 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Class Uncertainty Calibration via Mutual Information Maximization-based Binning
Paper and Code
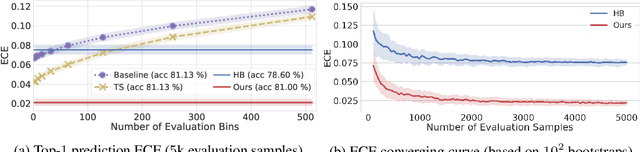
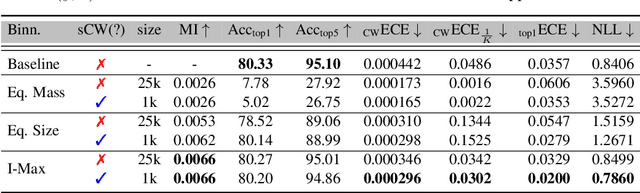
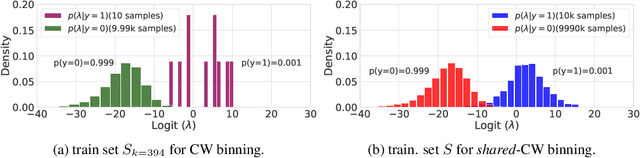
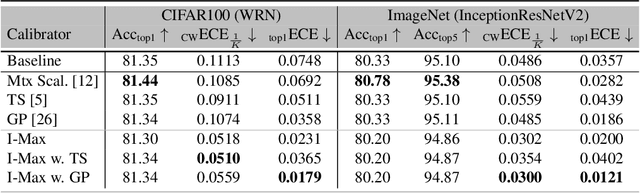
Post-hoc calibration is a common approach for providing high-quality confidence estimates of deep neural network predictions. Recent work has shown that widely used scaling methods underestimate their calibration error, while alternative Histogram Binning (HB) methods with verifiable calibration performance often fail to preserve classification accuracy. In the case of multi-class calibration with a large number of classes K, HB also faces the issue of severe sample-inefficiency due to a large class imbalance resulting from the conversion into K one-vs-rest class-wise calibration problems. The goal of this paper is to resolve the identified issues of HB in order to provide verified and calibrated confidence estimates using only a small holdout calibration dataset for bin optimization while preserving multi-class ranking accuracy. From an information-theoretic perspective, we derive the I-Max concept for binning, which maximizes the mutual information between labels and binned (quantized) logits. This concept mitigates potential loss in ranking performance due to lossy quantization, and by disentangling the optimization of bin edges and representatives allows simultaneous improvement of ranking and calibration performance. In addition, we propose a shared class-wise (sCW) binning strategy that fits a single calibrator on the merged training sets of all K class-wise problems, yielding reliable estimates from a small calibration set. The combination of sCW and I-Max binning outperforms the state of the art calibration methods on various evaluation metrics across different benchmark datasets and models, even when using only a small set of calibration data, e.g. 1k samples for ImageNet.