 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid SNN-ANN: Energy-Efficient Classification and Object Detection for Event-Based Vision
Dec 06, 2021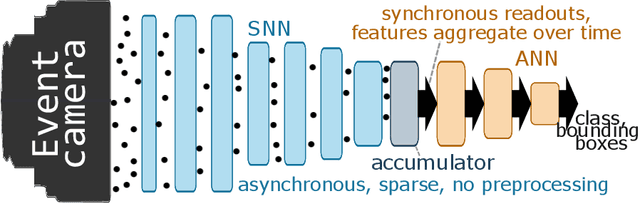
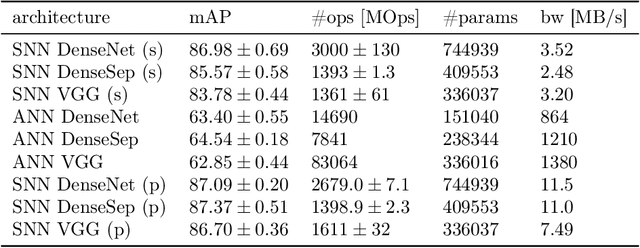
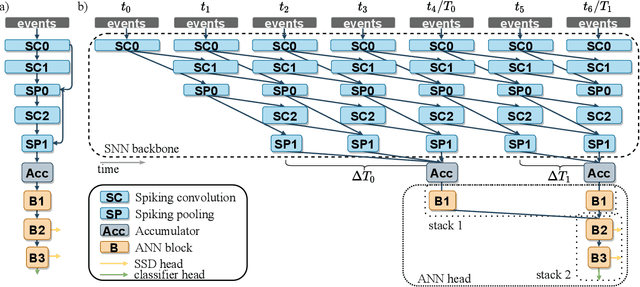
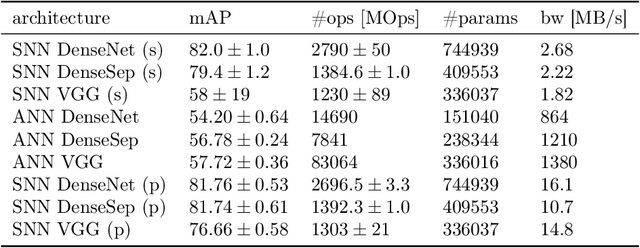
Event-based vision sensors encode local pixel-wise brightness changes in streams of events rather than image frames and yield sparse, energy-efficient encodings of scenes, in addition to low latency, high dynamic range, and lack of motion blur. Recent progress in object recognition from event-based sensors has come from conversions of deep neural networks, trained with backpropagation. However, using these approaches for event streams requires a transformation to a synchronous paradigm, which not only loses computational efficiency, but also misses opportunities to extract spatio-temporal features. In this article we propose a hybrid architecture for end-to-end training of deep neural networks for event-based pattern recognition and object detection, combining a spiking neural network (SNN) backbone for efficient event-based feature extraction, and a subsequent analog neural network (ANN) head to solve synchronous classification and detection tasks. This is achieved by combining standard backpropagation with surrogate gradient training to propagate gradients through the SNN. Hybrid SNN-ANNs can be trained without conversion, and result in highly accurate networks that are substantially more computationally efficient than their ANN counterparts. We demonstrate results on event-based classification and object detection datasets, in which only the architecture of the ANN heads need to be adapted to the tasks, and no conversion of the event-based input is necessary. Since ANNs and SNNs require different hardware paradigms to maximize their efficiency, we envision that SNN backbone and ANN head can be executed on different processing units, and thus analyze the necessary bandwidth to communicate between the two parts. Hybrid networks are promising architectures to further advance machine learning approaches for event-based vision, without having to compromise on efficiency.
Improving Uncertainty of Deep Learning-based Object Classification on Radar Spectra using Label Smoothing
Sep 27, 2021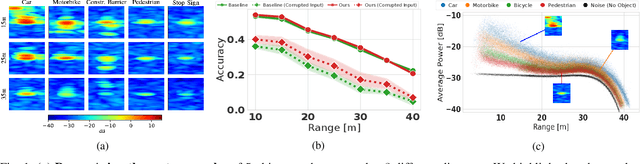
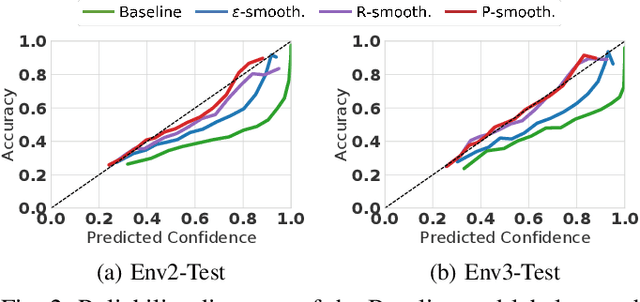
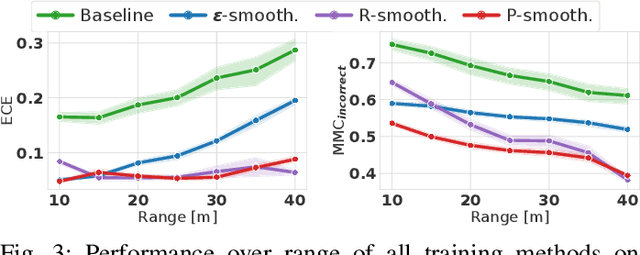
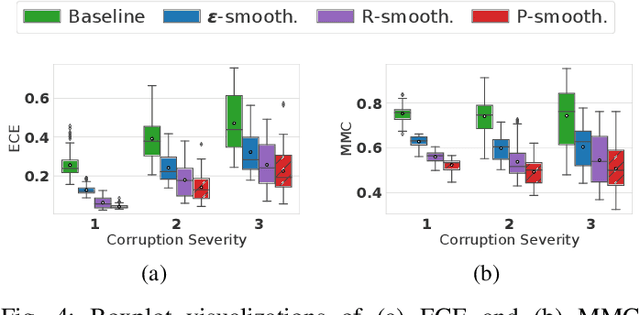
Object type classification for automotive radar has greatly improved with recent deep learning (DL) solutions, however these developments have mostly focused on the classification accuracy. Before employing DL solutions in safety-critical applications, such as automated driving, an indispensable prerequisite is the accurate quantification of the classifiers' reliability. Unfortunately, DL classifiers are characterized as black-box systems which output severely over-confident predictions, leading downstream decision-making systems to false conclusions with possibly catastrophic consequences. We find that deep radar classifiers maintain high-confidences for ambiguous, difficult samples, e.g. small objects measured at large distances, under domain shift and signal corruptions, regardless of the correctness of the predictions. The focus of this article is to learn deep radar spectra classifiers which offer robust real-time uncertainty estimates using label smoothing during training. Label smoothing is a technique of refining, or softening, the hard labels typically available in classification datasets. In this article, we exploit radar-specific know-how to define soft labels which encourage the classifiers to learn to output high-quality calibrated uncertainty estimates, thereby partially resolving the problem of over-confidence. Our investigations show how simple radar knowledge can easily be combined with complex data-driven learning algorithms to yield safe automotive radar perception.
Investigation of Uncertainty of Deep Learning-based Object Classification on Radar Spectra
Jun 01, 2021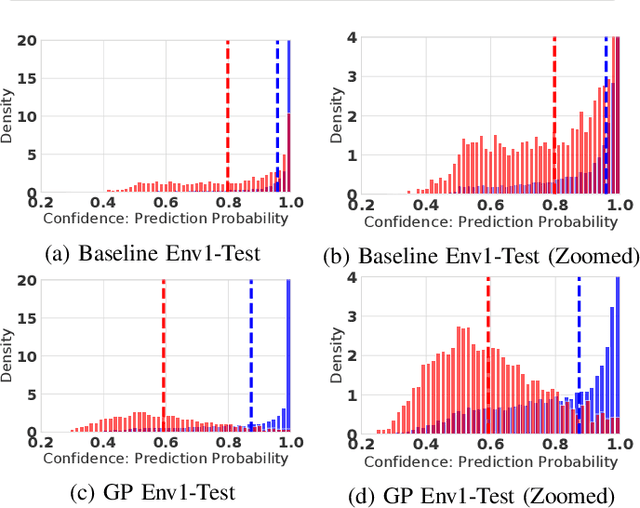
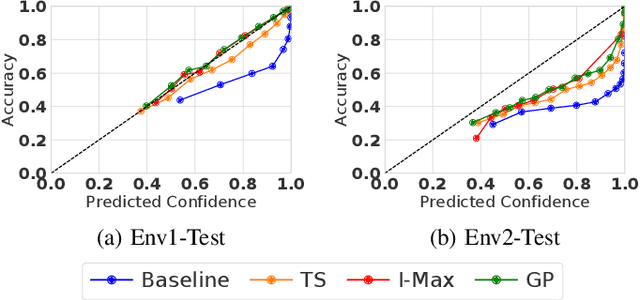
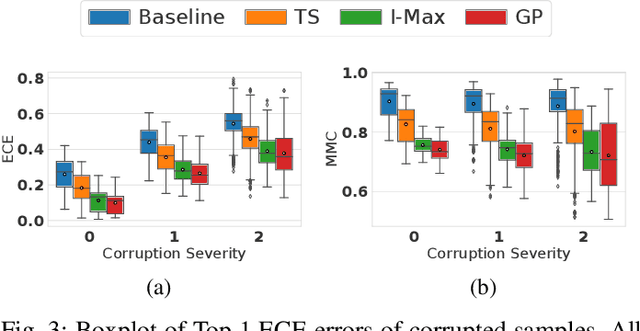

Deep learning (DL) has recently attracted increasing interest to improve object type classification for automotive radar.In addition to high accuracy, it is crucial for decision making in autonomous vehicles to evaluate the reliability of the predictions; however, decisions of DL networks are non-transparent. Current DL research has investigated how uncertainties of predictions can be quantified, and in this article, we evaluate the potential of these methods for safe, automotive radar perception. In particular we evaluate how uncertainty quantification can support radar perception under (1) domain shift, (2) corruptions of input signals, and (3) in the presence of unknown objects. We find that in agreement with phenomena observed in the literature,deep radar classifiers are overly confident, even in their wrong predictions. This raises concerns about the use of the confidence values for decision making under uncertainty, as the model fails to notify when it cannot handle an unknown situation. Accurate confidence values would allow optimal integration of multiple information sources, e.g. via sensor fusion. We show that by applying state-of-the-art post-hoc uncertainty calibration, the quality of confidence measures can be significantly improved,thereby partially resolving the over-confidence problem. Our investigation shows that further research into training and calibrating DL networks is necessary and offers great potential for safe automotive object classification with radar sensors.
* 6 pages
Bosch Deep Learning Hardware Benchmark
Aug 24, 2020

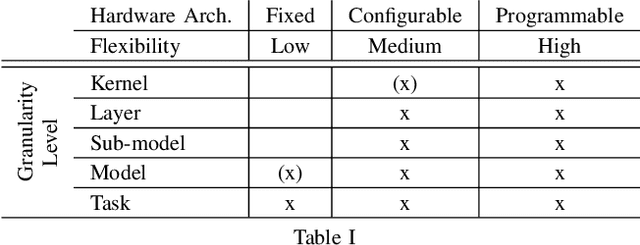

The widespread use of Deep Learning (DL) applications in science and industry has created a large demand for efficient inference systems. This has resulted in a rapid increase of available Hardware Accelerators (HWAs) making comparison challenging and laborious. To address this, several DL hardware benchmarks have been proposed aiming at a comprehensive comparison for many models, tasks, and hardware platforms. Here, we present our DL hardware benchmark which has been specifically developed for inference on embedded HWAs and tasks required for autonomous driving. In addition to previous benchmarks, we propose a new granularity level to evaluate common submodules of DL models, a twofold benchmark procedure that accounts for hardware and model optimizations done by HWA manufacturers, and an extended set of performance indicators that can help to identify a mismatch between a HWA and the DL models used in our benchmark.
Multi-Class Uncertainty Calibration via Mutual Information Maximization-based Binning
Jun 23, 2020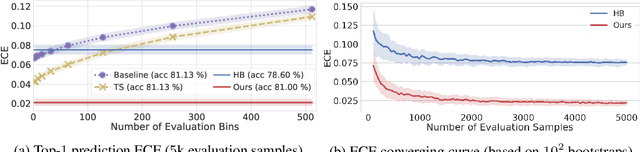
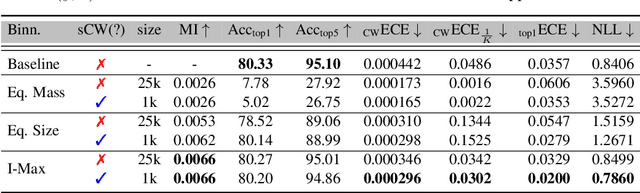
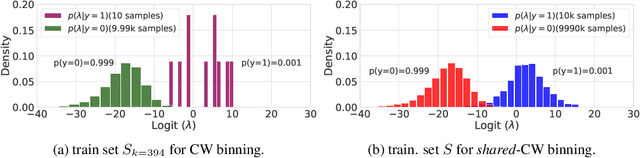
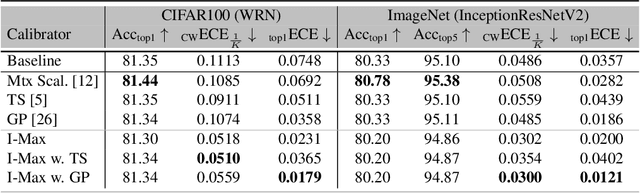
Post-hoc calibration is a common approach for providing high-quality confidence estimates of deep neural network predictions. Recent work has shown that widely used scaling methods underestimate their calibration error, while alternative Histogram Binning (HB) methods with verifiable calibration performance often fail to preserve classification accuracy. In the case of multi-class calibration with a large number of classes K, HB also faces the issue of severe sample-inefficiency due to a large class imbalance resulting from the conversion into K one-vs-rest class-wise calibration problems. The goal of this paper is to resolve the identified issues of HB in order to provide verified and calibrated confidence estimates using only a small holdout calibration dataset for bin optimization while preserving multi-class ranking accuracy. From an information-theoretic perspective, we derive the I-Max concept for binning, which maximizes the mutual information between labels and binned (quantized) logits. This concept mitigates potential loss in ranking performance due to lossy quantization, and by disentangling the optimization of bin edges and representatives allows simultaneous improvement of ranking and calibration performance. In addition, we propose a shared class-wise (sCW) binning strategy that fits a single calibrator on the merged training sets of all K class-wise problems, yielding reliable estimates from a small calibration set. The combination of sCW and I-Max binning outperforms the state of the art calibration methods on various evaluation metrics across different benchmark datasets and models, even when using only a small set of calibration data, e.g. 1k samples for ImageNet.
On-manifold Adversarial Data Augmentation Improves Uncertainty Calibration
Dec 16, 2019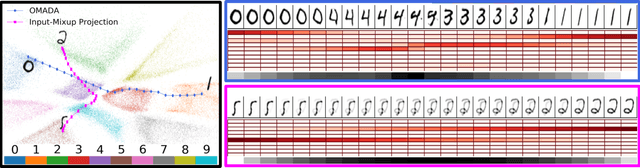
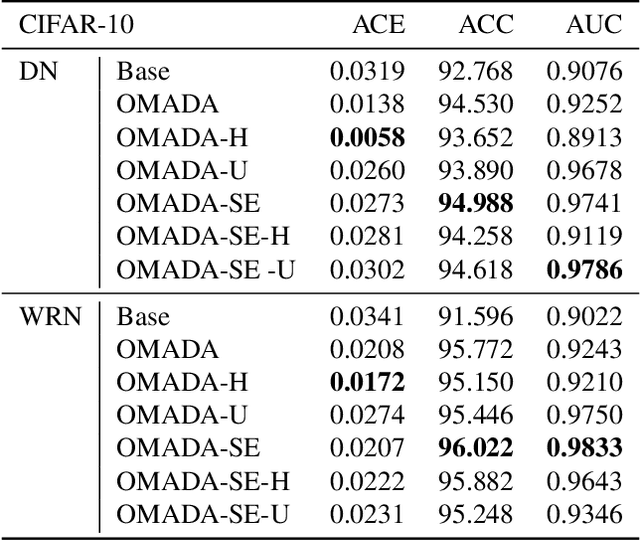
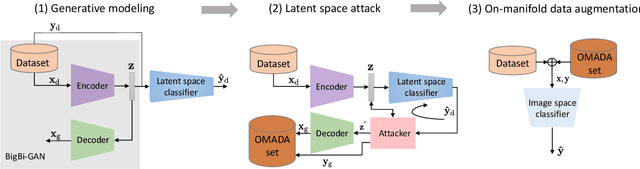
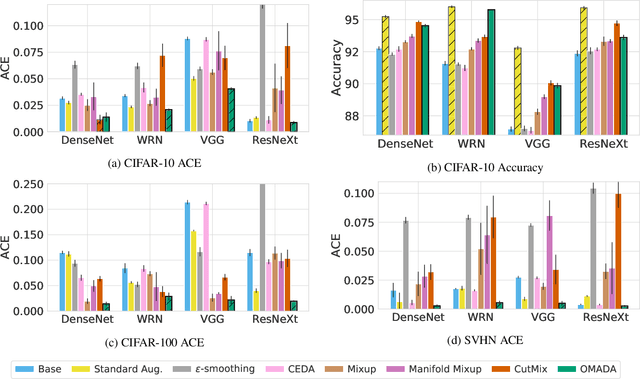
Uncertainty estimates help to identify ambiguous, novel, or anomalous inputs, but the reliable quantification of uncertainty has proven to be challenging for modern deep networks. To improve uncertainty estimation, we propose On-Manifold Adversarial Data Augmentation or OMADA, which specifically attempts to generate the most challenging examples by following an on-manifold adversarial attack path in the latent space of an autoencoder-based generative model that closely approximates decision boundaries between two or more classes. On a variety of datasets and for multiple network architectures, OMADA consistently yields more accurate and better calibrated classifiers than baseline models, and outperforms competing approaches such as Mixup and CutMix, as well as achieving similar performance to (at times better than) post-processing calibration methods such as temperature scaling. Variants of OMADA can employ different sampling schemes for ambiguous on-manifold examples based on the entropy of their estimated soft labels, which exhibit specific strengths for generalization, calibration of predicted uncertainty, or detection of out-of-distribution inputs.
Robust Anomaly Detection in Images using Adversarial Autoencoders
Jan 18, 2019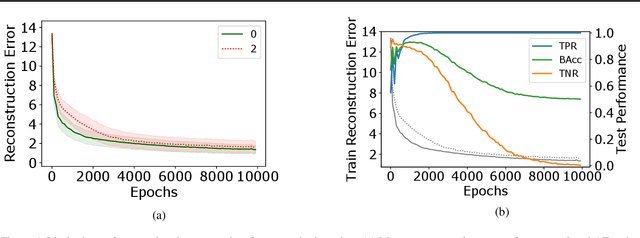
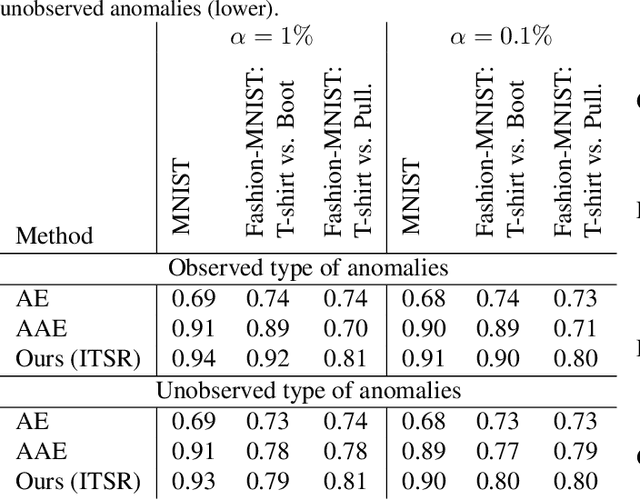
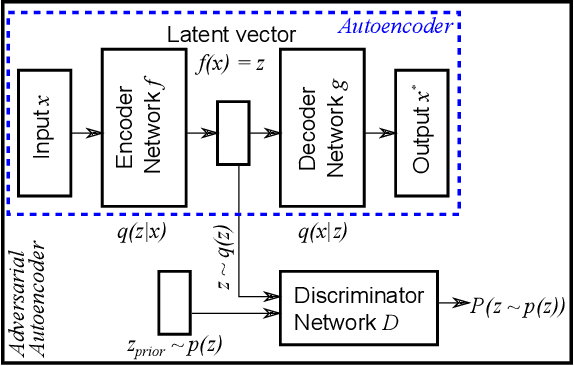
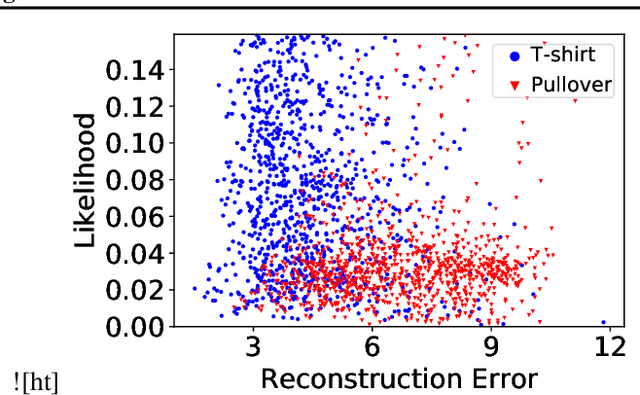
Reliably detecting anomalies in a given set of images is a task of high practical relevance for visual quality inspection, surveillance, or medical image analysis. Autoencoder neural networks learn to reconstruct normal images, and hence can classify those images as anomalies, where the reconstruction error exceeds some threshold. Here we analyze a fundamental problem of this approach when the training set is contaminated with a small fraction of outliers. We find that continued training of autoencoders inevitably reduces the reconstruction error of outliers, and hence degrades the anomaly detection performance. In order to counteract this effect, an adversarial autoencoder architecture is adapted, which imposes a prior distribution on the latent representation, typically placing anomalies into low likelihood-regions. Utilizing the likelihood model, potential anomalies can be identified and rejected already during training, which results in an anomaly detector that is significantly more robust to the presence of outliers during training.
Data-driven Summarization of Scientific Articles
Apr 24, 2018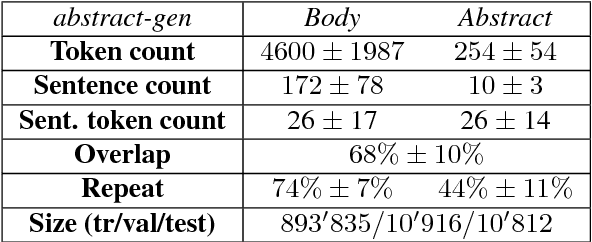
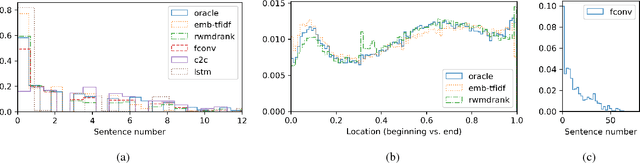
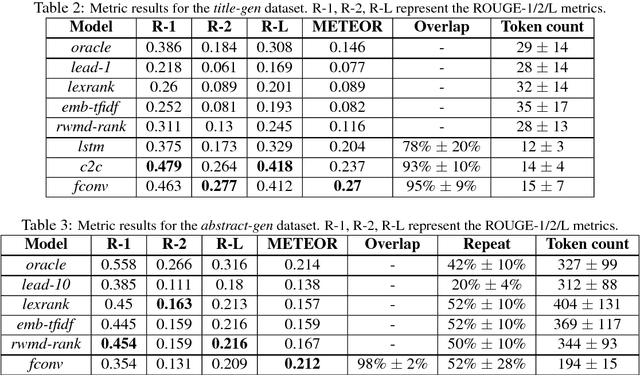
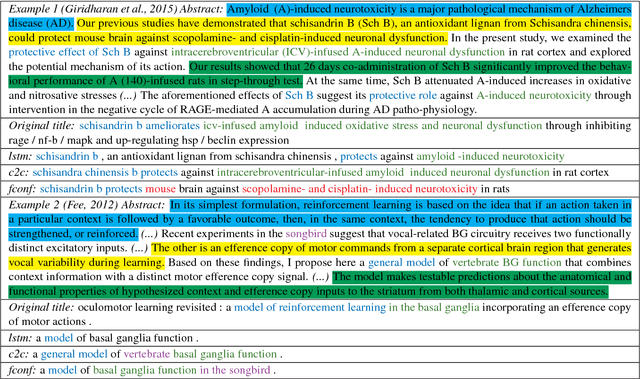
Data-driven approaches to sequence-to-sequence modelling have been successfully applied to short text summarization of news articles. Such models are typically trained on input-summary pairs consisting of only a single or a few sentences, partially due to limited availability of multi-sentence training data. Here, we propose to use scientific articles as a new milestone for text summarization: large-scale training data come almost for free with two types of high-quality summaries at different levels - the title and the abstract. We generate two novel multi-sentence summarization datasets from scientific articles and test the suitability of a wide range of existing extractive and abstractive neural network-based summarization approaches. Our analysis demonstrates that scientific papers are suitable for data-driven text summarization. Our results could serve as valuable benchmarks for scaling sequence-to-sequence models to very long sequences.
Semantic Segmentation of Colon Glands with Deep Convolutional Neural Networks and Total Variation Segmentation
Oct 10, 2017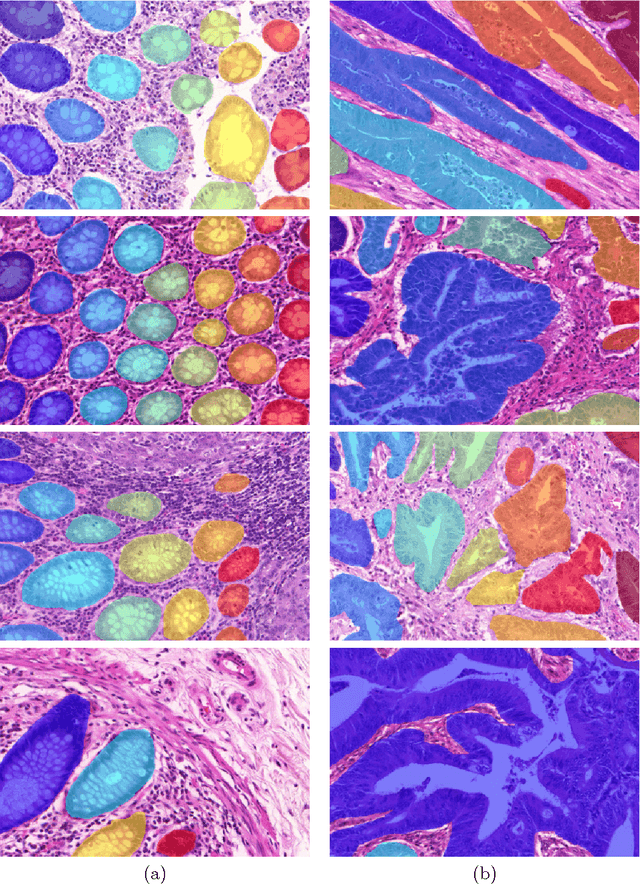
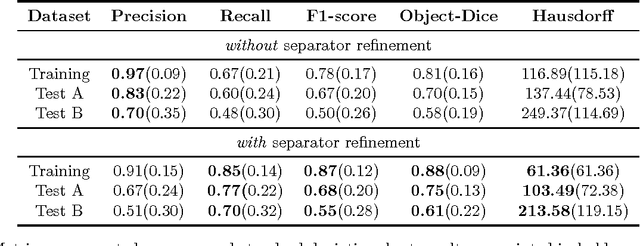

Segmentation of histopathology sections is an ubiquitous requirement in digital pathology and due to the large variability of biological tissue, machine learning techniques have shown superior performance over standard image processing methods. As part of the GlaS@MICCAI2015 colon gland segmentation challenge, we present a learning-based algorithm to segment glands in tissue of benign and malignant colorectal cancer. Images are preprocessed according to the Hematoxylin-Eosin staining protocol and two deep convolutional neural networks (CNN) are trained as pixel classifiers. The CNN predictions are then regularized using a figure-ground segmentation based on weighted total variation to produce the final segmentation result. On two test sets, our approach achieves a tissue classification accuracy of 98% and 94%, making use of the inherent capability of our system to distinguish between benign and malignant tissue.
Theory and Tools for the Conversion of Analog to Spiking Convolutional Neural Networks
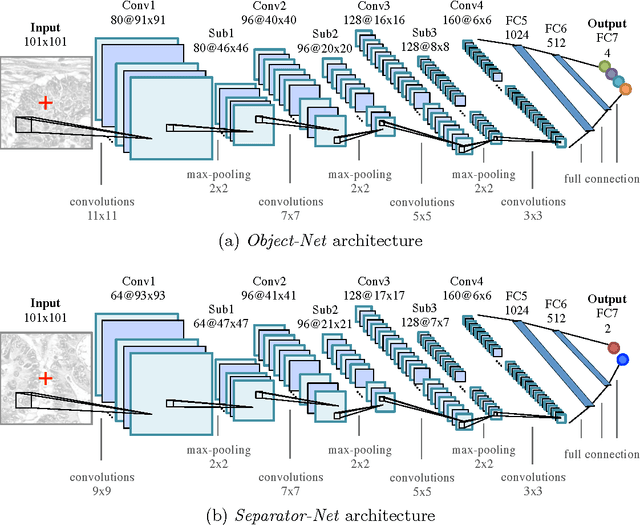
Dec 13, 2016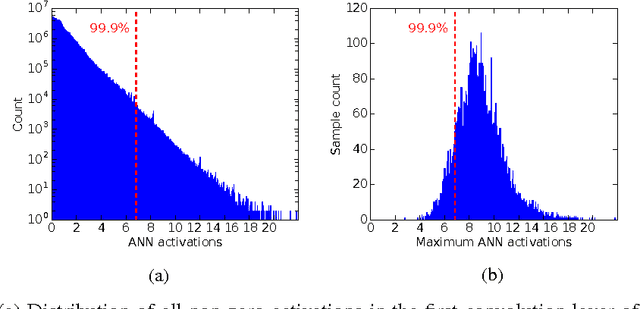

Deep convolutional neural networks (CNNs) have shown great potential for numerous real-world machine learning applications, but performing inference in large CNNs in real-time remains a challenge. We have previously demonstrated that traditional CNNs can be converted into deep spiking neural networks (SNNs), which exhibit similar accuracy while reducing both latency and computational load as a consequence of their data-driven, event-based style of computing. Here we provide a novel theory that explains why this conversion is successful, and derive from it several new tools to convert a larger and more powerful class of deep networks into SNNs. We identify the main sources of approximation errors in previous conversion methods, and propose simple mechanisms to fix these issues. Furthermore, we develop spiking implementations of common CNN operations such as max-pooling, softmax, and batch-normalization, which allow almost loss-less conversion of arbitrary CNN architectures into the spiking domain. Empirical evaluation of different network architectures on the MNIST and CIFAR10 benchmarks leads to the best SNN results reported to date.