 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly-Aware Semantic Segmentation via Style-Aligned OoD Augmentation
Paper and Code
Aug 19, 2023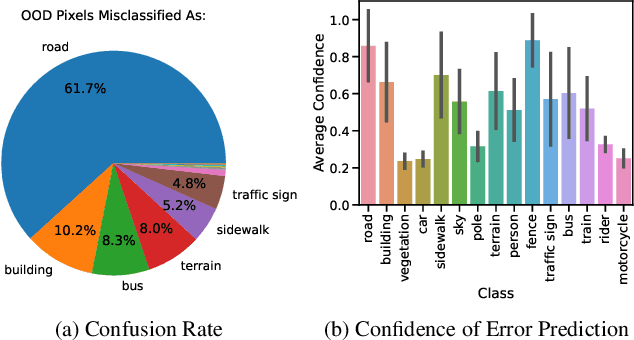
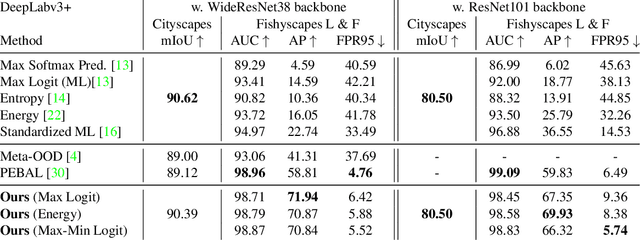

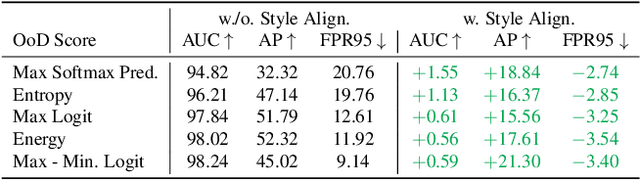
Within the context of autonomous driving, encountering unknown objects becomes inevitable during deployment in the open world. Therefore, it is crucial to equip standard semantic segmentation models with anomaly awareness. Many previous approaches have utilized synthetic out-of-distribution (OoD) data augmentation to tackle this problem. In this work, we advance the OoD synthesis process by reducing the domain gap between the OoD data and driving scenes, effectively mitigating the style difference that might otherwise act as an obvious shortcut during training. Additionally, we propose a simple fine-tuning loss that effectively induces a pre-trained semantic segmentation model to generate a ``none of the given classes" prediction, leveraging per-pixel OoD scores for anomaly segmentation. With minimal fine-tuning effort, our pipeline enables the use of pre-trained models for anomaly segmentation while maintaining the performance on the original task.