 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast yet Safe: Early-Exiting with Risk Control
May 31, 2024



Scaling machine learning models significantly improves their performance. However, such gains come at the cost of inference being slow and resource-intensive. Early-exit neural networks (EENNs) offer a promising solution: they accelerate inference by allowing intermediate layers to exit and produce a prediction early. Yet a fundamental issue with EENNs is how to determine when to exit without severely degrading performance. In other words, when is it 'safe' for an EENN to go 'fast'? To address this issue, we investigate how to adapt frameworks of risk control to EENNs. Risk control offers a distribution-free, post-hoc solution that tunes the EENN's exiting mechanism so that exits only occur when the output is of sufficient quality. We empirically validate our insights on a range of vision and language tasks, demonstrating that risk control can produce substantial computational savings, all the while preserving user-specified performance goals.
Adaptive Bounding Box Uncertainties via Two-Step Conformal Prediction
Mar 12, 2024



Quantifying a model's predictive uncertainty is essential for safety-critical applications such as autonomous driving. We consider quantifying such uncertainty for multi-object detection. In particular, we leverage conformal prediction to obtain uncertainty intervals with guaranteed coverage for object bounding boxes. One challenge in doing so is that bounding box predictions are conditioned on the object's class label. Thus, we develop a novel two-step conformal approach that propagates uncertainty in predicted class labels into the uncertainty intervals for the bounding boxes. This broadens the validity of our conformal coverage guarantees to include incorrectly classified objects, ensuring their usefulness when maximal safety assurances are required. Moreover, we investigate novel ensemble and quantile regression formulations to ensure the bounding box intervals are adaptive to object size, leading to a more balanced coverage across sizes. Validating our two-step approach on real-world datasets for 2D bounding box localization, we find that desired coverage levels are satisfied with actionably tight predictive uncertainty intervals.
A powerful rank-based correction to multiple testing under positive dependency
Nov 17, 2023We develop a novel multiple hypothesis testing correction with family-wise error rate (FWER) control that efficiently exploits positive dependencies between potentially correlated statistical hypothesis tests. Our proposed algorithm $\texttt{max-rank}$ is conceptually straight-forward, relying on the use of a $\max$-operator in the rank domain of computed test statistics. We compare our approach to the frequently employed Bonferroni correction, theoretically and empirically demonstrating its superiority over Bonferroni in the case of existing positive dependency, and its equivalence otherwise. Our advantage over Bonferroni increases as the number of tests rises, and we maintain high statistical power whilst ensuring FWER control. We specifically frame our algorithm in the context of parallel permutation testing, a scenario that arises in our primary application of conformal prediction, a recently popularized approach for quantifying uncertainty in complex predictive settings.
Anomaly-Aware Semantic Segmentation via Style-Aligned OoD Augmentation
Aug 19, 2023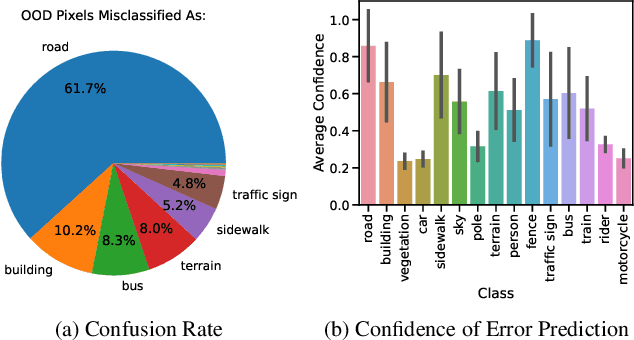
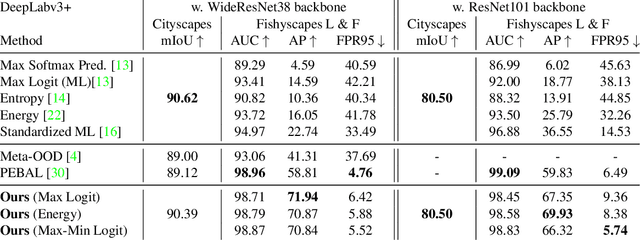

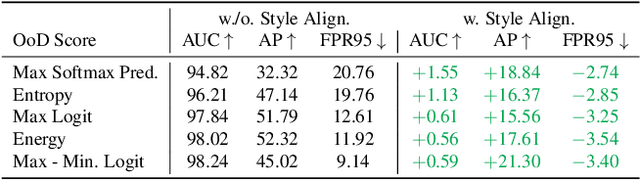
Within the context of autonomous driving, encountering unknown objects becomes inevitable during deployment in the open world. Therefore, it is crucial to equip standard semantic segmentation models with anomaly awareness. Many previous approaches have utilized synthetic out-of-distribution (OoD) data augmentation to tackle this problem. In this work, we advance the OoD synthesis process by reducing the domain gap between the OoD data and driving scenes, effectively mitigating the style difference that might otherwise act as an obvious shortcut during training. Additionally, we propose a simple fine-tuning loss that effectively induces a pre-trained semantic segmentation model to generate a ``none of the given classes" prediction, leveraging per-pixel OoD scores for anomaly segmentation. With minimal fine-tuning effort, our pipeline enables the use of pre-trained models for anomaly segmentation while maintaining the performance on the original task.
Certified Defences Against Adversarial Patch Attacks on Semantic Segmentation
Sep 13, 2022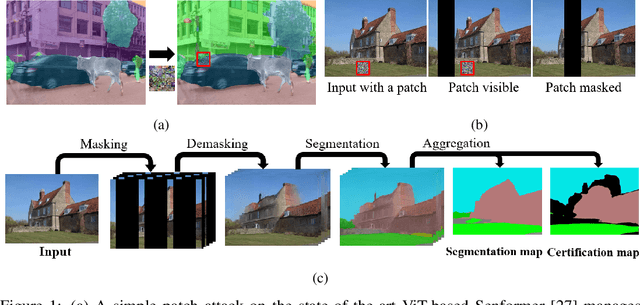
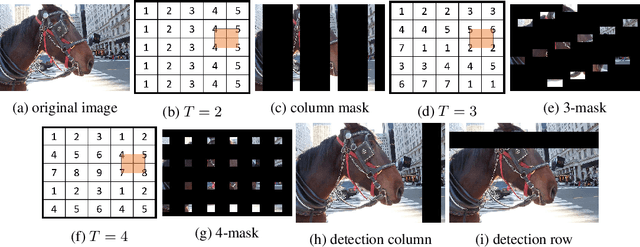
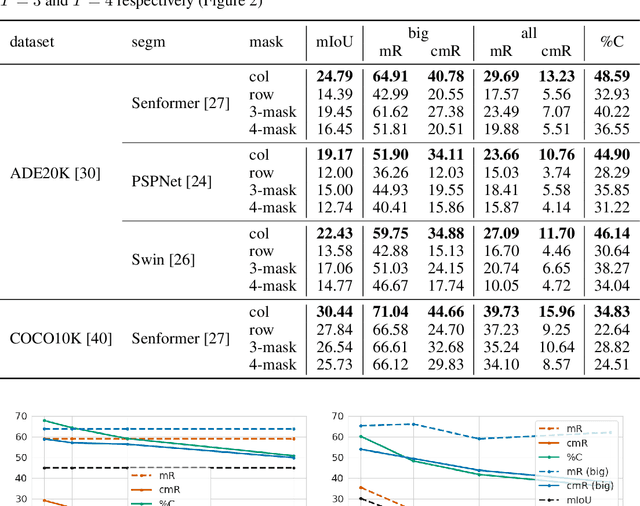

Adversarial patch attacks are an emerging security threat for real world deep learning applications. We present Demasked Smoothing, the first approach (up to our knowledge) to certify the robustness of semantic segmentation models against this threat model. Previous work on certifiably defending against patch attacks has mostly focused on image classification task and often required changes in the model architecture and additional training which is undesirable and computationally expensive. In Demasked Smoothing, any segmentation model can be applied without particular training, fine-tuning, or restriction of the architecture. Using different masking strategies, Demasked Smoothing can be applied both for certified detection and certified recovery. In extensive experiments we show that Demasked Smoothing can on average certify 64% of the pixel predictions for a 1% patch in the detection task and 48% against a 0.5% patch for the recovery task on the ADE20K dataset.