in Early-Exit Architectures by Enforcing Conditional Monotonicity
Jun 05, 2023Modern predictive models are often deployed to environments in which computational budgets are dynamic. Anytime algorithms are well-suited to such environments as, at any point during computation, they can output a prediction whose quality is a function of computation time. Early-exit neural networks have garnered attention in the context of anytime computation due to their capability to provide intermediate predictions at various stages throughout the network. However, we demonstrate that current early-exit networks are not directly applicable to anytime settings, as the quality of predictions for individual data points is not guaranteed to improve with longer computation. To address this shortcoming, we propose an elegant post-hoc modification, based on the Product-of-Experts, that encourages an early-exit network to become gradually confident. This gives our deep models the property of conditional monotonicity in the prediction quality -- an essential stepping stone towards truly anytime predictive modeling using early-exit architectures. Our empirical results on standard image-classification tasks demonstrate that such behaviors can be achieved while preserving competitive accuracy on average.
Factorized Gaussian Process Variational Autoencoders
Nov 14, 2020
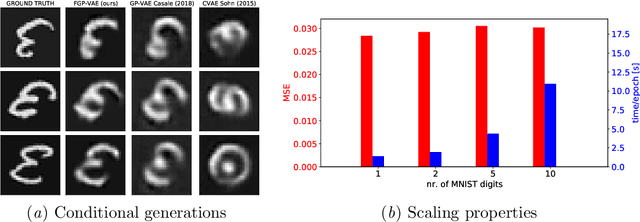


Variational autoencoders often assume isotropic Gaussian priors and mean-field posteriors, hence do not exploit structure in scenarios where we may expect similarity or consistency across latent variables. Gaussian process variational autoencoders alleviate this problem through the use of a latent Gaussian process, but lead to a cubic inference time complexity. We propose a more scalable extension of these models by leveraging the independence of the auxiliary features, which is present in many datasets. Our model factorizes the latent kernel across these features in different dimensions, leading to a significant speed-up (in theory and practice), while empirically performing comparably to existing non-scalable approaches. Moreover, our approach allows for additional modeling of global latent information and for more general extrapolation to unseen input combinations.
Scalable Gaussian Process Variational Autoencoders
Nov 12, 2020

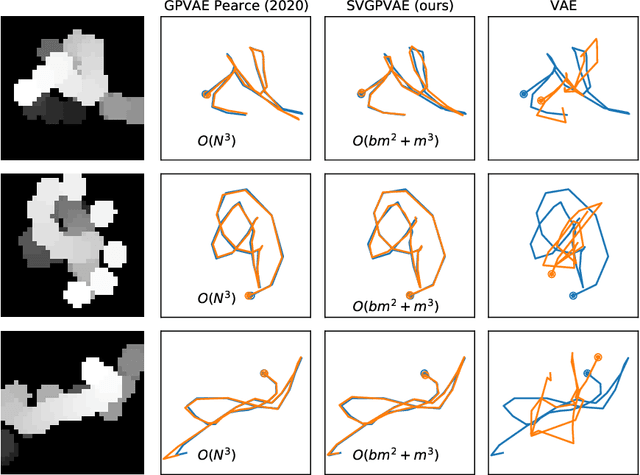
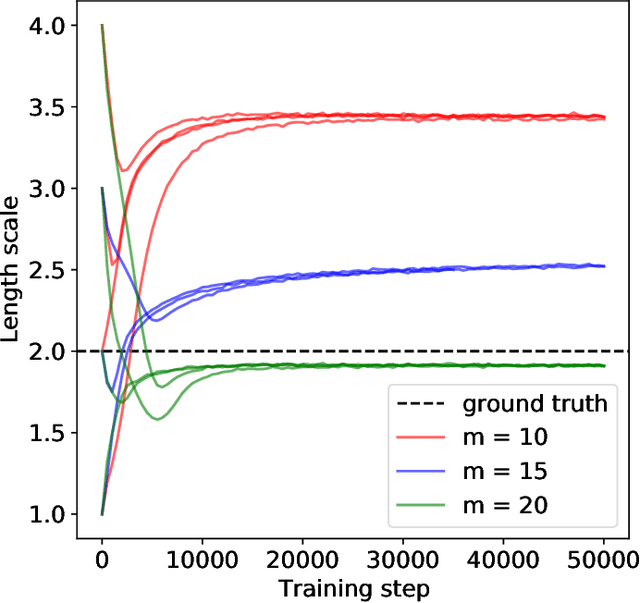
Conventional variational autoencoders fail in modeling correlations between data points due to their use of factorized priors. Amortized Gaussian process inference through GP-VAEs has led to significant improvements in this regard, but is still inhibited by the intrinsic complexity of exact GP inference. We improve the scalability of these methods through principled sparse inference approaches. We propose a new scalable GP-VAE model that outperforms existing approaches in terms of runtime and memory footprint, is easy to implement, and allows for joint end-to-end optimization of all components.
On the impact of publicly available news and information transfer to financial markets
Oct 22, 2020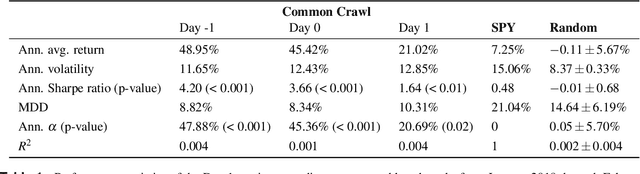
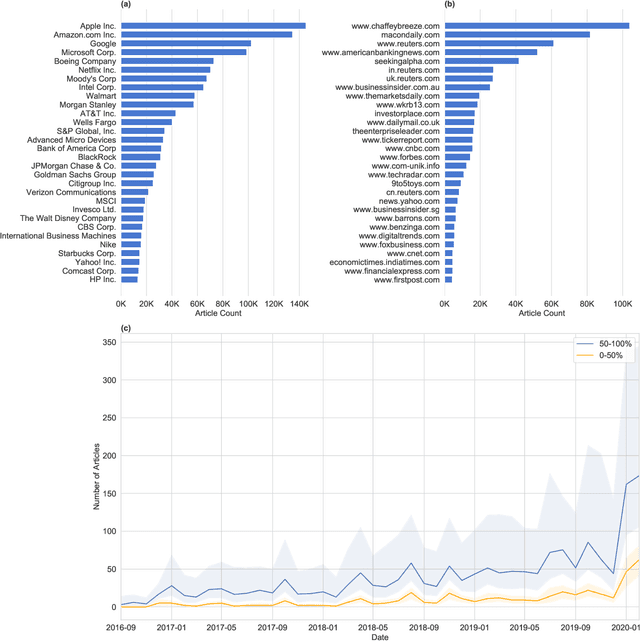
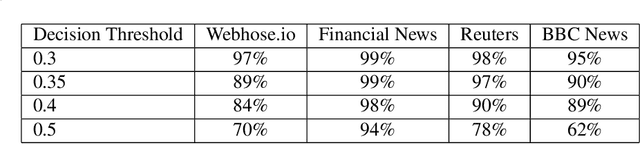
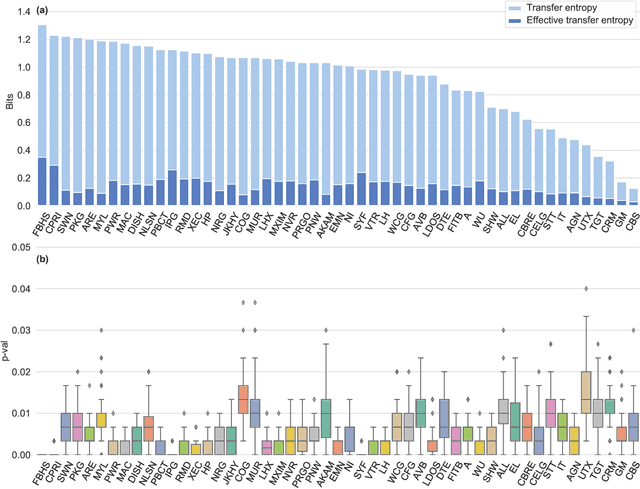
We quantify the propagation and absorption of large-scale publicly available news articles from the World Wide Web to financial markets. To extract publicly available information, we use the news archives from the Common Crawl, a nonprofit organization that crawls a large part of the web. We develop a processing pipeline to identify news articles associated with the constituent companies in the S\&P 500 index, an equity market index that measures the stock performance of U.S. companies. Using machine learning techniques, we extract sentiment scores from the Common Crawl News data and employ tools from information theory to quantify the information transfer from public news articles to the U.S. stock market. Furthermore, we analyze and quantify the economic significance of the news-based information with a simple sentiment-based portfolio trading strategy. Our findings provides support for that information in publicly available news on the World Wide Web has a statistically and economically significant impact on events in financial markets.