 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSTAR: Generative Temporal Nursing for Longer Dynamic Video Synthesis
Mar 20, 2024Despite tremendous progress in the field of text-to-video (T2V) synthesis, open-sourced T2V diffusion models struggle to generate longer videos with dynamically varying and evolving content. They tend to synthesize quasi-static videos, ignoring the necessary visual change-over-time implied in the text prompt. At the same time, scaling these models to enable longer, more dynamic video synthesis often remains computationally intractable. To address this challenge, we introduce the concept of Generative Temporal Nursing (GTN), where we aim to alter the generative process on the fly during inference to improve control over the temporal dynamics and enable generation of longer videos. We propose a method for GTN, dubbed VSTAR, which consists of two key ingredients: 1) Video Synopsis Prompting (VSP) - automatic generation of a video synopsis based on the original single prompt leveraging LLMs, which gives accurate textual guidance to different visual states of longer videos, and 2) Temporal Attention Regularization (TAR) - a regularization technique to refine the temporal attention units of the pre-trained T2V diffusion models, which enables control over the video dynamics. We experimentally showcase the superiority of the proposed approach in generating longer, visually appealing videos over existing open-sourced T2V models. We additionally analyze the temporal attention maps realized with and without VSTAR, demonstrating the importance of applying our method to mitigate neglect of the desired visual change over time.
Anomaly-Aware Semantic Segmentation via Style-Aligned OoD Augmentation
Aug 19, 2023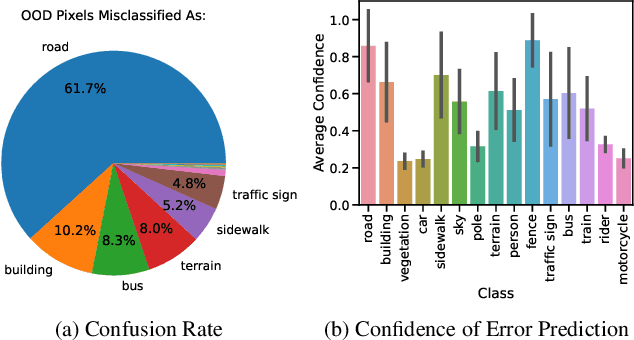
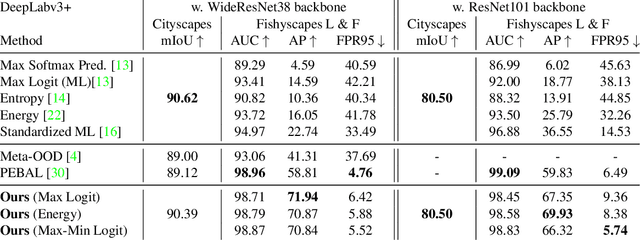

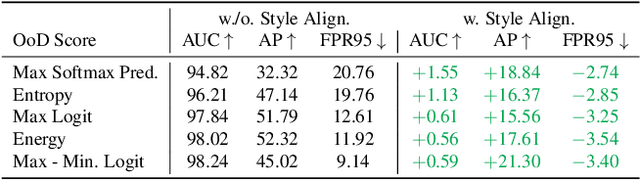
Within the context of autonomous driving, encountering unknown objects becomes inevitable during deployment in the open world. Therefore, it is crucial to equip standard semantic segmentation models with anomaly awareness. Many previous approaches have utilized synthetic out-of-distribution (OoD) data augmentation to tackle this problem. In this work, we advance the OoD synthesis process by reducing the domain gap between the OoD data and driving scenes, effectively mitigating the style difference that might otherwise act as an obvious shortcut during training. Additionally, we propose a simple fine-tuning loss that effectively induces a pre-trained semantic segmentation model to generate a ``none of the given classes" prediction, leveraging per-pixel OoD scores for anomaly segmentation. With minimal fine-tuning effort, our pipeline enables the use of pre-trained models for anomaly segmentation while maintaining the performance on the original task.
Improving Uncertainty of Deep Learning-based Object Classification on Radar Spectra using Label Smoothing
Sep 27, 2021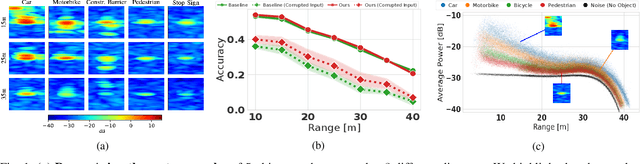
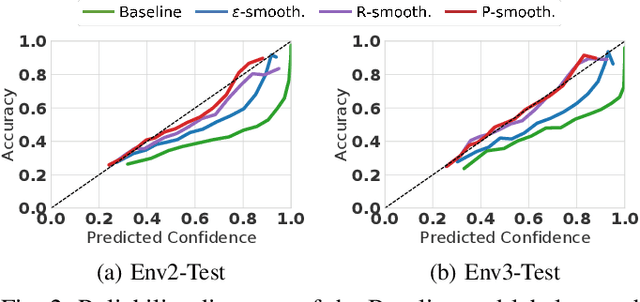
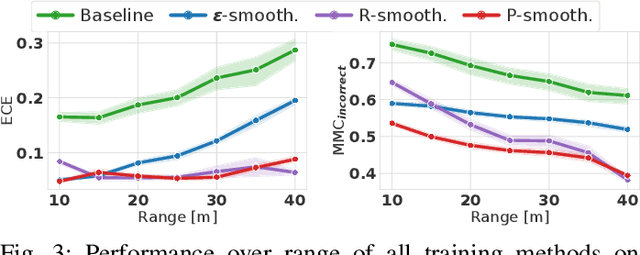
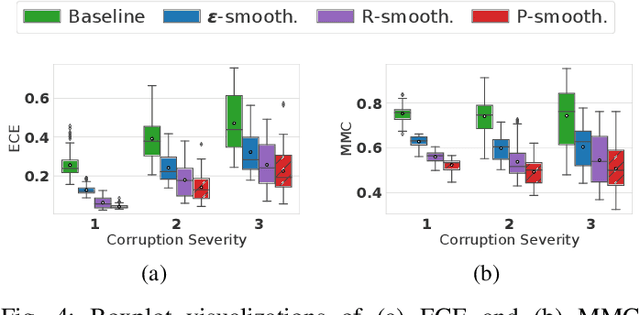
Object type classification for automotive radar has greatly improved with recent deep learning (DL) solutions, however these developments have mostly focused on the classification accuracy. Before employing DL solutions in safety-critical applications, such as automated driving, an indispensable prerequisite is the accurate quantification of the classifiers' reliability. Unfortunately, DL classifiers are characterized as black-box systems which output severely over-confident predictions, leading downstream decision-making systems to false conclusions with possibly catastrophic consequences. We find that deep radar classifiers maintain high-confidences for ambiguous, difficult samples, e.g. small objects measured at large distances, under domain shift and signal corruptions, regardless of the correctness of the predictions. The focus of this article is to learn deep radar spectra classifiers which offer robust real-time uncertainty estimates using label smoothing during training. Label smoothing is a technique of refining, or softening, the hard labels typically available in classification datasets. In this article, we exploit radar-specific know-how to define soft labels which encourage the classifiers to learn to output high-quality calibrated uncertainty estimates, thereby partially resolving the problem of over-confidence. Our investigations show how simple radar knowledge can easily be combined with complex data-driven learning algorithms to yield safe automotive radar perception.
DiagViB-6: A Diagnostic Benchmark Suite for Vision Models in the Presence of Shortcut and Generalization Opportunities
Aug 12, 2021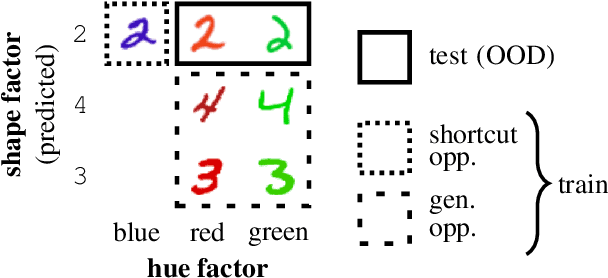


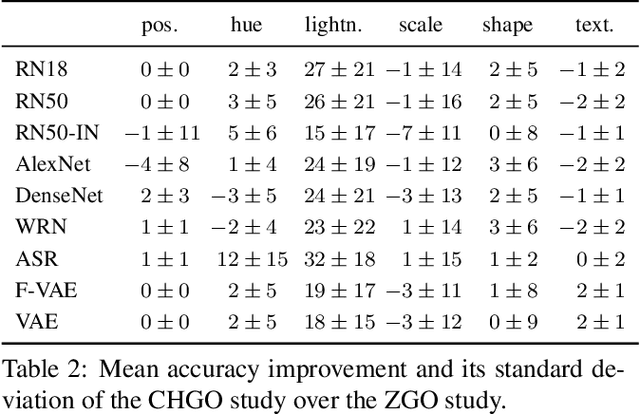
Common deep neural networks (DNNs) for image classification have been shown to rely on shortcut opportunities (SO) in the form of predictive and easy-to-represent visual factors. This is known as shortcut learning and leads to impaired generalization. In this work, we show that common DNNs also suffer from shortcut learning when predicting only basic visual object factors of variation (FoV) such as shape, color, or texture. We argue that besides shortcut opportunities, generalization opportunities (GO) are also an inherent part of real-world vision data and arise from partial independence between predicted classes and FoVs. We also argue that it is necessary for DNNs to exploit GO to overcome shortcut learning. Our core contribution is to introduce the Diagnostic Vision Benchmark suite DiagViB-6, which includes datasets and metrics to study a network's shortcut vulnerability and generalization capability for six independent FoV. In particular, DiagViB-6 allows controlling the type and degree of SO and GO in a dataset. We benchmark a wide range of popular vision architectures and show that they can exploit GO only to a limited extent.
Investigation of Uncertainty of Deep Learning-based Object Classification on Radar Spectra
Jun 01, 2021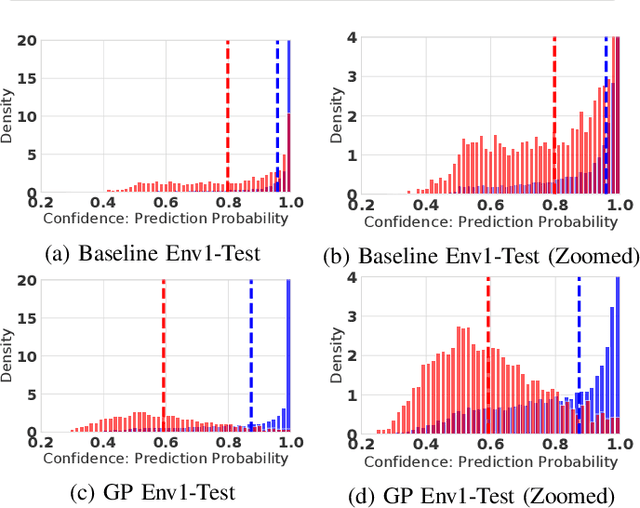
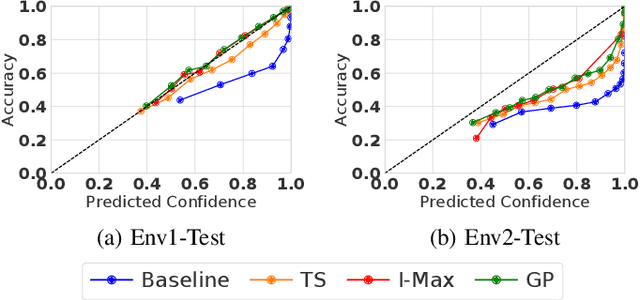
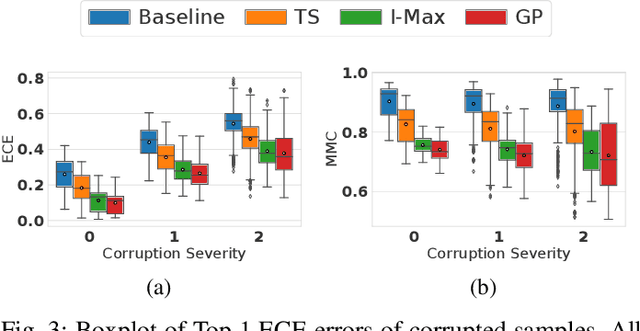

Deep learning (DL) has recently attracted increasing interest to improve object type classification for automotive radar.In addition to high accuracy, it is crucial for decision making in autonomous vehicles to evaluate the reliability of the predictions; however, decisions of DL networks are non-transparent. Current DL research has investigated how uncertainties of predictions can be quantified, and in this article, we evaluate the potential of these methods for safe, automotive radar perception. In particular we evaluate how uncertainty quantification can support radar perception under (1) domain shift, (2) corruptions of input signals, and (3) in the presence of unknown objects. We find that in agreement with phenomena observed in the literature,deep radar classifiers are overly confident, even in their wrong predictions. This raises concerns about the use of the confidence values for decision making under uncertainty, as the model fails to notify when it cannot handle an unknown situation. Accurate confidence values would allow optimal integration of multiple information sources, e.g. via sensor fusion. We show that by applying state-of-the-art post-hoc uncertainty calibration, the quality of confidence measures can be significantly improved,thereby partially resolving the over-confidence problem. Our investigation shows that further research into training and calibrating DL networks is necessary and offers great potential for safe automotive object classification with radar sensors.
* 6 pages
Multi-Class Uncertainty Calibration via Mutual Information Maximization-based Binning
Jun 23, 2020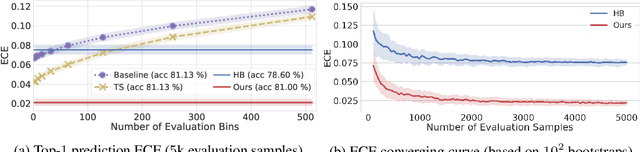
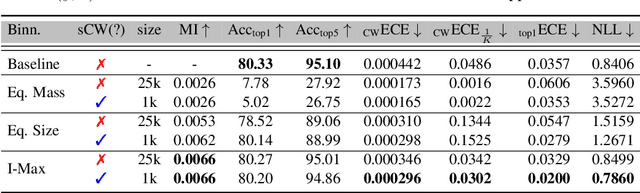
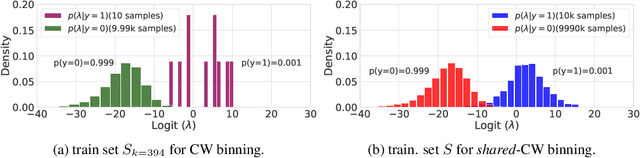
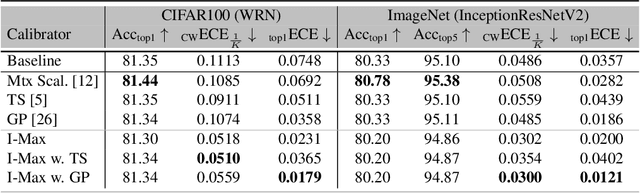
Post-hoc calibration is a common approach for providing high-quality confidence estimates of deep neural network predictions. Recent work has shown that widely used scaling methods underestimate their calibration error, while alternative Histogram Binning (HB) methods with verifiable calibration performance often fail to preserve classification accuracy. In the case of multi-class calibration with a large number of classes K, HB also faces the issue of severe sample-inefficiency due to a large class imbalance resulting from the conversion into K one-vs-rest class-wise calibration problems. The goal of this paper is to resolve the identified issues of HB in order to provide verified and calibrated confidence estimates using only a small holdout calibration dataset for bin optimization while preserving multi-class ranking accuracy. From an information-theoretic perspective, we derive the I-Max concept for binning, which maximizes the mutual information between labels and binned (quantized) logits. This concept mitigates potential loss in ranking performance due to lossy quantization, and by disentangling the optimization of bin edges and representatives allows simultaneous improvement of ranking and calibration performance. In addition, we propose a shared class-wise (sCW) binning strategy that fits a single calibrator on the merged training sets of all K class-wise problems, yielding reliable estimates from a small calibration set. The combination of sCW and I-Max binning outperforms the state of the art calibration methods on various evaluation metrics across different benchmark datasets and models, even when using only a small set of calibration data, e.g. 1k samples for ImageNet.
On-manifold Adversarial Data Augmentation Improves Uncertainty Calibration
Dec 16, 2019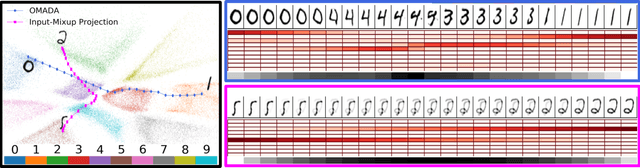
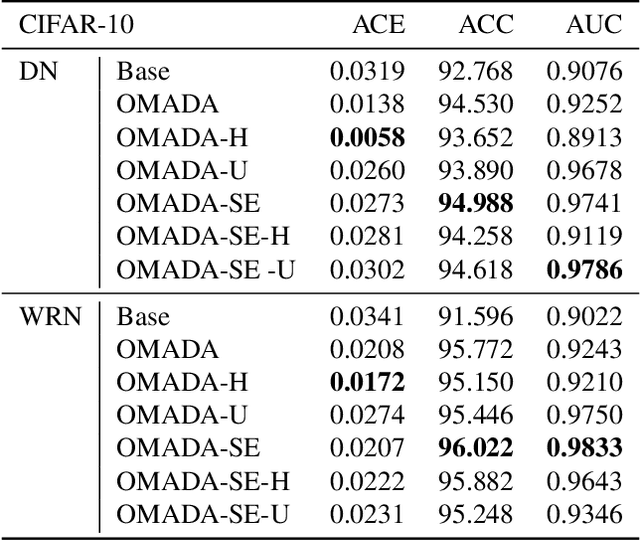
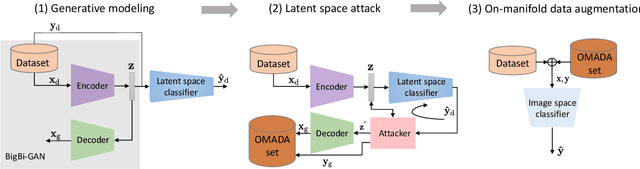
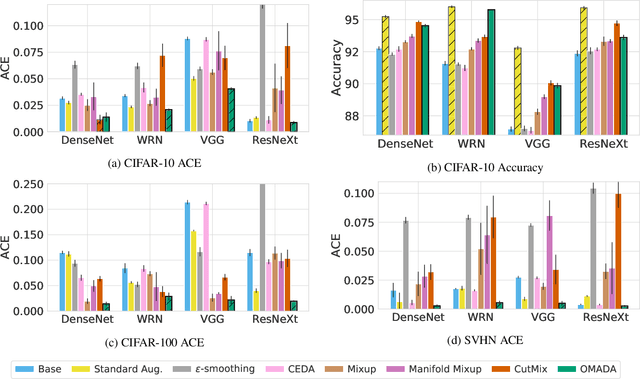
Uncertainty estimates help to identify ambiguous, novel, or anomalous inputs, but the reliable quantification of uncertainty has proven to be challenging for modern deep networks. To improve uncertainty estimation, we propose On-Manifold Adversarial Data Augmentation or OMADA, which specifically attempts to generate the most challenging examples by following an on-manifold adversarial attack path in the latent space of an autoencoder-based generative model that closely approximates decision boundaries between two or more classes. On a variety of datasets and for multiple network architectures, OMADA consistently yields more accurate and better calibrated classifiers than baseline models, and outperforms competing approaches such as Mixup and CutMix, as well as achieving similar performance to (at times better than) post-processing calibration methods such as temperature scaling. Variants of OMADA can employ different sampling schemes for ambiguous on-manifold examples based on the entropy of their estimated soft labels, which exhibit specific strengths for generalization, calibration of predicted uncertainty, or detection of out-of-distribution inputs.