 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractions Across Blocks in Post-Training Quantization of Large Language Models
Nov 06, 2024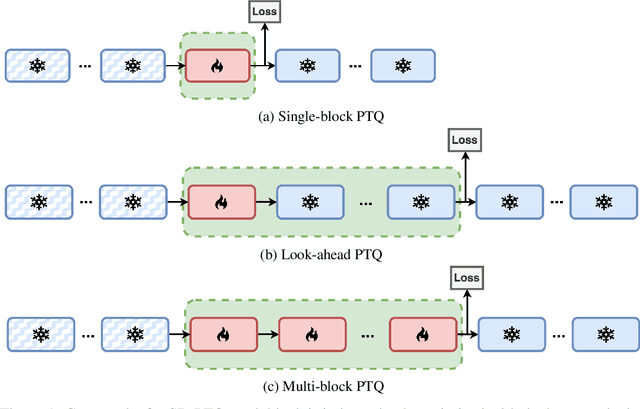
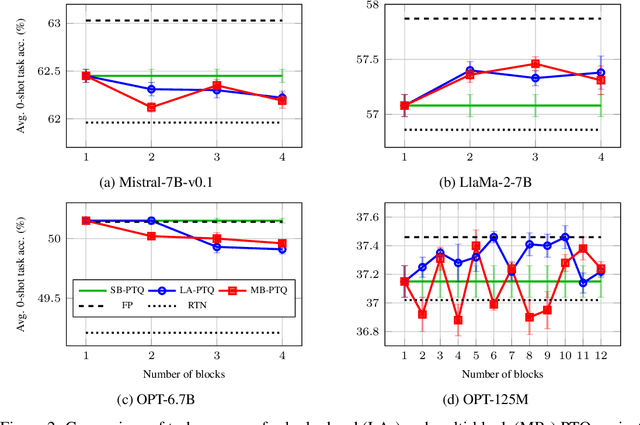
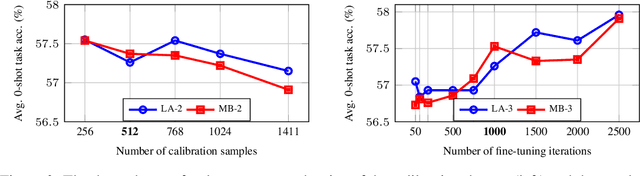

Post-training quantization is widely employed to reduce the computational demands of neural networks. Typically, individual substructures, such as layers or blocks of layers, are quantized with the objective of minimizing quantization errors in their pre-activations by fine-tuning the corresponding weights. Deriving this local objective from the global objective of minimizing task loss involves two key simplifications: assuming substructures are mutually independent and ignoring the knowledge of subsequent substructures as well as the task loss. In this work, we assess the effects of these simplifications on weight-only quantization of large language models. We introduce two multi-block fine-tuning strategies and compare them against the baseline of fine-tuning single transformer blocks. The first captures correlations of weights across blocks by jointly optimizing multiple quantized blocks. The second incorporates knowledge of subsequent blocks by minimizing the error in downstream pre-activations rather than focusing solely on the quantized block. Our findings indicate that the effectiveness of these methods depends on the specific network model, with no impact on some models but demonstrating significant benefits for others.
A Neural Network Subgrid Model of the Early Stages of Planet Formation
Nov 08, 2022

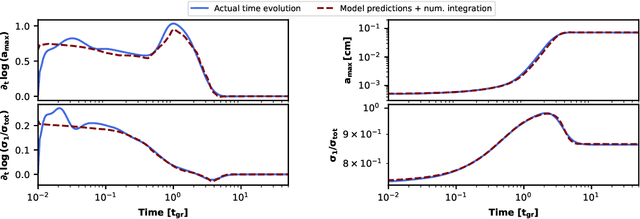

Planet formation is a multi-scale process in which the coagulation of $\mathrm{\mu m}$-sized dust grains in protoplanetary disks is strongly influenced by the hydrodynamic processes on scales of astronomical units ($\approx 1.5\times 10^8 \,\mathrm{km}$). Studies are therefore dependent on subgrid models to emulate the micro physics of dust coagulation on top of a large scale hydrodynamic simulation. Numerical simulations which include the relevant physical effects are complex and computationally expensive. Here, we present a fast and accurate learned effective model for dust coagulation, trained on data from high resolution numerical coagulation simulations. Our model captures details of the dust coagulation process that were so far not tractable with other dust coagulation prescriptions with similar computational efficiency.
Hybrid SNN-ANN: Energy-Efficient Classification and Object Detection for Event-Based Vision
Dec 06, 2021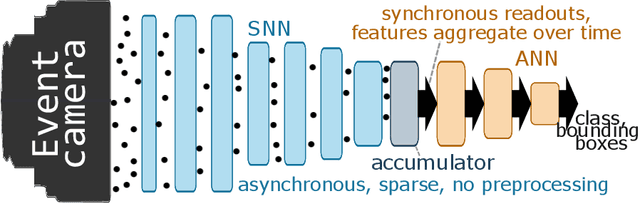
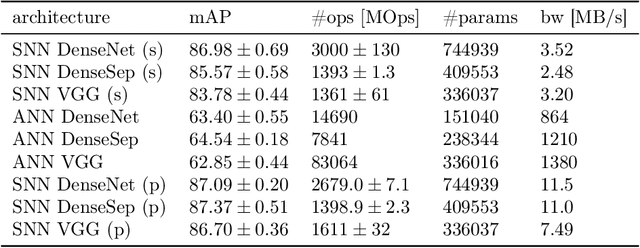
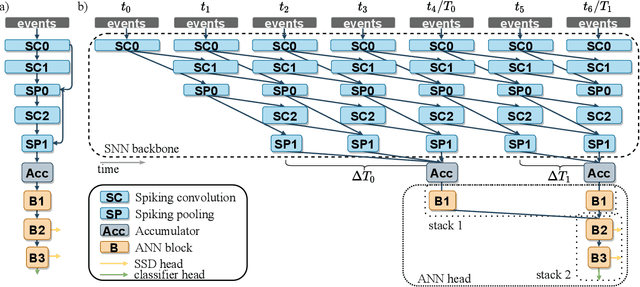
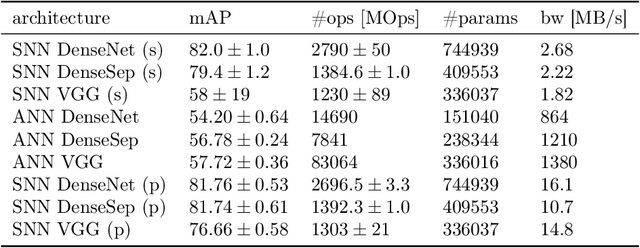
Event-based vision sensors encode local pixel-wise brightness changes in streams of events rather than image frames and yield sparse, energy-efficient encodings of scenes, in addition to low latency, high dynamic range, and lack of motion blur. Recent progress in object recognition from event-based sensors has come from conversions of deep neural networks, trained with backpropagation. However, using these approaches for event streams requires a transformation to a synchronous paradigm, which not only loses computational efficiency, but also misses opportunities to extract spatio-temporal features. In this article we propose a hybrid architecture for end-to-end training of deep neural networks for event-based pattern recognition and object detection, combining a spiking neural network (SNN) backbone for efficient event-based feature extraction, and a subsequent analog neural network (ANN) head to solve synchronous classification and detection tasks. This is achieved by combining standard backpropagation with surrogate gradient training to propagate gradients through the SNN. Hybrid SNN-ANNs can be trained without conversion, and result in highly accurate networks that are substantially more computationally efficient than their ANN counterparts. We demonstrate results on event-based classification and object detection datasets, in which only the architecture of the ANN heads need to be adapted to the tasks, and no conversion of the event-based input is necessary. Since ANNs and SNNs require different hardware paradigms to maximize their efficiency, we envision that SNN backbone and ANN head can be executed on different processing units, and thus analyze the necessary bandwidth to communicate between the two parts. Hybrid networks are promising architectures to further advance machine learning approaches for event-based vision, without having to compromise on efficiency.
SOSP: Efficiently Capturing Global Correlations by Second-Order Structured Pruning
Oct 19, 2021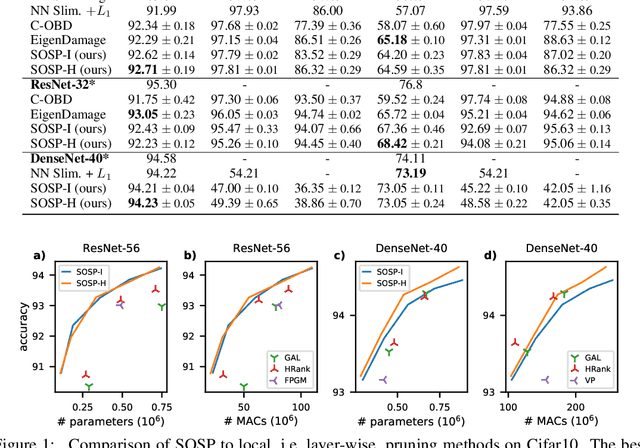
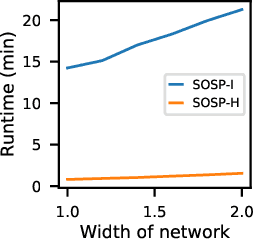
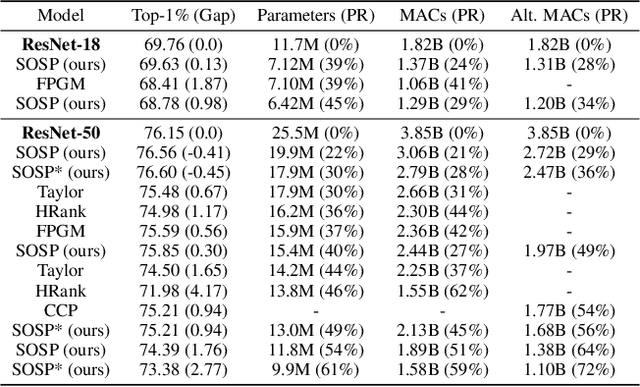
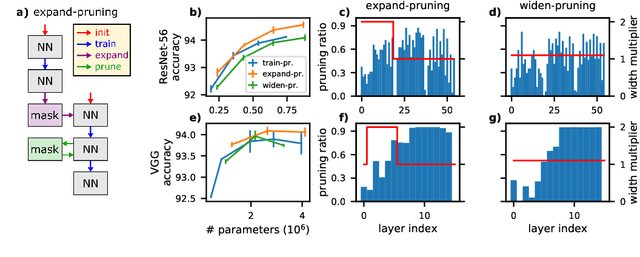
Pruning neural networks reduces inference time and memory costs. On standard hardware, these benefits will be especially prominent if coarse-grained structures, like feature maps, are pruned. We devise two novel saliency-based methods for second-order structured pruning (SOSP) which include correlations among all structures and layers. Our main method SOSP-H employs an innovative second-order approximation, which enables saliency evaluations by fast Hessian-vector products. SOSP-H thereby scales like a first-order method despite taking into account the full Hessian. We validate SOSP-H by comparing it to our second method SOSP-I that uses a well-established Hessian approximation, and to numerous state-of-the-art methods. While SOSP-H performs on par or better in terms of accuracy, it has clear advantages in terms of scalability and efficiency. This allowed us to scale SOSP-H to large-scale vision tasks, even though it captures correlations across all layers of the network. To underscore the global nature of our pruning methods, we evaluate their performance not only by removing structures from a pretrained network, but also by detecting architectural bottlenecks. We show that our algorithms allow to systematically reveal architectural bottlenecks, which we then remove to further increase the accuracy of the networks.
ItNet: iterative neural networks with tiny graphs for accurate and efficient anytime prediction
Jan 21, 2021



Deep neural networks have usually to be compressed and accelerated for their usage in low-power, e.g. mobile, devices. Recently, massively-parallel hardware accelerators were developed that offer high throughput and low latency at low power by utilizing in-memory computation. However, to exploit these benefits the computational graph of a neural network has to fit into the in-computation memory of these hardware systems that is usually rather limited in size. In this study, we introduce a class of network models that have a tiny memory footprint in terms of their computational graphs. To this end, the graph is designed to contain loops by iteratively executing a single network building block. Furthermore, the trade-off between accuracy and latency of these so-called iterative neural networks is improved by adding multiple intermediate outputs both during training and inference. We show state-of-the-art results for semantic segmentation on the CamVid and Cityscapes datasets that are especially demanding in terms of computational resources. In ablation studies, the improvement of network training by intermediate network outputs as well as the trade-off between weight sharing over iterations and the network size are investigated.
The streaming rollout of deep networks - towards fully model-parallel execution
Nov 02, 2018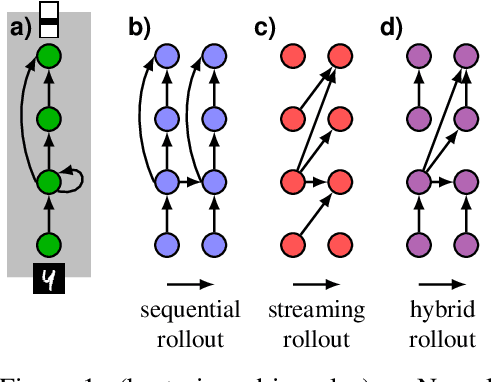
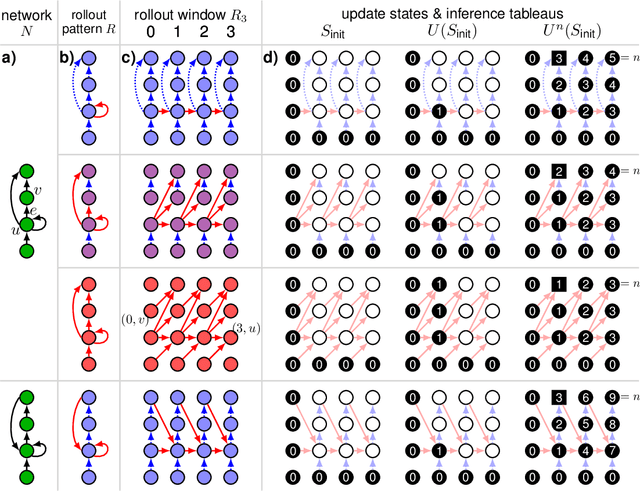
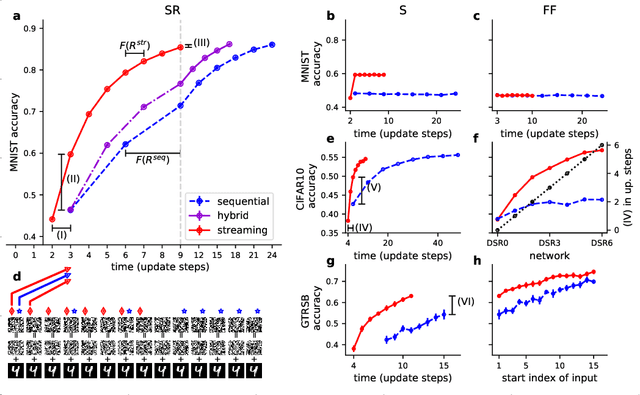
Deep neural networks, and in particular recurrent networks, are promising candidates to control autonomous agents that interact in real-time with the physical world. However, this requires a seamless integration of temporal features into the network's architecture. For the training of and inference with recurrent neural networks, they are usually rolled out over time, and different rollouts exist. Conventionally during inference, the layers of a network are computed in a sequential manner resulting in sparse temporal integration of information and long response times. In this study, we present a theoretical framework to describe rollouts, the level of model-parallelization they induce, and demonstrate differences in solving specific tasks. We prove that certain rollouts, also for networks with only skip and no recurrent connections, enable earlier and more frequent responses, and show empirically that these early responses have better performance. The streaming rollout maximizes these properties and enables a fully parallel execution of the network reducing runtime on massively parallel devices. Finally, we provide an open-source toolbox to design, train, evaluate, and interact with streaming rollouts.
Pattern representation and recognition with accelerated analog neuromorphic systems
Jul 03, 2017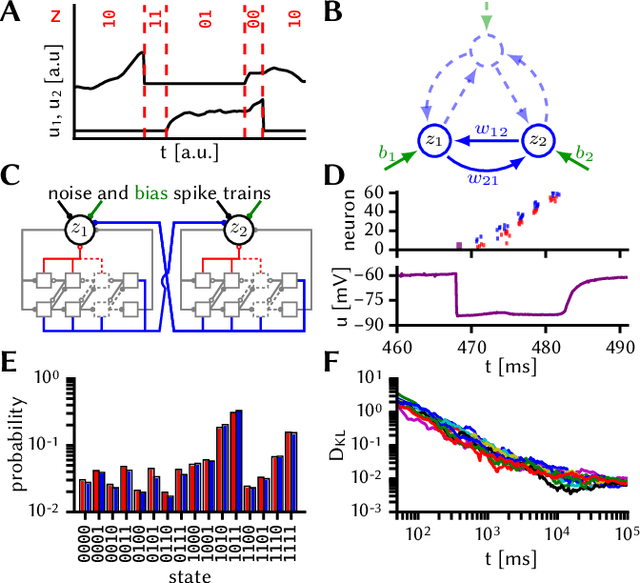

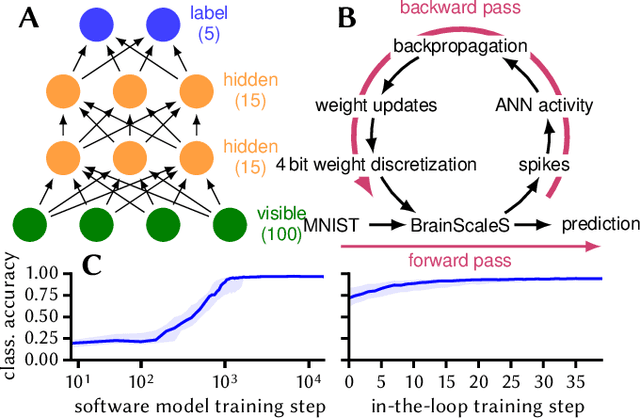
Despite being originally inspired by the central nervous system, artificial neural networks have diverged from their biological archetypes as they have been remodeled to fit particular tasks. In this paper, we review several possibilites to reverse map these architectures to biologically more realistic spiking networks with the aim of emulating them on fast, low-power neuromorphic hardware. Since many of these devices employ analog components, which cannot be perfectly controlled, finding ways to compensate for the resulting effects represents a key challenge. Here, we discuss three different strategies to address this problem: the addition of auxiliary network components for stabilizing activity, the utilization of inherently robust architectures and a training method for hardware-emulated networks that functions without perfect knowledge of the system's dynamics and parameters. For all three scenarios, we corroborate our theoretical considerations with experimental results on accelerated analog neuromorphic platforms.
* accepted at ISCAS 2017